Low latency no longer requires proprietary infrastructure.
Aeron and #QuestDB are part of a growing ecosystem of open technologies being adopted across capital markets.
Link in thread 👇
The AI conversation in finance is moving quickly from copilots to systems that can read papers, implement models, and run backtests.
Interesting discussion at STAC Chicago with experts from Virtu, Attucks, Tenstorrent, Weights & Biases, and #QuestDB.
Most aggregate functions reduce many values to a single result.
array_agg() in #QuestDB takes a different approach, collecting those values into an array within each group or sampled interval.
Link in thread 👇
With storage policies in #QuestDB, data can automatically move to object storage as Parquet.
The same dataset can then be queried from QuestDB, Athena, DuckDB, or any other Parquet-compatible engine. No exports, no copies, no ETL.
Running a regulated futures exchange 24/7 leaves very little room for operational surprises
In our latest case study, One Trading explains why they chose #QuestDB to power market data and analytics for Europe’s first MiFID II-regulated perpetual futures venue
Link in thread 👇
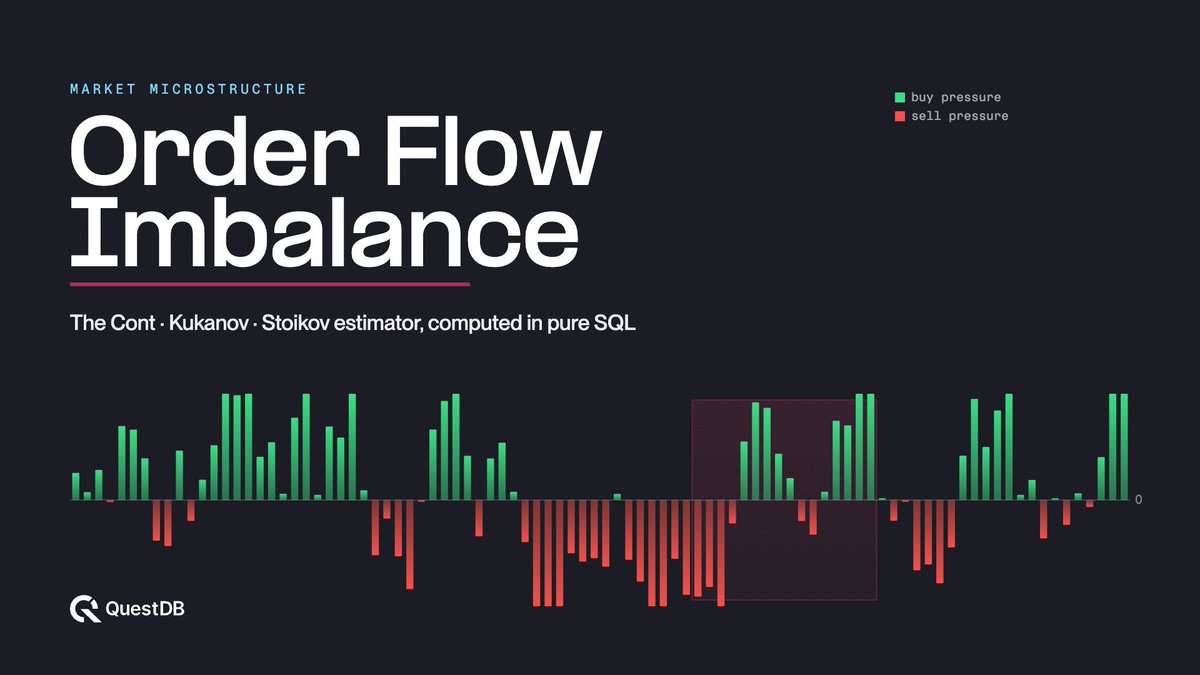
Order Flow Imbalance is one of the most useful microstructure signals, and you can calculate the Cont, Kukanov, and Stoikov formulation directly in SQL with #QuestDB.
You can try the recipe over 2.5M+ core_price rows from yesterday on the public demo instance.
Link in thread
Time-series workloads expose the limits of traditional SQL surprisingly quickly.
Some patterns become verbose. Others become inefficient. Some are simply impossible to express naturally.
We published a new docs page on the SQL extensions in #QuestDB.
Link in thread 👇
Time-series databases prefer ordered data, and #QuestDB is optimized for that fast path.
But delayed events, retries, distributed pipelines, and historical backfilling happen in real systems. Our docs explain how QuestDB handles out-of-order ingestion.
Link in thread 👇
Exactly-once processing can sound intimidating, but it doesn't need to be.
In #QuestDB, you enable deduplication with DEDUP UPSERT KEYS(...) and the database takes care of duplicate retries and replays for you, with very little performance overhead.
Link in thread 👇
Have you tried the new covering indexes in #QuestDB yet?
For highly selective queries on high-cardinality SYMBOL columns, included values are stored contiguously per key, turning scattered reads into sequential scans.
We already support Parquet in #QuestDB through conversion workflows and storage policies.
We are now working on letting tables write future partitions directly as Parquet, giving more flexibility around open-format storage.
With the new MCP we are cooking for #QuestDB, agents can work directly with the Web Console.
Ask for a live dashboard, and it can create SQL notebook charts from your data, OHLC, VWAP, RSI, Bollinger Bands, variables, auto-refresh, ready to customize.
We just shipped #QuestDB 9.4.0.
Highlights include a new posting index for SYMBOL columns (13x smaller, up to 1.5x faster, with INCLUDE covering support), cross-column FILL(PREV) in SAMPLE BY, sparkline()/bar() text charts, and a smarter Web Console.
Link in thread 👇