Shipped Rapid-MLX v0.7.3 — bringing best performance and structured tool calling to DiffusionGemma 26B on Apple Silicon. 🛠️
Engine optimizations pushed throughput to 50 tok/s on an M3 Ultra. Zero parsing headaches. v0.7.3 perfectly handles DiffusionGemma's tool calls natively right out of the box. My new fav local LLM now!
🔗 https://t.co/bxNYbSQb8N
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
SpaceX ($SPCX) isn't a rocket IPO—it's a $1.75T index-inclusion game masking a cash-burning AI bet.
I pulled apart the numbers ahead of Friday's debut. Here is the actual signal through the noise:
1/ The Identity Crisis: Post-xAI merger, it’s a four-headed beast: Launch, Starlink, xAI, and X. The reality? Only Starlink is actually printing money.
2/ The Valuation Void: At $1.75T (~94x sales) with widening losses and zero P/E, there is no fundamental anchor. Fair-value estimates are hallucinating anywhere from $63 to $330.
3/ The Float Mechanics: With only ~4.3% of shares trading freely, month one is completely divorced from fundamentals. It’s a pure liquidity squeeze driven by forced index buying (MSCI, then Nasdaq-100 on Jul 7).
4/ The Bottom Line: You are buying a cash-generative ISP engine strapped to an infinite-spend AI rocket, flying blind on traditional metrics.
Full 4-part teardown in the attached images. 👇
Hyperscalers are pouring nearly $1 trillion into AI infrastructure.
The obvious question is: 🤔 What demand actually justifies $1T of frontier compute?
It’s clearly not chatbots, search, or basic copilots. Those markets are rapidly moving toward the edge and open source. Inference costs keep collapsing (~10x every 12–18 months), and “good enough” AI gets cheaper every year.
The bull case for frontier compute is usually some combination of:
🧬 Drug discovery
🖥️ Chip design
🔬 Scientific/Math research
🧠 Deeper understanding of the universe (SpaceX is here?)
🤖 Physical AI
However, we still have very little evidence that these workloads are generating revenue at a scale that can support a trillion-dollar infrastructure buildout. That’s a scary thought if you’re underwriting the next decade of AI capex.
🤖 AI now makes 100x absurd products than 6mo ago.
When the cost of experimentation collapses, the system starts exploring huge regions of the possibility space that were previously too expensive to touch. Most ideas will fail. Most products will die.
But that’s exactly what happened during the Cambrian Explosion. Nature didn’t become smarter overnight—it simply became able to run far more experiments.
AI is doing the same for startups and products.
What’s becoming scarce is selection. The winners will be those who can spot signal in noise, identify the one great idea among a thousand mediocre ones, and iterate faster than everyone else 🧬
Apple is the true future of decentralization.
The narrative that Apple is "lagging" in the AI arms race completely misses the mark. They aren't failing to compete with hyperscalers—they are executing a profoundly different playbook. 🎯
While the industry forces us to rent intelligence from centralized monoliths (trading our privacy and paying exorbitant token fees 💸), Apple is quietly building the exact opposite:
👤 People-owned AI, running entirely on people-owned devices.
🧠 Core AI (announced in WWDC'26) transforms the device in your pocket from a mere data-harvesting terminal into a sovereign engine of your own intelligence.
🤝 It’s a massive shift: Full Privacy, Low Latency, Zero Token Fees and True AI empowerment isn't a subscription to a distant server. It's local, private, and unequivocally yours
am bullish $APPL (as the developer of rapid-mlx inference engine on MacOS)
I’ve noticed something interesting.
The gap between model capability and model marketing seems to be widening.
As a heavy user, I haven’t seen a meaningful leap since Opus 4.6.
Yet every new release is presented as if AGI has arrived and every profession is about to disappear next quarter.
Maybe we’ve entered a phase where AI progress is linear, but AI storytelling is exponential.
That tends to happen right before very large IPOs
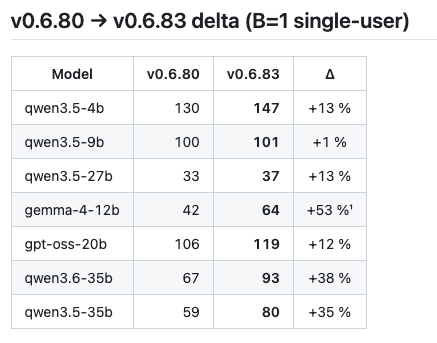
Massive performance leap in rapid-mlx v0.6.83 🚀
We fused the top-p sampler into a single lazy-graph segment, completely bypassing mlx-lm's two-compile closure chain bottleneck.
The result? The entire hero table is up 12-53%, with Gemma-4-12b flying at +53%. Pure edge inference efficiency. 🔥
Cornell's IC3 just dropped the first systematic survey on Crypto x AI. The core insight? AI is the translation layer between humans and machines. Crypto is the trust layer that proves machines actually did what they claimed. 🔗
Where @iotex_io is heading?
At IoTeX, we’re exploring several concrete directions:
- verified real-world data from devices
- GPU compute for batch / latency-insensitive AI workloads
- identity for machines and AI agents
- verifiable AI execution pipelines
- agent payments and onchain settlement
This is why EVM parity, account abstraction, rollups, and cross-chain readiness matter.
Real World AI needs real infra.
🚨 IoTeX Core v2.4.1 "Yap" Hardfork is HERE! 🚨
Full Ethereum Pectra compatibility has officially landed on @iotex_io! ⚡️
What’s dropping at block 48,985,561?
✅ IIP-60 (Pectra EVM): Parity with Ethereum’s latest! Unlocking Account Abstraction (EIP-7702), Rollups, and cross-chain BLS.
✅ Candidate Exit Queue: Safer, predictable validator exits to protect network stability.
💥 A massive leap forward for large-scale DePIN & Real World AI workloads!
🛠 Node Operators: This is a MANDATORY upgrade! (No config changes needed, just restart with the new image).
📘 Full release notes: https://t.co/eyqtu1N1Zt
🔴 The Pain: Running local MLX models is incredibly fast and private. But let's be real - testing tool calling via terminal is clunky, and there's zero good UI for it.
🟢 The Fix: rapid-mlx share
Just ONE command gives you a polished web chat + seamless tool calling (works beautifully with gemma-4-12b-qat). We are proud to be the ONLY MLX inference engine in the community shipping this. ⚡️
👇 Try it now:
brew install raullenchai/rapid-mlx/rapid-mlx
Gemma4 12B is getting a lot of attention right now, so I ran a quick 4-bit inference benchmark on Apple Silicon.
I compared the token generation throughput across rapid-mlx, mlx-lm, Ollama, and LM Studio under 1, 4, and 8 concurrent users. Results are in the image below for those looking to run it locally. 📊👇
The uncomfortable truth: In the short term, AI is an absolute headwind for Crypto. But zoom out, and it’s the greatest long-term catalyst the space has ever seen👇
🩸 The Short-Term Bear Case
1️⃣ The Attention Black Hole: The AI wealth-creation myth has completely hijacked the global narrative. It is aggressively siphoning mindshare, developer talent, and liquidity. Crypto is experiencing a sustained capital drain as both retail and institutional money chase the AI gold rush.
2️⃣ The Security & Quantum Threat: AI poses a dual existential threat to decentralized networks. Not only are AI agents becoming ruthlessly efficient at finding and exploiting code vulnerabilities, but AI is also radically accelerating the timeline for quantum computing—posing a looming threat to the underlying cryptographic security and efficiency of the entire space. This drives massive on-chain capital flight.
3️⃣ An Ideological Shift: This isn't just about hacks; it's a fundamental shift in trust. Driven by the fear of decentralized vulnerabilities, users and capital are retreating to the perceived safety of centralized systems. This ideological pivot is the core reason for the short-term price suppression.
🚀 The Mid-to-Long Term Bull Case
The mid-to-long term isn't just a recovery; it’s a total metamorphosis.
1️⃣ Open, decentralized platforms are the only infrastructure neutral and permissionless enough to host a civilization of billions of autonomous AI agents. These agents will perform quadrillions of experiments, crowdsource innovation, and iterate at machine speed—all on-chain, beyond the reach of a central kill-switch.
2️⃣ We aren't just building a financial system; we are building the substrate for an explosion of Global Intellectual Wealth.
3️⃣The End Game? We are so early that we can’t even catch a glimpse of it yet. We are moving past the era of "speculative toys" and into the "Synthetic Intelligence Layer" of humanity.
Just my 2cents
BREAKING: MicroStrategy's, $MSTR, unrealized loss on its Bitcoin holdings rises to a record -$12.7 billion.
This puts the company's position down -$28 billion over the last 12 months.
Gemma 4 dropped a 12B.
I put it on RTX 5090 against its 31B sibling.
when you cut a model from 31B to 12B, what do you actually lose?
~ reasoning barely moves
GSM8K (math) 97.5 > 96.4 (−1.1)
ARC-C (sci reasoning) 97.6 > 94.0 (−3.6)
~ knowledge falls off a cliff
MMLU (world knowledge) 87.8 > 78.9 (−8.9)
HellaSwag (commonsense) 92.0 > 81.6 (−10.4)
~~~
parameters store facts, not thinking. the 19B you delete is mostly where the model kept its trivia and world-priors, cut it and recall collapses, while the reasoning machinery stays nearly whole.
a 12B reasons almost like its big brother. It just knows less.
122 tok/s vs 53 (2.3x faster generation), ~10GB instead of ~24, meaning that you get 20GB+ free on a 32GB card for long context or a second model.
so it depends of your workload:
reasoning / math / agentic loops = the 12B is nearly free
broad-knowledge Q&A with no retrieval = that's the one job worth paying for the 31B.
Google just dropped a beast: Gemma 4 12B. (78.8% GPQA, 256K context, multimodal, Apache 2.0) 🔥
Don't waste time on complex setups. If you're on Apple Silicon, Rapid-MLX shipped day-zero support so you can run it locally right now⚡️
Zero config, just run 💻
brew install raullenchai/rapid-mlx/rapid-mlx
rapid-mlx chat gemma-4-12b
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇