3) Using model weight averaging (Izmailov et al., 2018) consistently provides a boost in robustness. In fact, weight averaging provides improvements as large as those provided by TRADES.
4) Tuning the mixing of additional unlabeled data (from Carmon et al., 2019) also helps.(4/4)
1) Combining TRADES (Zhang et al., 2019) with early stopping is superior to classical adversarial training (Madry et al., 2017; Rice et al., 2020)
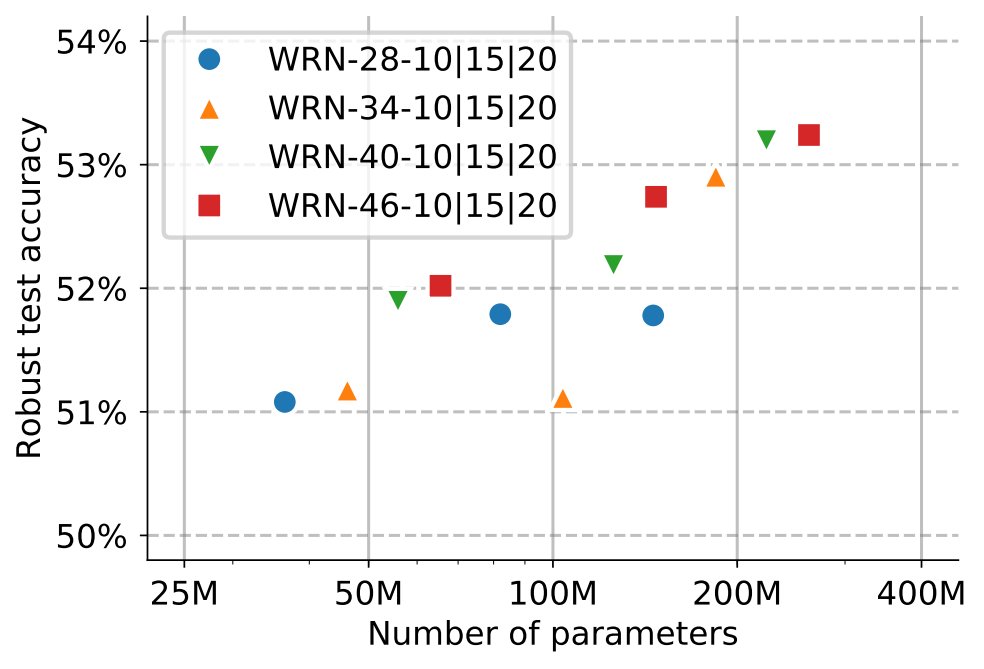
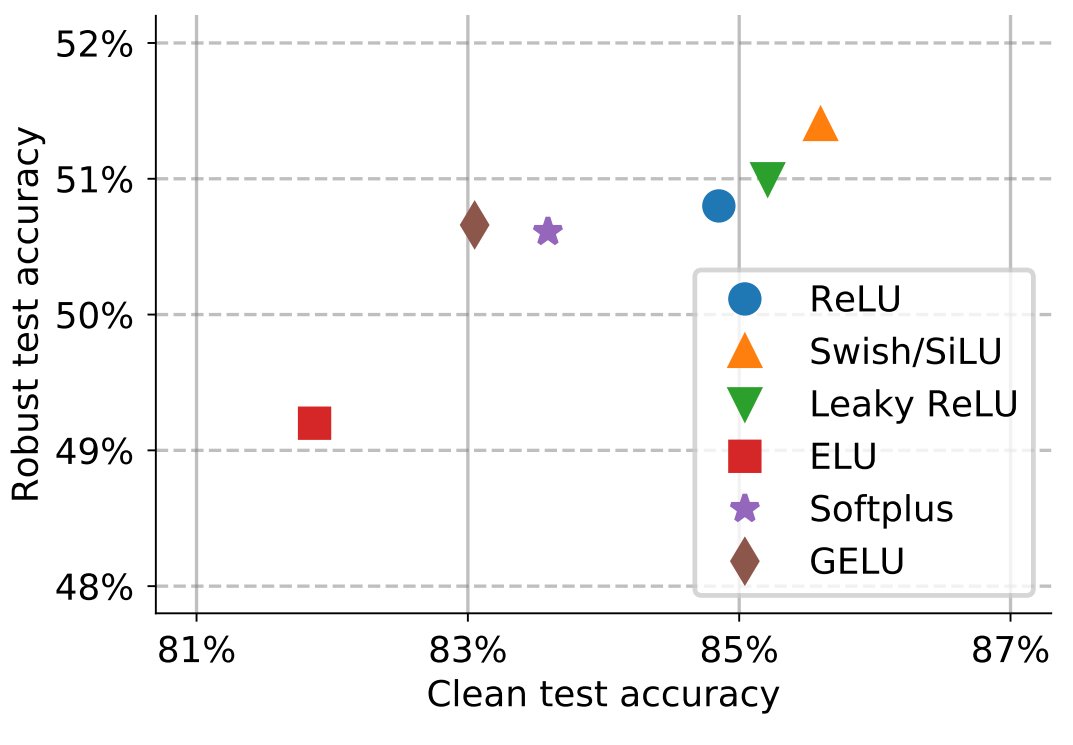
2) Larger models and using SiLU/Swish provide improvements in clean and robust accuracy (both phenomena were already observed). (3/4)
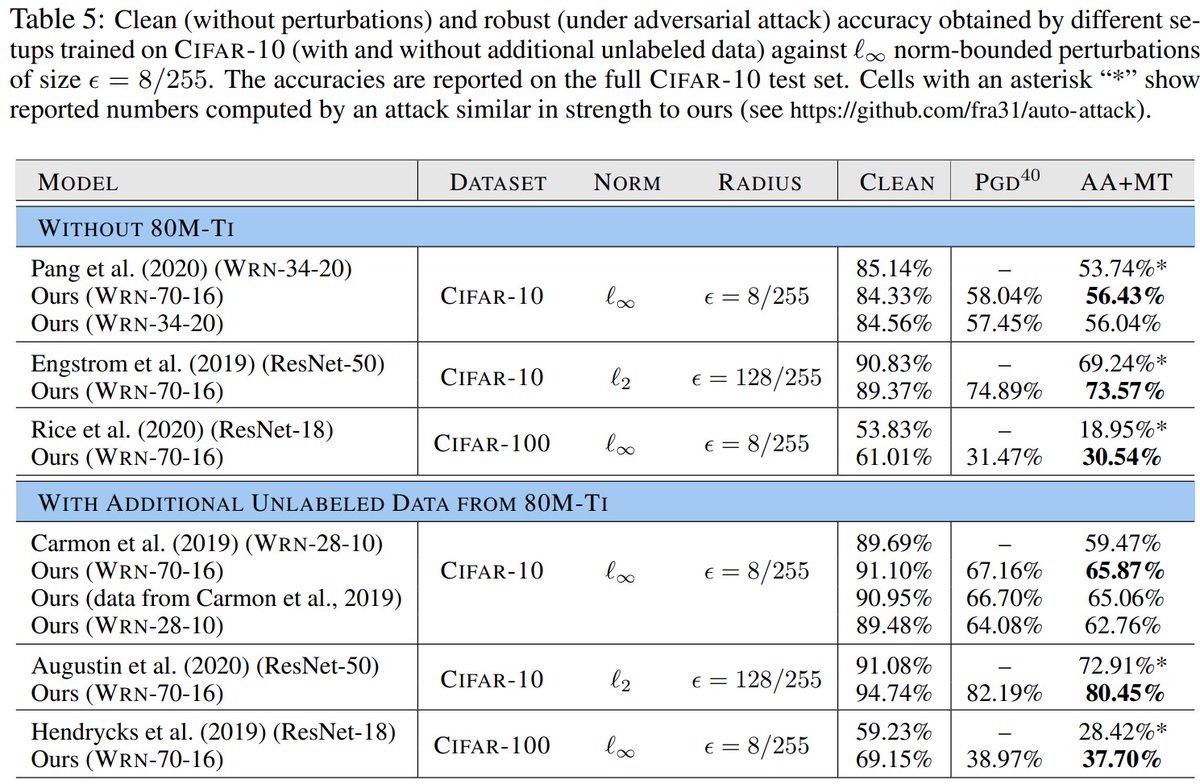
Our findings generalize to other datasets (e.g., CIFAR-100) and other norms (e.g., L2). With additional data, we surpass the previous state-of-the-art by 6.34%. Without additional data, we improve on the results of 3 state-of-the-art methods that leveraged additional data. (2/4)
Have you ever wondered how to reach 65% robust accuracy on CIFAR-10 (against l-infinity norm-bounded adversaries of size 8/255)?
In collaboration with Chongli Qin, @JonathanUesato, @realKingTim and @pushmeet, we are releasing our recipe at https://t.co/PGJ0fgsO6K. (1/4)
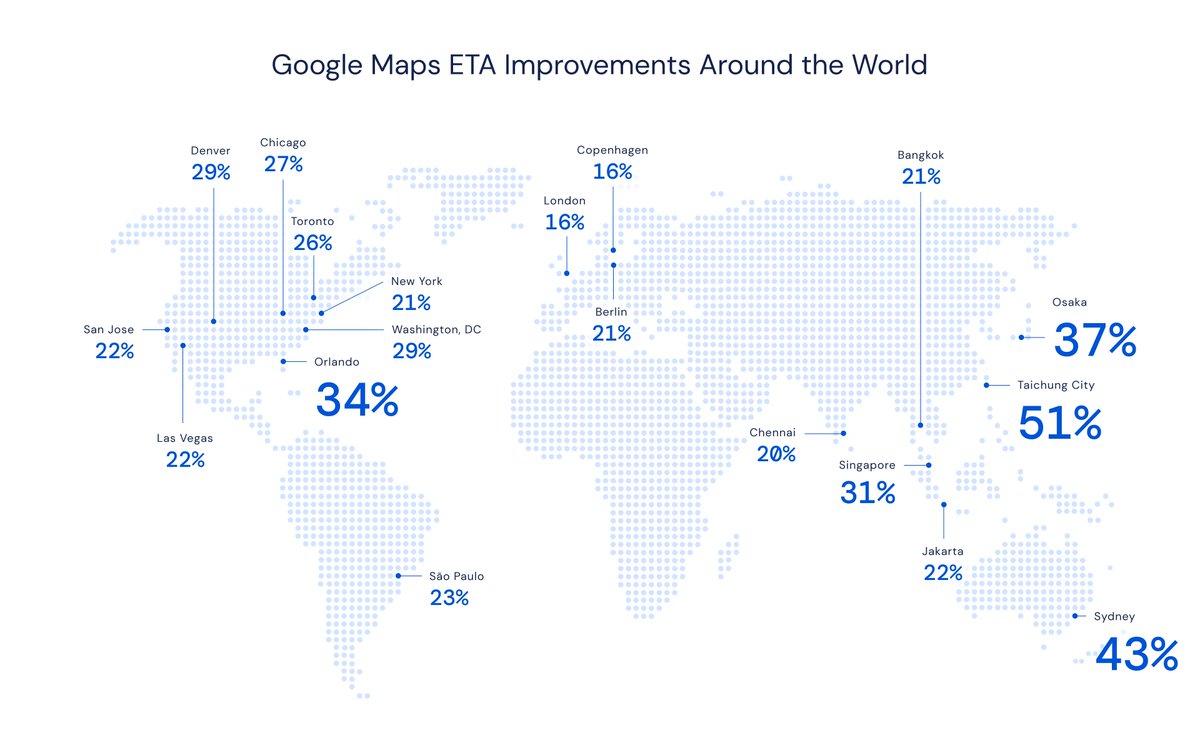
Exciting results from our partnership with @googlemaps! Using advanced Graph Neural Networks we were able to improve the accuracy of ETAs in major cities across the world by up to 50% https://t.co/ZOzy7AlBuX
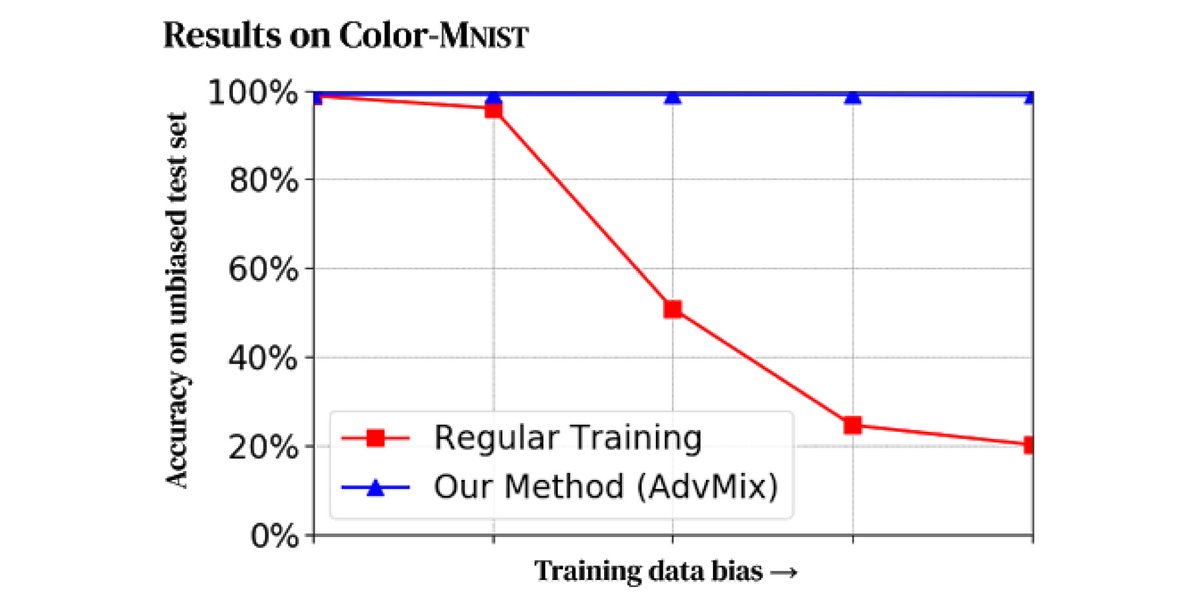
Training data is often collected through a biased process. Models trained on such data are inherently biased. We demonstrate how adversarial training through disentangled representations can reduce the effect of spurious correlations present in datasets: https://t.co/wgdJwChIJV