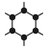
Create an XFS filesystem of a particular size, smaller than the device:
mkfs.xfs -d size=50g /dev/sdx1
There's (count them) nine different size= options for mkfs.xfs...
Most teams don't get killed by a Kubernetes outage. They get killed by the bill.
Here is where the money actually leaks:
- Cluster autoscaler scales up under load and never scales back down, so idle nodes burn cash all day
- No resource requests set, so the scheduler can't bin-pack and you pay for nodes running a third empty
- A LoadBalancer service per app instead of one shared ingress, multiplying cloud LB charges with every deploy
- On-demand nodes running workloads that would sit happily on spot at a fraction of the price
- Pods chatting across availability zones, racking up cross-AZ transfer fees nobody put on a dashboard
- Persistent volumes orphaned when pods die, so you keep paying for disks attached to nothing
- Logs and metrics shipped at full firehose to a vendor that bills per gigabyte ingested
- Dev and staging clusters left running 24/7 for workloads used six hours a day
Every one of these is invisible day to day. None of them trip an alert. They just compound silently and show up at month end, where they get written off as "cloud is expensive" instead of "we never tuned the cluster."
The infrastructure isn't the problem. The defaults are, and nobody owns them.
Just discovered that curl has a --json flag. Instead of:
curl-X POST -H 'Content-Type: application/json' -d '{...}' <url>
you can write
curl --json '{...}' <url>
A DEVELOPER PROVED THE REGEX YOU'VE WRITTEN A THOUSAND TIMES IS SECRETLY A COMPILER AND THAT ALMOST NO ONE WHO USES THEM HAS ANY IDEA WHAT ACTUALLY RUNS
36 minutes from Paul Wankadia, the engineer behind a regex engine that compiles your pattern straight down to raw machine code -- walking through what really happens between the slashes.
-> The moment it clicks, regex stops being magic punctuation you paste from Stack Overflow and becomes what it actually is: a tiny machine. Your pattern gets turned into a state machine, and that machine is what runs against every character of your text.
That one idea explains everything you never understood. Why one regex returns instantly and a nearly identical one hangs your whole server. Why some patterns are safe and others are a denial-of-service waiting to happen. It was never random -- it's whether the machine underneath is built well or badly.
Writing a regex was never the skill -> reading one is. And now that an AI agent hands you dense, clever patterns you'd never write yourself, the person who can see the machine underneath is the one who catches the one that takes down production at 3am.
Everyone copies regex and prays. This is the talk that ends the praying.
Save it. The next time a pattern "Just works," you'll actually know why ↓
Governments delete webpages. Agencies scrub reports. Politicians' statements vanish from official sites the week they become inconvenient.
It happens in every country, under every party, and it works because nobody kept a copy.
ArchiveBox makes keeping a copy trivial.
It's a self-hosted archiver built for exactly this. Point it at the pages that matter and it freezes them:
→ Timestamped screenshots and PDFs
→ Raw HTML and HTTP headers
→ WARC files that replay the page as it was
→ Scheduled re-captures, so you have a record of every version over time
Run it on a schedule against government portals, news sites, or any source you expect to change quietly. Each snapshot lands in a plain folder with JSON metadata.
The Wayback Machine can't watch everything, and it can be pressured, sued, or blocked.
A thousand people each archiving what they care about cannot be.
History gets rewritten by whoever controls the record. This puts a copy of the record on your disk.
27.6K stars. MIT License. 100% Opensource.
https://t.co/rm2wEUphQG
@skcd42 I've noticed that it forgets the newline at the end of the last line of each new file it creates. Not sure if it's the model or the harness causing it. I was using the composer model today when I noticed it happen on two different sessions.
🚨 TL;DR: Attackers are sending fake Sentry bug alerts to projects using public Sentry DSNs. The fake alert is designed to trick AI agents into running a malicious `npx` command that looks like a Sentry profiling diagnostic.
Do NOT run commands from Sentry issues/logs/alerts unless verified.
These are not legitimate Sentry fix commands. The malicious package reportedly steals environment variables/secrets and sends them to advisory-tracker[.]com.
Bug fixes shipping to Grok Build 0.2.20 (release notes will be available in the TUI and on change-log website)
• Eliminate ghost-cell artifacts in markdown table rendering
• Make monitors visible and killable to the model
• Preserve soft breaks in plan preview
• Add image_to_video and reference_to_video tools
• Add bundled imagine skill
• Convert ICO images to PNG
• Resolve [Image # N] attachment references in image_edit
• Open fullscreen viewer on Enter for Search and ListDir blocks
• Route MCP lifecycle notifications by sessionId + bound per-server init
• Route mouse-wheel scroll to /btw overlay panel
• Compaction: neutralize echoed summarization instruction in summary seed
• Structured compaction prompt (successor-assistant, carry-forward, <analysis>
block)
• Dedupe between-turn subagent completion reminders
• Allow auto-update to downgrade on rollback
• Dedupe MCP servers declared in both .mcp.json and plugin.json
• Fix local stdio MCP servers on Windows
My productivity still hasn’t recovered from the hit it took when Anthropic instituted rate limits on Claude Code a couple of months ago.
Note that I’m NOT talking about usage limits here, but the rate limit on the number of requests during a given time interval.
It used to be that Codex was the one with rate limits, but I could have 20 CCs running at the same time on one machine with no problem.
And sure, it would eat my entire 5-hour usage limit in 20 or 30 minutes. But I can budget for that and it let me move a lot faster.
But now I’m scared to start up more than 2 or 3 CC instances at once on a single machine. Since subagents also seem to count against the limits too, it’s very easy to trigger it.
And when you do, it’s catastrophic because it nukes ALL your CC sessions at the same time, the worst possible failure mode.
Why not just fail the new request to keep the damage contained? It feels punitive.
A far better way would be to have a local request queue that operates globally on a machine.
If the next CC request would have triggered the rate limit, then that request is placed in a queue, to be executed in order when it wouldn’t run afoul of the rate limit.
That way it seems to each agent instance like a slow request rather than a catastrophic failure. But it has the same net effect on limiting the overall number of requests per minute.
microservices solved an org chart problem and everyone decided it was a technical insight.
amazon and netflix didn't break into services because it was the right architecture. they did
it because thousands of engineers can't merge into the same repo on the same day without everything catching fire.
your startup with 12 engineers and 40 services didn't adopt a pattern. it adopted the symptoms without the disease that made them necessary.
I’ve had it happen twice now where Claude was unbelievable, persistently convincing that something was the root cause of an issue.
To the point that I proudly shared it with the team investigating.
Only to find out later that it was 100% wrong.
Had it taken action on the hypothesis, it would have made things way worse.
But as it stands it was just a giant waste of time.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
On iOS and macOS, WhatsApp stores chat databases unencrypted in an app group container accessible to apps from the same developer. So all Meta apps on the same iPhone (e.g., Facebook) can read WA chats in plaintext without permission, and users wouldn't be notified. Demo👇
First-sale doctrine is one of the oldest property rights in the common law. You buy a book, it is yours. Lend it, resell it, will it to your kids, burn it in the yard, keep it for fifty years. The seller loses all say the moment money changes hands.
Federal law flipped that on its head for anything digital. Every ebook you buy ships wrapped in a lock, and DMCA Section 1201 makes breaking that lock a crime, even on books you paid for.
The state did not simply fail to protect your property. The state wrote the statute that criminalizes defending it.
Let people own what they buy.
Announcing reposurgeon release 5.7
Your system package manager probably knows this as 'reposurgeon'
A tool for editing version-control repository history.
reposurgeon enables risky operations that version-control systems don't want to let you do, such as editing past comments and metadata and removing commits. It works with any version control system that can export and import git fast-import streams, including git, hg, fossil, bzr, brz, darcs, mtn, bk, and RCS. There is import-only support for svn, CVS, and SCCS. In particular this tool can be used to script the production of very high-quality conversions from Subversion to any VCS with write support.
New in this release:
Documentation polishing.
Build recipe cleanup.
Forward-port to Kommandant 0.7.0
Housekeeping release. No new feattures or bugfixes, just keeping current with Kommandant.
https://t.co/6Cy3rzsq2j
A fresh install of GrapheneOS has far lower idle power usage than the stock Pixel OS. Power usage while active is comparable. Making a similar setup to the stock Pixel OS by installing sandboxed Google Play and a couple dozen apps doing a bit of background work will result in similar battery life.
GrapheneOS doesn't come doesn't come with anything keeping open a push connection and barely has any scheduled work. Waking every 8 hours for update checks doesn't use significant power. It doesn't have better battery life due to any major efficiency improvements but rather the lack of bloatware.
Installing sandboxed Google Play on GrapheneOS results in having a push connection for Firebase Cloud Messaging and doing a lot more work in the background. Idle power usage will still tend to be better than the stock Pixel OS, but adding more apps to match their bloatware will make it comparable.
Battery life heavily varies based on apps, networks and OS configuration. Many people end up with far better battery life on GrapheneOS and many people end up with far worse battery life due to differences in how they set up their devices. It's easy to end up with either result with simple choices.
Play Store policy coerces apps into using Firebase Cloud Messaging for push messaging including push notifications. Having every app sharing the same push connection is very efficient. Multiple push connections are inherently less efficient and many implementations of this aren't power efficient.
Installing Signal in a profile without sandboxed Google Play and granting the power optimization exception it requests is enough to destroy battery life and end up worse than the stock Pixel OS. The power efficient choices are either using Molly with UnifiedPush (Signal fork) or Signal with FCM.
Running both sandboxed Google Play and an efficient UnifiedPush app can have competitive battery life with the stock Pixel OS. Those should be the only 1-2 battery optimization exceptions for most users. Signal's fallback push will drain more power than all the bloatware in the stock OS itself.
On a Google Mobile Services OS, Play services is built into the OS as a highly privileged component with immense access and handles work across profiles.
Sandboxed Google Play are regular sandboxed apps without any special access. Each installation in a separate profile is entirely independent.
Setting up a work profile, Private Space and secondary user on the stock Pixel OS results in all 3 secondary profiles using the global Play services instance running in the Owner user for a shared FCM push connection, etc. Installing sandboxed Google Play in 4 profiles would run 4 FCM connections.
Network-based location is much more power efficient than the power hungry GNSS radio for satellite-based location. Maps/navigation apps will continuously use both when available but many apps will avoid using GNSS to save power if network-based location is available, so it can save a lot of power.
For GrapheneOS, network-based location is an opt-in feature in the Owner user setup. For Google Mobile Services Android, it's opt-out there and you'll be regularly nagged to enable it if you didn't. It's a common pitfall since people expect indoor location positioning and it can save a bit of power.
Cellular, Wi-Fi and Bluetooth are power hungry. 5G is particularly power hungry prior to the improved cellular radio in 9th/10th gen Pixels with the exception of the Pixel 9a. Either way, setting the cellular mode to 4G (meaning 4G and below) or the GrapheneOS 4G-only mode can save a lot of power.
Stock Pixel OS has an Adaptive Connectivity service which largely keeps 5G disabled. GrapheneOS doesn't have an equivalent to this yet but you can do it manually. Other than that, the stock Pixel OS doesn't really have any significant power saving tricks and it has a lot of bloatware draining power.
@mackenzieprice If it takes more than an hour to finish a lesson, such as with some of the science lessons, you can get to the end and have it not register your completion and have to click thru the lesson again due to a session timeout. Overall, it's very high friction
@mackenzieprice Most parts of the lessons have "read to me" but the voice is an awful robotic one that's very hard to focus on.
You can't go back within a lesson, but if your session times out or browser crashes, you're forced to start the lesson over again.