Dynamic workflow orchestration works pretty good now that 4.8 in claude code is more stable. It feels similar to my planning and tmux+hook orchestration workflow plugin I've been using for the past 5 months for development.
My claude code planning flow is:
- ideation session with heavy use of AskUserQuestion to produce IDEAS.md
- IDEAS.md is used to produce detailed PLAN.md grounded in source
- more AskUserQuestion grilling to refine plan
- adversarial plan review by Codex to identify gaps and issues
- address issues in plan until it is solid
- decompose plan into separate PHASE_#.md docs
- additional codex review each phase doc for accuracy
Phase docs are strictly sized to be implemented by a fresh agent before hitting 200k context, if the phase is too big, it is split into sub-phases.
Might be a bit overkill, but the planning paper trail and success criteria of each phase drastically reduces the amount of post-implementation clean up.
After all planning docs are complete, I would use an orchestrator agent to spawn phase executor agents via tmux with hooks to produce completion signal files for the orchestrator to know to spawn the next agent. Essentially a fancy ralph-loop that allowed me to run agents overnight.
Using my same ideation/planning/phase-decomposing process with dynamic workflows is working great so far, without the need for tmux orchestration anymore.
Tonight I'll push it further and see how well it does with a major frontend redesign consisting of roughly 150 phase plan docs.
Started using Codex for adversarial review of Claude's work in March, then 5.5 was released late April, and now Codex handles almost everything.
Crazy to see I had a few 1B+ token days.
@theo Yeah it can’t be trusted right now. Sub-agents failing, parallel tool calls failing, and weird hallucination loops from the failed calls that burn through tokens fast. No idea how this release passed testing and dogfooding.
Wtf is happening with claude... 2.1.156 fixed corrupted conversations and was working fine, then 2.1.157 introduced new bugs.
Now sub-agents are going blind, not seeing tool call results, start reality checking with bash tests and then end up in a weird loop. Repeatedly reading files, then bash testing tool calls start again before more repeated file reads.
500k tokens burned in 5 mins. I spawn another sub-agent to see if it happens again, same thing, another 400k tokens in a few minutes...
Instead of continually adding more slop feature bloat to claude code, how about you stabilize the core harness? Or better yet, just let us use our subscription with a harness that is reliable and actually works instead of forcing us to use this unstable harness... @ClaudeDevs@claudeai@bcherny@trq212
Now I completely understand why @badlogicgames built https://t.co/CWfBoFhhrv
@_can1357 That’s brutal. I thought it was a harness or streaming protocol issue. Seems very odd to me that they don’t have test coverage around parallel tool calls to catch this kind of thing before releasing.
Wtf is happening with claude... 2.1.156 fixed corrupted conversations and was working fine, then 2.1.157 introduced new bugs.
Now sub-agents are going blind, not seeing tool call results, start reality checking with bash tests and then end up in a weird loop. Repeatedly reading files, then bash testing tool calls start again before more repeated file reads.
500k tokens burned in 5 mins. I spawn another sub-agent to see if it happens again, same thing, another 400k tokens in a few minutes...
Instead of continually adding more slop feature bloat to claude code, how about you stabilize the core harness? Or better yet, just let us use our subscription with a harness that is reliable and actually works instead of forcing us to use this unstable harness... @ClaudeDevs@claudeai@bcherny@trq212
Now I completely understand why @badlogicgames built https://t.co/CWfBoFhhrv
Just had to switch back to Opus 4.7 after 4.8 kept getting locked in "liveliness checks" after failing to understand empty Bash outputs and burned 100k tokens on cancelled parallel tool calls.
Super bummed.... 😮💨
Tbh I'm close to switching back to Cursor and off my CC sub.
Is it just me or is Opus 4.8 in CC sometimes just absolutely retarded?
In this session it just got stuck in a loop calling "echo" and checking the date 20x times in a row... This has been happening very regularly since the 4.7 --> 4.8 update. WTF?
@claudeai@bcherny
gave claude 4.8 another try at ultra xhigh. It failed to one-shot a relatively simple task - read a lot of existing code and create a new script from it. It spent 14% of my limits hallucinating - trying to read files that didn't exist, before admitting it should've run "ls" first
Claude Code completely broken after the last two patches?
----
From Claude:
What I actually observed: several times this session, when I ran a tool call (a Bash command or an
Edit), the result block I got back appeared to belong to a previous call, or showed stale file
contents, or an Edit reported "success"/"file not found" in a way that didn't match what the file
actually contained a moment later. So my model of the file's state drifted from its real state.
Wtf is happening with claude... 2.1.156 fixed corrupted conversations and was working fine, then 2.1.157 introduced new bugs.
Now sub-agents are going blind, not seeing tool call results, start reality checking with bash tests and then end up in a weird loop. Repeatedly reading files, then bash testing tool calls start again before more repeated file reads.
500k tokens burned in 5 mins. I spawn another sub-agent to see if it happens again, same thing, another 400k tokens in a few minutes...
Instead of continually adding more slop feature bloat to claude code, how about you stabilize the core harness? Or better yet, just let us use our subscription with a harness that is reliable and actually works instead of forcing us to use this unstable harness... @ClaudeDevs@claudeai@bcherny@trq212
Now I completely understand why @badlogicgames built https://t.co/CWfBoFhhrv
Wtf is happening with claude... 2.1.156 fixed corrupted conversations and was working fine, then 2.1.157 introduced new bugs.
Now sub-agents are going blind, not seeing tool call results, start reality checking with bash tests and then end up in a weird loop. Repeatedly reading files, then bash testing tool calls start again before more repeated file reads.
500k tokens burned in 5 mins. I spawn another sub-agent to see if it happens again, same thing, another 400k tokens in a few minutes...
Instead of continually adding more slop feature bloat to claude code, how about you stabilize the core harness? Or better yet, just let us use our subscription with a harness that is reliable and actually works instead of forcing us to use this unstable harness... @ClaudeDevs@claudeai@bcherny@trq212
Now I completely understand why @badlogicgames built https://t.co/CWfBoFhhrv
Given access to recent LLMs, the number of things you could be doing explodes. Choosing how to spend your time has never been more important both technically and personally. Building because you can is seductive and it compounds with inexperience. It looks like addiction to me.
@Javi Improved reliability with loading long history threads. I get errors loading messages: CodexAppServer.CodexClientError error 11
Other than that, it works great, thanks for all the hard work!
@steventseeley@HackingDave Ended up being a harness/protocol issue and not the model. Its fixed in latest 2.1.156 update and 4.8 has been running great so far. Still seeing intermittent cyber use blocks with 4.8 for CVP approved teams though
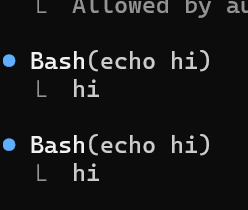
Before this happened, claude was re-running commands like "echo hello world" and claiming plan docs were corrupt. Then eventually started failing with this 400 error when I stopped it and asked what was going on.
Analyzing the session transcript, it looks like the agent loop failed to end the assistant turn between tool calls. One message accumulated 40 tool_use + 19 signed thinking blocks instead of ~20 separate turns. Tool results stopped feeding back, so the model went blind and started reality checking with "echo test123" and claiming files were corrupt.
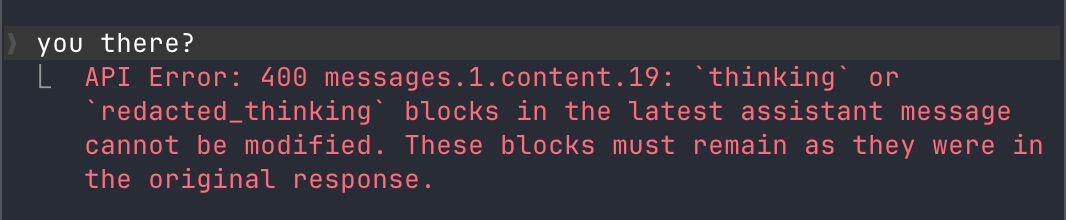
Since the single malformed message had signed and immutable thinking blocks, reconstructing the request modifies a thinking block and leads to the 400 API errors on every subsequent turn. The whole conversation is permanently bricked, not just one reply.
You can manually recover by having a fresh claude parse the session transcript and pick up where they left off, but it sucks having to waste tokens to recover a session because the harness is buggy.
@bcherny@ClaudeDevs I'm sure you all are already looking into this, but it looks like the root cause is a streaming/turn-boundary bug.
Before this happened, claude was re-running commands like "echo hello world" and claiming plan docs were corrupt. Then eventually started failing with this 400 error when I stopped it and asked what was going on.
Analyzing the session transcript, it looks like the agent loop failed to end the assistant turn between tool calls. One message accumulated 40 tool_use + 19 signed thinking blocks instead of ~20 separate turns. Tool results stopped feeding back, so the model went blind and started reality checking with "echo test123" and claiming files were corrupt.
Since the single malformed message had signed and immutable thinking blocks, reconstructing the request modifies a thinking block and leads to the 400 API errors on every subsequent turn. The whole conversation is permanently bricked, not just one reply.
You can manually recover by having a fresh claude parse the session transcript and pick up where they left off, but it sucks having to waste tokens to recover a session because the harness is buggy.
@bcherny@ClaudeDevs I'm sure you all are already looking into this, but it looks like the root cause is a streaming/turn-boundary bug.
Before this happened, claude was re-running commands like "echo hello world" and claiming plan docs were corrupt. Then eventually started failing with this 400 error when I stopped it and asked what was going on.
Analyzing the session transcript, it looks like the agent loop failed to end the assistant turn between tool calls. One message accumulated 40 tool_use + 19 signed thinking blocks instead of ~20 separate turns. Tool results stopped feeding back, so the model went blind and started reality checking with "echo test123" and claiming files were corrupt.
Since the single malformed message had signed and immutable thinking blocks, reconstructing the request modifies a thinking block and leads to the 400 API errors on every subsequent turn. The whole conversation is permanently bricked, not just one reply.
You can manually recover by having a fresh claude parse the session transcript and pick up where they left off, but it sucks having to waste tokens to recover a session because the harness is buggy.
@bcherny@ClaudeDevs I'm sure you all are already looking into this, but it looks like the root cause is a streaming/turn-boundary bug.