LVNet accepted to #EACL26! Training-free keyframe selector for long-video QA: 🎯High accuracy low caption,⚡up to 3.4x speed, ⚙️filters 1,800 to 24 keyframes on 1 GPU,💸10x cheaper LLM cost.
Paper: https://t.co/wvrtJ2jmSc
More details in the thread. ⬇️
Demo: LVNet (top)
🚨 Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding 🚨
Introducing Active Video Perception: an evidence-seeking framework that treats the video as an interactive environment and acquires compact, query-relevant evidence.
🎬 Key Highlights:
🧠 Human-Inspired Active Perception
AVP mimics how humans watch video by first skiming for global context, then focusing on a few critical moments. It treats video as interactive environments.
🔄 Iterative Evidence Seeking
AVP runs a Plan–Observe–Reflect loop, dynamically querying video parts for fine-grained evidence and continually assessing whether it has enough information or needs to look deeper.
🚀 Efficiency Breakthrough: High accuracy meets low cost. AVP outperforms the best agentic approach by +5.7% accuracy while using just 12.4% of tokens and 18.4% inference time.
How does AVP transform passive video processing into active, agentic exploration? Dive into the details below! 🧵
Strefer auto-generates instruction data for tuning Video LLMs on space-time–focused video tasks.
With just +545 short videos, Strefer-trained models outperform baselines on various tasks, showing stronger space–time–aware perception & reasoning !!
(Thread 1/8) 🚨 Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data 🚨
Introducing Strefer: a novel data engine for auto-generating instruction data that enables Video LLMs to excel at spatiotemporal video understanding 🎬🧩⏳
Key Contributions:
▶️ Automated Pipeline: Eliminates dependence on legacy annotations through fully automatic instruction generation
▶️ Fine-grained Spatiotemporal Information: Produces temporally aligned, object-centric metadata with instruction-response pairs and multimodal prompts
▶️ Data-Efficient: Achieves improvements in space-time referring and reasoning with only 545 extra videos and no proprietary model dependencies
📄 Paper: https://t.co/d2mn1PtTkl
🌐 Project: https://t.co/LkPbRtyK0o
💻 Code: https://t.co/P0J35tvupO
🎥 YouTube (10-min video): https://t.co/aSswKaShyC
How does Strefer lay the foundation for perceptually grounded, instruction-tuned Video LLMs? Dive into the researchers' walk-through below! 🧵
We show that the approach even allows "learning from human videos" to improve its performance.
arxiv: https://t.co/EHDBROvp41
code: https://t.co/0WUkz8TB9C
We present a new System1-System2 model; it uses image diffusion model as its high-level System2 to predict embodiment agnostic pixel-based representation. A Transformer-based System1 maps such universal representations to actual robot actions.
#CoRL2025
Hey Robot Learning Community!
CoRL 2025 will be held in Seoul, Korea, Sep 27 - 30. Submission deadline: Apr 30 AoE.
It's two weeks to go!
Information: https://t.co/6AVF7UHg8g
We are excited to receive your great work on robot learning!
(1/5)
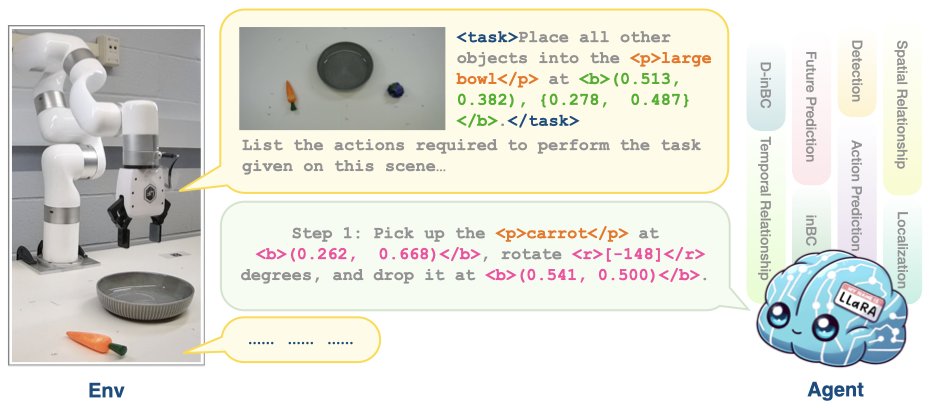
Excited to present our #ICLR2025 paper, LLaRA, at NYC CV Day!
LLaRA efficiently transforms a pretrained Vision-Language Model (VLM) into a robot Vision-Language-Action (VLA) policy, even with a limited amount of training data.
More details are in the thread. ⬇️
🚨🎥🚨🎥🚨 xGen-MM-Vid (BLIP-3-Video) is now available on @huggingface!
Our compact VLM achieves SOTA performance with just 32 tokens for video understanding. Features explicit temporal encoder + BLIP-3 architecture. Try it out!
🤗32 Token Model: https://t.co/S9mVhyXrMP
🤗128 Token Model: https://t.co/1juefgvHcg
📄Paper: https://t.co/910sKM7h19
🖥️Website: https://t.co/kvwcwKPUVC
🧵Research Refresher 👇
#ComputerVision #OpenAI #AIResearch #VLM
(1/3)
Despite using much fewer tokens and being smaller (4B vs. 34B), xGen-MM-Vid provides comparable video question-answering accuracies to SOTA.
I am extremely pleased to announce that CoRL 2025 will be in Seoul, Korea! The organizing team includes myself and @gupta_abhinav_ as general chairs, and @JosephLim_AI, @songshuran, and Hae-Won Park (KAIST) as program chairs.
📢📢📢Introducing xGen-MM-Vid (BLIP-3-Video)!
This highly efficient multimodal language model is laser-focused on video understanding. Compared to other models, xGen-MM-Vid represents a video with a fraction of the visual tokens (e.g., 32 vs. 4608 tokens).
Paper: https://t.co/9333HUaQhE
Website: https://t.co/kvwcwKQsLa
Researcher’s 🧵:👇
Salesforce presents xGen-MM (BLIP-3)
A Family of Open Large Multimodal Models
discuss: https://t.co/SruEf7WSUx
This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
Introducing LLaRA !!! https://t.co/lr46FPsF17
It's a new robot action model, dataset, and framework based on LLMs/VLMs. It's opensource and trainable at an academic scale (7B LLaVA-based), so you can finetune it for your robotics task!
🚀 Excited to share our latest project: LLaRA - Supercharging Robot Learning Data for Vision-Language Policy! 🤖✨
We create a framework to turn robot expert trajectories into conversation-style data and other auxiliary data for instruction tuning. More details to come! (1/N)
Today, we announced 𝗥𝗧-𝟮: a first of its kind vision-language-action model to control robots. 🤖
It learns from both web and robotics data and translates this knowledge into generalised instructions.
Find out more: https://t.co/UWAzrhTOJG
PaLM-E or GPT-4 can speak in many languages and understand images. What if they could speak robot actions?
Introducing RT-2: https://t.co/MhgZqCRfOC our new model that uses a VLM (up to 55B params) backbone and fine-tunes it to directly output robot actions!
Looking forward to showcasing one of the first foundation models for robotics at #RSS2023 next week!
Presenting "RT-1: Robotics Transformer for Real-world Control at Scale" from the Google DeepMind robotics team.
Website: https://t.co/NtydvYFtMK
Session: Tuesday 7/12, 3PM-5PM
Introducing Crossway Diffusion, a diffusion-based visuomotor policy taking advantage of SSL. In short: we add state decoders to reconstruct states during training diffusion policy and it works better. More at: https://t.co/3SPn4Y0yxC