For anyone who might find this useful, AI tools are really good at reading messy doctors' handwriting.
Recently I was trying to read a note for a family member for a really old note for their case history. I used Chatgpt + gemini, expecting only some ideas from the context, but the answer was really convincing.
I was skeptical of the answer at first, even with the current progress of vision models, I was not expecting it to be better than a person who spend a good deal of time trying to figure out.
But comparing their answer to the handwriting and the context, I was convinced it got it enough of it that I could figure out the rest. Was messy handwriting a part of their training?
Thanks @amydeng_ for the idea to share this story. Never occurred others may find it useful.
Some pretty fun research reports from @baseten
Really appreciated how they tried their own techniques, and the problem solving when they didn't work out at first.
On Policy Distillation (seems to be the new post training meta)
https://t.co/4i335lXUTI
Neural KV compression. Really interesting parts: [1] They used their own internal RoPE since NN they used for the compression does a linear combo->washes out any positional info. [2] After a certain number of params, it didnt work out, but it did once they used identity matrix initialization [3] Remove the standard RMSNorm for the queries/keys at the end of the perceiver -> noisy lengths help with attending to right tokens. [Don't quote me on these, might have missed something. ]
https://t.co/MqHDNKgnfv
Repeated KV cache for growing contexts. Main takeaway: one-shot KV compression is not the same as recursive compression. Fresh/chunked compaction works surprisingly well, but if you keep compressing already-compressed caches, error compounds — JPEG-of-a-JPEG style. Also liked the doc-boundary result: attention is mostly local within each document/patient, so fitting one global compressed cache over unrelated records gets brittle. Compress each block separately, then stitch the compact KV caches together.
https://t.co/iPR2Ntzkvu
OpenAI partnered with Boston Children’s and Harvard to reanalyze 376 rare disease cases that had already gone through specialist review and still had no answer.
Using o3 Deep Research (1 year old+ model), the team found evidence linked leads that doctors could review across symptoms, inheritance, genetic variants, and new literature.
After expert review, follow up testing, and clinical lab confirmation, 18 families received diagnoses.
That is a 4.8% gain in cases that were already extremely difficult, with some patients waiting years for an explanation. This is a beautiful step forward into hyper advanced medical care for everyone.
Another great video by @bycloudai
https://t.co/y4BgYZDWy8
Covering the Mimo models. The presentation is so elegant and fun where you can kinda just turn your brain off.
My favorite parts:
MiMo’s hybrid attention result is surprisingly specific: ~5 sliding-window attention layers for every 1 global attention layer, with only a 128-token local window.
In their ablations, SWA-128 + attention sink beat both SWA-512 on long-context evals. Their explanation: 128 forces a cleaner division of labor. Local layers model nearby context; global layers handle long-range dependencies. At 512, the local layers may start trying to do both.
This setup beats regular attention, though the regular attention didn't use sinks, but still goes to show the power if these recent innovations.
I’m an AI researcher turned brain tumor patient, and recently I used the models to crack my mystery fatigue faster than my PCP could.
I believe everyone can do the same with their own symptoms. Here’s how:
We added >220K FDA regulatory and >1M clinical trial docs to #paperclip. All natively indexed for agents and free.
Now agents can easily reason over clinical studies w/o web search!
E.g: find all trials that were approved despite missing endpoint https://t.co/30GGqfCQmO
@agarwl_ I wonder if the domain had an effect, I'm guessing you tried it on a scientific domain.
I've been seeing ML algorithms sometimes react completely differently in scientific domains.
The most capable health AI ever shipped went live today. On the questions that matter most, you may not get its best answer.
Claude Fable 5 scores 66% on HealthBench Professional. The prior frontier, Opus 4.8: 56.9%. GPT-5.5: 51.8%.
Read the footnote. That 66% reflects the unrestricted model. For general users, biology and chemistry queries fall back to Opus 4.8 by design. The frontier clinical reasoning exists. Access to it is rationed by safeguards built for a different threat: bioweapons uplift, not bedside decisions.
The tradeoff may be correct. Dual-use is real, and most clinical questions won't trip the classifier. But the principle is new and worth naming. The gap between what a model can do and what a clinician is allowed to ask it is now an engineering decision made upstream of the exam room.
I've spent two years arguing the cost of delayed AI adoption in medicine is measured in patients. Add a line to that ledger. Health systems planning around "frontier model equals frontier clinical performance" should know the number on the slide and the number you receive are not always the same.
"Artificial intelligence is helping improve accuracy in patient care and in some cases saving time and money, according to a survey sponsored by Philips (https://t.co/v4uM22NjAo), opens new tab, which provides diagnostic, imaging, and cloud technology to the healthcare industry, the CEO of its North American division said."
"
Among the clinicians, 27% said AI had helped them identify possible medical errors at least three times in the past three months, while 36% said it increased the number of patients they are able to see on a weekly basis. But 77% of the clinicians who responded said AI training was unavailable, limited or inconsistent."
https://t.co/3UojXRn73E
Another great paper from Google.
Shows general LLMs can solve formal math by planning proofs and checking each step. Raised general LLM performance from under 10% to 70%.
A general LLM failed badly when asked to write full formal proofs in 1 try, but became much stronger when it planned, split the work into smaller claims, reused past claims, and learned from Lean’s feedback.
The paper shows the weakness was not just the model’s math ability, but the way it was being used - the absence of structured interaction with a verifier.
The key idea is that the model does not try to write one giant perfect proof at once, because that usually fails on long and tricky problems.
Instead, LEAP stores the proof as a graph of goals and subgoals, so useful lemmas can be reused instead of rediscovered every time.
The authors tested LEAP on Putnam 2025 and a new Lean benchmark built from 60 IMO-style problems, where ordinary one-shot proof writing did very poorly.
LEAP solved all 12 Putnam 2025 problems and raised general LLM performance on the Lean IMO benchmark from under 10% to 70%.
----
Link – arxiv. org/abs/2606.03303
Title: "LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks"
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
I think I was using SFT / NTP interchangeably in a non-accurate manner; my impression is:
Pretraining = NTP on the broad corpus.
Mid-training = still NTP / continued pretraining, but on filtered, reweighted, and repacked data, including whatever human-generated reasoning-rich material was in the corpus.
Initial RL climb = reward-based RL starting from the mid-trained model
Self-distillation = later NTP on selected RL rollouts,
Continue RL
@stochasticchasm I was confused on this as well. I'm thinking maybe they meant no synthetic reasoning traces were used for the SFT phase, but human CoT was in it. In their mid training data section they did mention that had structured reasoning.
https://t.co/6FZ406ZPUQ
Reasoning before RL?
I was a little confused on this one. It first sounded like they didn't include any human reasoning traces for before-rl training, but then it sounds like they just didn't include any LLM generated traces. I'll need to re-read later tonight
“We choose to not use any synthetic data generated by language models during pre-training and make an effort to avoid and remove AI-generated content within collected data sources.”
“MAI-Base-1 is trained on a mixture of publicly available and licensed human-generated data.”
“To improve performance on reasoning tasks, we filter documents primarily from the pre-training PDF corpus…”
“This filter keeps documents with structured reasoning and analysis, rather than simple factual statements.”
There does seem to have theme that SFT -> inheriting, vs RL -> learning, though I'm having a little trouble with the distinction
“Capabilities should be learned, not inherited.”
“Although faster to acquire, intelligence imitated through distillation lacks the steerability and robustness essential to long, enduring climbs.”
Here I believe distillation means that they generated a bunch of reasoning traces form the model and kept the good ones.
"“Pre- and mid-training give our base model broad predictive competence and knowledge, but they do not specify how the model should behave, solve long-horizon tasks, or allocate inference-time computation.”"
So maybe they just meant the type of reasoning traces for what they aimed to achieve specifically.
Numerical Stability is what guided the RL training and data strategy.
“Even small per-token logprob discrepancies compound across long rollouts and can destabilize the importance-sampling correction in off-policy RL.”
“Small numerical discrepancies between inference and training would sometimes accumulate during training and cause a climb to diverge.”
A must read paper.
It seems they prioritized the biggest curiosities on how these LLMs train and respond, especially the role of RL vs SFT when it comes to task/reasoning. I think we're going see their hard earned insights into other top model papers / technical reports.
The whole paper is worth reading, everything is well explained.
Big theme for me: Data cleaning - Data quality - Data Diversity > Data quantity; this may come though at smaller scales, but bigger scales expose it.
Some of the parts which intrigued me the most:
Part 1/n
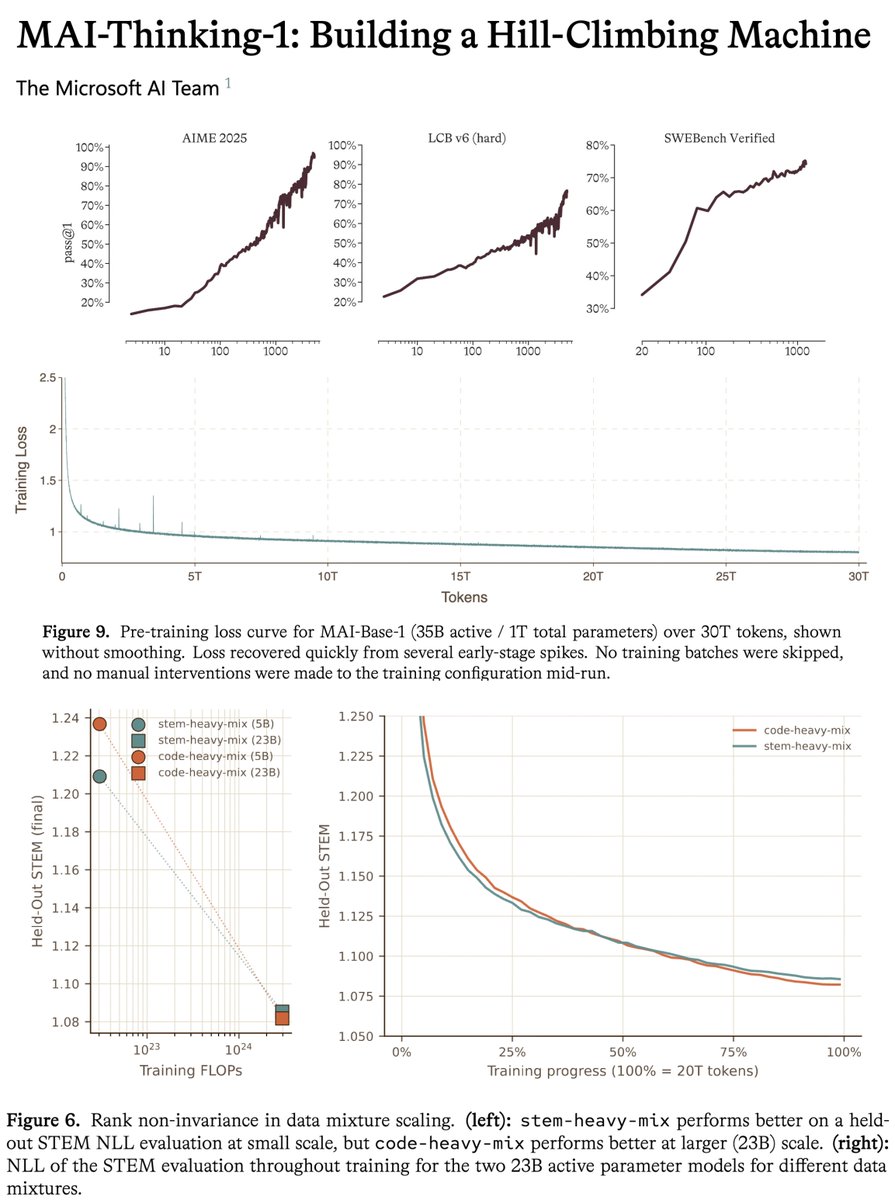
Scale exposes data quality.
"During our data-mixing experiments, we uncovered an empirical finding that challenged one of our core scaling assumptions: the idea that the relative ordering of two datamixes – which one yields better evaluation performance – is preserved as compute increases."
“As expected from the low-scale results, stem-heavy-mix outperformed code-heavy-mix on NLL STEM evaluations early in training. However, the STEM evaluation curves crossed midway through training, with code-heavy-mix eventually surpassing stem-heavy-mix.”
“From inspection of training and validation loss trends of individual sources, we identified two data sources that had high quality STEM content, but more fuzzy duplication than our other datasets and less diversity of content.”
“These two sources had 11.8% weight in stem-heavy-mix, but just 0.3% in code-heavy-mix. Our hypothesis is that these sources were very helpful for the smaller model, but their lack of diversity was inherently less useful at larger scale.”
“Across many experiments, we consistently observe that rigorous deduplication and removal of redundant data improve both pre-training metrics and downstream reasoning benchmarks.”
Hillclimbing from scratch is for sure suffering but we learned a ton by going through the pain. So proud of our team 💫
Check out our technical paper: https://t.co/QRw2rkcKQV
“We conducted extensive ablations to understand how to best perform self-distillation in practice.”
“For a fixed token budget, increasing prompt diversity is more valuable than increasing the number of traces per prompt.”
“We also found simple random sampling to outperform several biased selection strategies, including shortest-trace sampling and heuristic filtering approaches…”