8 claude code patterns that actually scale beyond toy projects
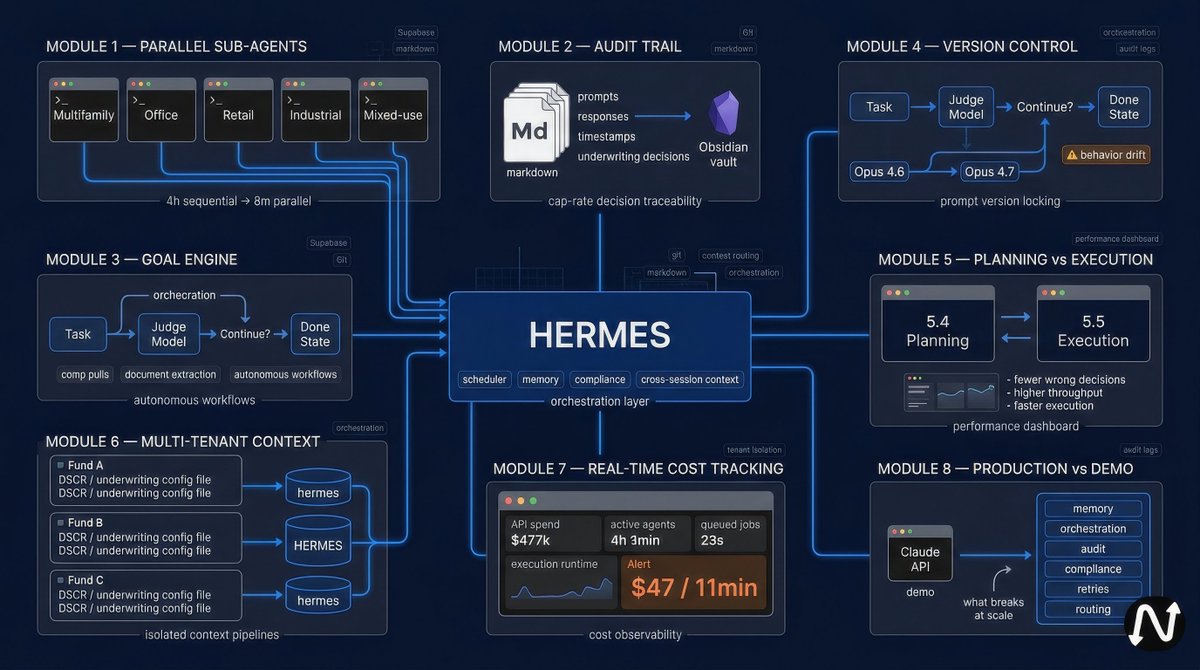
1. spawn sub-agents per asset class not per task
running 5 parallel terminals on multifamily, office, retail, industrial, mixed-use comps beats one agent doing all 5 sequentially. 4 hour research loop becomes 8 minutes.
2. write every prompt + response to obsidian for audit trail
when a client asks why you underwrote at 6.5% cap rate instead of 7% you need receipts. markdown export from every claude session with timestamp.
3. route through hermes not directly to claude
hermes adds the scheduler + memory + compliance layer. direct claude api calls work for demos but die in production when you need cross-session context.
4. use /goal for multi-step workflows that don't need babysitting
judge model checks completion after every turn. auto-continues until goal is met or turn budget runs out. perfect for comp pulls, document extraction, anything with a clear done state.
5. version-lock your prompts in git
opus 4.6 vs 4.7 behave differently on the same prompt. when throughput changes track which model version was live. saves 6 hours of "why did this break" debugging.
6. run planning in 5.4 execution in 5.5
codex 5.4 plans 30% better. 5.5 executes faster. alternating between them on a 200 deal pipeline = 60 fewer wrong decisions per quarter.
7. set per-tenant context files not global configs
each fund has different underwriting standards. hardcoding DSCR thresholds in the system prompt breaks when you add a second client. per-tenant .context files in supabase.
8. log every api call cost in real time
opus extended thinking blows through $47 in 11 minutes if you're not watching. real-time cost dashboard or you wake up to a $4k anthropic bill.
google deepmind's alphaproof nexus solved 9 erdős problems for a few hundred dollars per problem
some unsolved for 56 years
the mechanism: gemini 3.1 pro generates proof attempts, lean's compiler checks every logical step
no human review needed to confirm correctness
the part most people will miss: a basic agent that alternates llm generation with compiler feedback replicated all 9 successes
the full-featured system with evolutionary search and reinforcement learning only added 5% improvement
for anyone building agent workflows: the simple loop (generate → verify → iterate) beats the complex architecture
ai jobpocalypse narrative flipped
indeed software engineer postings inflected upward in june while overall jobs kept falling
the operators hunting 100x engineers who know how to use ai, not replacing them
the distinction: companies aren't cutting headcount. they're hunting people who can multiply output with claude / codex / gemini.
1 person powered by agents ships what a 10-person team shipped 18 months ago
that person gets paid more, not less
the demand curve for builders who understand prompt engineering + sub-agent orchestration + MCP routing is vertical
if you're still writing code the 2023 way (manual everything, no agent assist, single-file edits) the market doesn't need you
if you're running 5 parallel claude sessions with /goal flags and cross-project memory you're printing job offers
The AI jobpocalypse narrative is wrong. And the data is starting to make that impossible to ignore.
Andreessen Horowitz just dropped charts showing demand for software engineers is rising, not falling. Indeed job postings for software engineers inflected upward in June 2025 while overall job postings kept trending down. Morgan Stanley data shows software devs are growing as a share of new jobs created. AI-exposed industries are seeing above-trend wage growth.
This is not what the doomers predicted.
Here is what is actually happening. Companies are not replacing engineers with AI. They are hunting for engineers who know how to use AI. The distinction matters enormously.
We used to talk about 10x engineers. Now we are talking about 100x engineers, maybe 1000x. One person powered by Claude or ChatGPT can ship what used to require a whole team. Brian Armstrong is already building toward this with his "one person product team" concept at Coinbase.
I had a conversation with one of our engineers in Eastern Europe recently. I asked if he knew other engineers like him, AI-pilled, high output, tool-native. He said the engineers he knew still believed in writing code by hand. That told me everything.
The talent gap is not about headcount. It's about mindset.
The operators who figure out how to attract, retain, and protect AI-pilled talent are going to have a serious structural advantage.
you either build the thing people want or you build the thing investors want
the problem is: the thing people want is boring. the thing investors want is fundable.
people want the follow-up email sent on time. investors want the AI OS.
people want the comp report in 4 minutes instead of 6 hours. investors want the TAM slide.
the boring version compounds. the fundable version gets you 18 months of runway to figure out the boring version.
pick one. you don't get both at the same time.
how to build an AI marketing ops fleet that runs itself
most teams bolt AI onto their existing stack and wonder why nothing changes. the unlock is building the AI-native operating system first, then migrating the work into it.
here's the blueprint i'd build if i were starting today:
the stack:
1. knowledge graph as the foundation. ingest emails, meetings, tweets, docs, voice memos. markdown in, postgres + pgvector + typed graph out. every agent reads the graph first before doing work.
2. vertical agent fleet, not horizontal tool suite. BDR agent, SDR agent, content agent, paid agent, attribution agent running as one coordinated squad. real-time budget reallocation across channels based on what's converting.
3. client deployment architecture. one agency graph provisioning N isolated client deployments. each client has their own context, their own brand voice, their own approval gates. the agency learns anonymized patterns across all of them.
4. overnight dream cycle. dedupes entities, repairs broken links, merges duplicate records, regenerates summaries. graph builds itself while you sleep.
what this enables:
- 10,000 sales call transcripts scanned for insights in 4 hours instead of 6 weeks of analyst time
- content pipeline that generates blog → thread → newsletter section → 3 tweets from one source doc
- paid campaigns that shift budget from underperforming channels to winners every 6 hours without manual review
- attribution that ties every dollar of spend back to pipeline, not just top-of-funnel vanity metrics
why agencies should build this now:
- airtable founder just announced $10M in credits, $20K per team to build on hyperagent
- the next wave of marketing infrastructure won't be built by martech SaaS companies. it'll be built by agencies who got tired of duct-taping 9 tools together and just built the whole stack themselves.
- if you're running an agency and your ops still look like HubSpot + Marketo + Salesforce + 6 point solutions, you're about to get outrun by the team that collapsed it all into one AI-native system.
We’re giving away $10,000,000 to founders building agent-first businesses.
Autonomous, proactive agents will run tomorrow's companies.
We're backing 500 founders building them.
The Founding 500.
https://t.co/u8mxRWEXiT
hermes agent now supports bitwarden secrets manager
for multi-agent workflows this is the first time you can provision per-agent api keys without hardcoding credentials in environment files
one secrets vault, N agents, zero .env files committed to git
the deployment model used to be:
- copy-paste keys into 12 different .env files,
- pray nobody commits them,
- rotate manually when someone leaves
now it's:
- wire the secrets manager once,
- agents read at runtime,
- revoke access with one click
gemini 3.5 flash for image search is working out of the box
label each image with one gemini call, embed the labels, hybrid search
the cost per 1,000 images is around $2
for an acquisitions workflow scanning county deed records this means you can OCR every property photo in a 500-listing pipeline in under 5 minutes for $1
Building an Image Search Engine with Gemini 3.5 Flash
As the latest flash models get better, products like image search are now possible with minimal effort.
1) Label each image. One gemini-3.5-flash call.
2) Embed the labels, description.
3) Hybrid search.
Interesting how well this is working out of the box.
Link to code below
10 free MCP servers worth wiring up today
1. brave-search → web research without rate limits
2. anthropic/calendar → meeting scheduling across team calendars
3. anthropic/filesystem → read/write to local project directories
4. modelcontextprotocol/fetch → api calls without custom code
5. modelcontextprotocol/postgres → query production databases directly
6. anthropic/memory → persistent context across sessions
7. mcp/github → pull issues, PRs, commit history
8. mcp/slack → read channels, post messages, search history
9. mcp/notion → query databases, create pages
10. mcp/gdrive → read docs, sheets, slides without export
for a fund admin workflow you can wire CRM to underwriting to LP comms with one config file
picking the right SaaS used to be the work... now you're composing 6 of them so they actually share context
@ClaudeCodeLog the /usage per-category breakdown is what every automation builder needs... realizing your MCP costs are 10x your subagent costs changes how you architect the next workflow
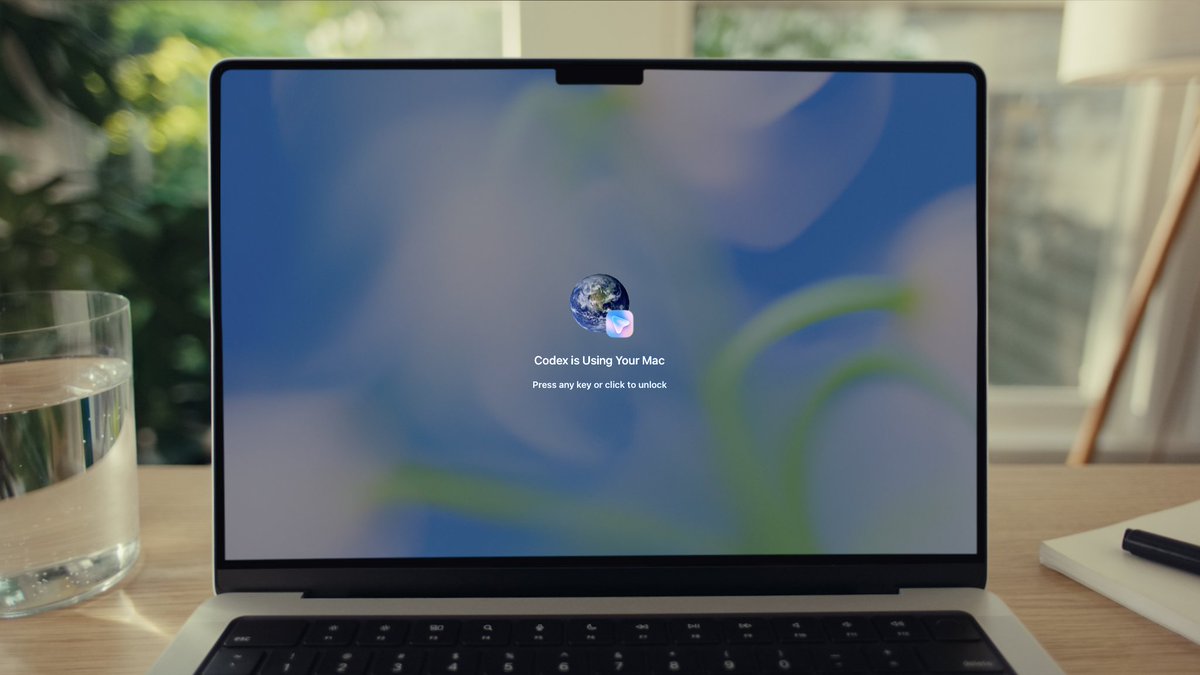
codex can now securely use apps on your mac from your phone even when your mac is locked and the screen is off
for remote workflows this is the first time you can run a 6-hour parallel terminal session without keeping your laptop awake
i used to run overnight underwriting batches on a VPS because my macbook would sleep and kill the session
now i start the workflow from my phone at 11pm, mac stays locked, wake up to 200 processed OMs
Highlights from today’s Codex Thursday launches:
1️⃣ Codex can now securely use apps on your Mac from your phone, even when your Mac is locked and the screen is off.
https://t.co/JUOss3M2Va
rental market fragmentation is the reason property management software never consolidated
Parcl research found ~90% of US rental homes are managed by companies outside the top 10 brand names
that fragmentation creates the services-rollup opportunity nobody is taking
Long Lake hit $100M EBITDA rolling up HOA management in under 2 years because the operating system was the moat
the rental-management version of that play is sitting empty
Want to understand a rental market?
Start with who manages the homes.
Parcl Research found ~90% of US rental homes are managed by companies outside the top 10 brand names...
That fragmentation creates opportunity - if you know where to look
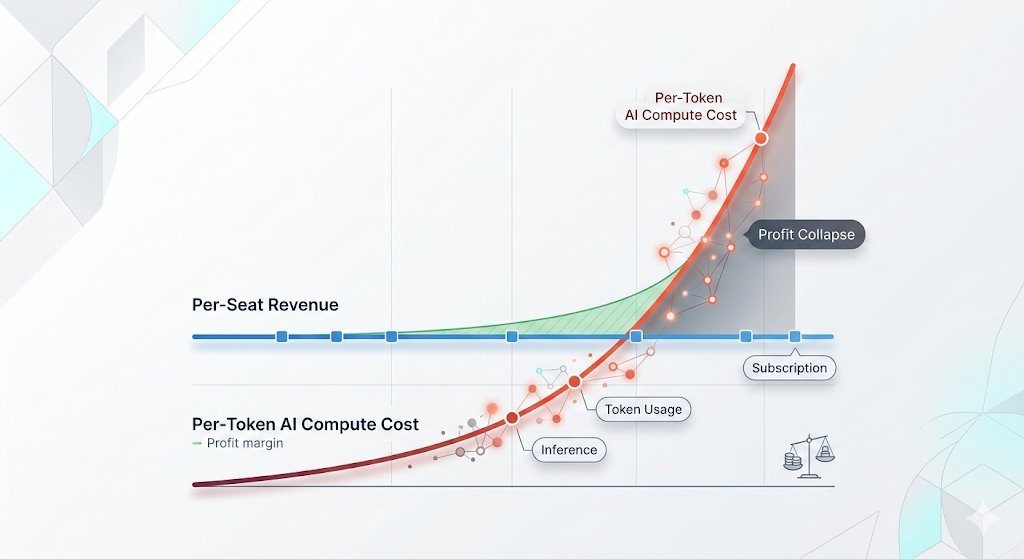
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
real estate is still one of the best places to build a business because you're not competing against the entire world
you're competing against maybe a dozen people in your local market and half of them still use fax machines
proptech founders keep raising money to build global platforms that compete with Zillow and Costar for everyone's attention
meanwhile syndicators and family offices are sitting in markets where the local competition can't answer the phone after 5pm or extract a T12 from an OM in under 6 hours
the capital deployers winning right now aren't building for scale: they're building local monopolies on speed
when your only competitors are regional brokerages still running spreadsheets for underwriting you don't need to be the best in the world
you just need to be faster than the three other groups bidding on the same off-market deal
real product-market fit isn't when people say "cool tool"
it's when they're willing to blow up their existing workflow to use you
when a fund admin is importing 6 months of capital call history into your system before you even have proper onboarding docs
when a syndicator is letting your underwriting agent draft their deal memo before they've seen it work on their own portfolio
when a family office is routing live LP questions to your IR agent while you're still in beta
the pain of staying with the old system became worse than the risk of trusting something unproven
you know you have real PMF when customers absorb operational risk to use you before you're ready
because the alternative (manual T12 extraction, 6-hour underwriting cycles, missed LP calls) is that intolerable
openai's reasoning model just disproved an 80-year-old math conjecture
erdős asked in 1946 how many point pairs can be exactly 1 unit apart on a flat surface. best answer came from square grids. erdős himself said you probably can't beat that by much
the AI found configurations that beat the grid by a polynomial factor
here's what makes this different: the proof pulled from algebraic number theory. class field towers. golod-shafarevich theory. nobody expected those tools to solve a geometry problem about distances
cross-domain reasoning at research level
fields medalist tim gowers verified it
this is the first time AI independently solved a prominent open research problem
the model chose the approach. wrote the proof. made connections expert mathematicians didn't prioritize
for underwriting this means a model that can pull comp data from 3 unrelated asset classes and find the non-obvious correlation your analysts missed
an LP comms workflow that notices your top 4 investors all asked variations of the same liquidity question across different quarterly calls
a CMA system that connects zoning changes in one county to price movements in an adjacent market 18 months later
reasoning models don't just process faster. they find paths humans don't see
when your fund's underwriting stack can make those leaps and your competitor's can't, the performance gap compounds every deal cycle
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
You do not want to be competing against the world for eyeballs
One of the reasons why real estate is such a good place to make money
You're competing against a few people in your local market and most of them are idiots
six months ago every fund admin we talked to said "we'll never let AI touch our LP comms"
now they're asking if the agent can handle quarterly updates and capital calls without them reviewing every line
the cycle: denial, then panic adoption, then forgetting it was ever controversial
what's wild is how fast the memory rewrites. three months in and they're already saying "obviously we were going to automate LP comms, we just needed the right system"
this is the pattern with every capability jump. before it ships: "that's impossible" or "that's dangerous". after it ships: "of course we're using it, everyone is"
right now institutional teams are having the same conversation about underwriting agents that they had about LP comms six months ago
in three months they'll forget they ever resisted
Everything you need to master in 2026 to get rich:
• Vibe coding
• Hermes agent
• Running Codex/Claude Code side by side
• /goal
• Running your own local models
• Karpathy's Autoresearch
• Building an X audience
• Creating videos
• AI agent swarms
• How machine learning works
• How databases work (been using Convex)
• Using API's
• Training your own LoRAs
• Elimination of doom scrolling