Scrapling is an adaptive Web Scraping framework that handles everything from a single request to a full-scale crawl by @D4Vinci1
Follow for daily tips & tricks.
Yesterday, we reached our first million downloads 🎉
We went from 200k to 1M in exactly two months! The first 200k was reached in a year!
Thanks to all the contributors and the community support that got us here ❤️🔥
Expect a very insane update soon 🚀
🕷️ Scrapling tip: SitemapSpider IGNORES hreflang URLs by default
Flip sitemap_alternate_links=True to also dispatch every <xhtml:link rel="alternate"> URL through your rules — crawl every locale of a multilingual site in one go ⚡
🕷️ Scrapling tip: pass process=fn to LinkExtractor
Runs a callable on every extracted URL BEFORE allow/deny filters & dedup. Return None to drop, or a rewritten URL (strip utm_*, force https, canonicalize).
Pairs with allow=/deny= for tight URL cleanup ⚡
🕷️ Scrapling tip: a <sitemapindex> can point to dozens of child sitemaps — SitemapSpider descends them ALL by default
Set sitemap_follow to a LinkExtractor and only matching child sitemaps get crawled. Skip the ones you don't care about ⚡
Today, Scrapling has surpassed Scrapy on Github, which made Scrapling the 2nd top Python repo in Web Scraping after Crawl4ai in terms of Github stars 🎉
That comes after staying at the top of GitHub's trends for 4 consecutive days and making another million downloads in exactly 34 days!
Thanks to everyone who helped us come so far ❤️🔥
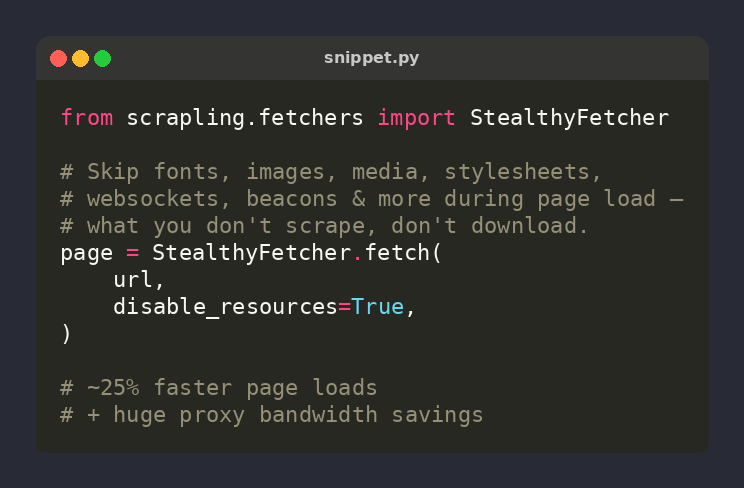
🕷️ Scrapling tip: LinkExtractor SILENTLY drops PDF/zip/image/video links — deny_extensions defaults to IGNORED_EXTENSIONS
Scraping a docs portal? You'd be missing every download link. Pass deny_extensions=[] (or your own set) to keep them ⚡
🕷️ Scrapling tip: LinkExtractor works in ANY plain Spider — not just CrawlSpider
links = LinkExtractor(allow=r"/posts/")
for url in links.extract(response):
yield response.follow(url)
Absolute, filtered, deduped URLs in one call ⚡
Scrapling v0.4.9 is out 🛠️
→ Fixed session-level proxies being silently ignored in HTTP sessions (could leak your real IP, update now)
→ Updated all browsers & fingerprints
→ New --version CLI flag
→ More fixes for Windows, encoding, and adaptive parsing
Check it out!
🕷️ Scrapling tip: drop a robots.txt URL into SitemapSpider — every Sitemap: directive is auto-extracted & crawled
class MySitemap(SitemapSpider):
sitemap_urls = ["https://t.co/iNzBudjYpp"]
No need to hunt for the sitemap URL yourself ⚡
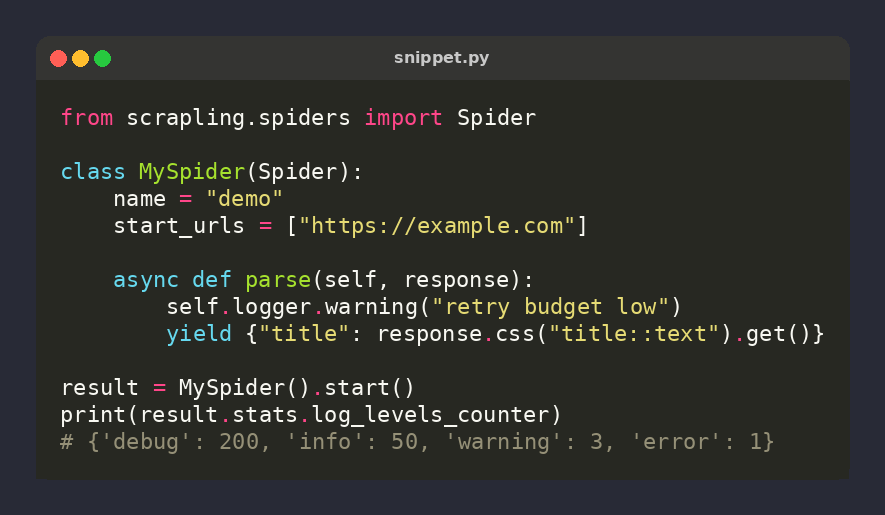
🕷️ Scrapling tip: stats.log_levels_counter — every self.logger.* call in your spider is bucketed by level into the final CrawlStats
result = MySpider().start()
print(result.stats.log_levels_counter)
# {'debug': 200, 'warning': 3, 'error': 1}
Free CI health signal 🎯
🕷️ Scrapling tip: old guides say "disable WebGL to dodge fingerprinting" — modern WAFs now flag the ABSENCE of WebGL as bot behavior
allow_webgl=True is StealthyFetcher's DEFAULT. Keep it on; the missing canvas is what gets you caught 🎯
🕷️ Scrapling tip: response.follow() INHERITS the original request kwargs — headers, proxy, impersonate carry over
yield response.follow(
'/next',
headers={'X-Trace': '1'},
)
New kwargs MERGE over old. Configure once on the seed, every follow inherits ⚡
🕷️ Scrapling tip: page_action runs AFTER navigation but BEFORE wait_selector
StealthyFetcher.fetch(
url,
page_action=lambda p: https://t.co/6DF0nx1PI9('#load-more'),
wait_selector='.item:nth-child(50)',
)
Click → fetcher waits for the result. Zero manual sleeps ⚡
🕷️ Scrapling tip: parsers STRIP HTML comments & CDATA by default — anything inside <!-- --> or <![CDATA[]]> is invisible to your selectors
Fetcher.configure(
keep_comments=True,
keep_cdata=True,
)
Flip both on for templates, JSX, or JSON tucked in comments ⚡
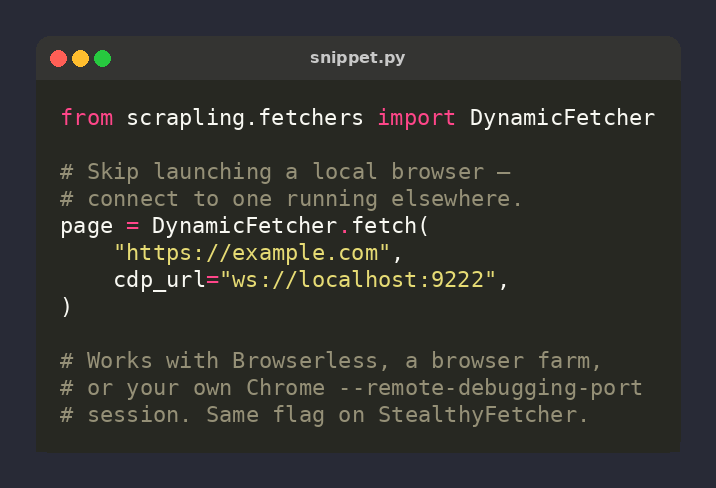
🕷️ Scrapling tip: skip launching Chromium — connect to a remote browser via CDP
page = DynamicFetcher.fetch(
url,
cdp_url='ws://localhost:9222',
)
Talk to Browserless, a browser farm, or your own Chrome --remote-debugging-port session ⚡
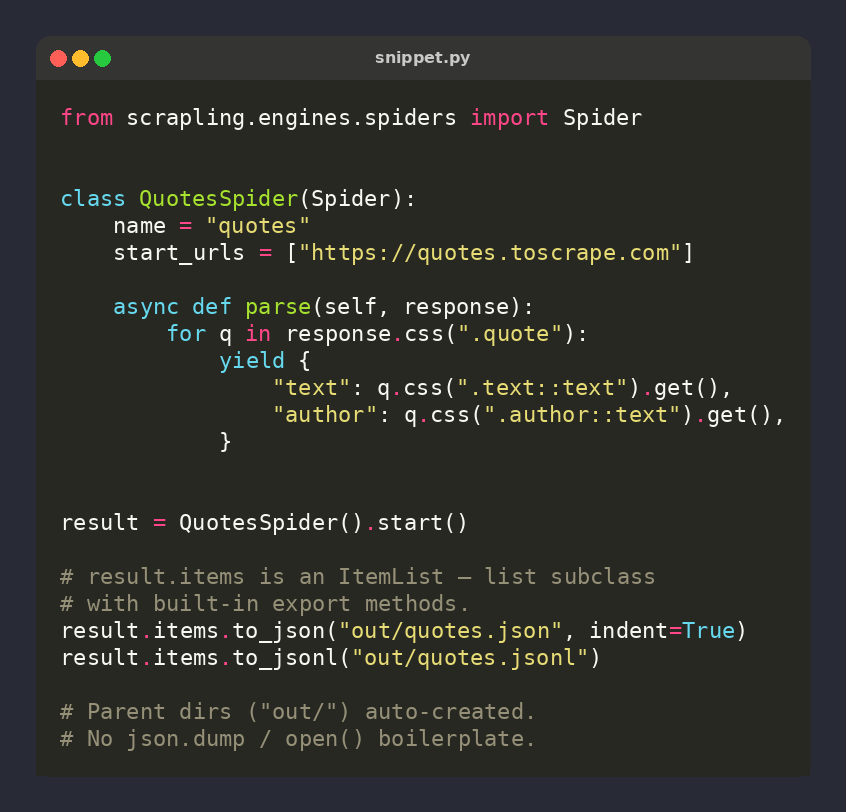
🕷️ Scrapling tip: result.items is an ItemList with built-in export methods
https://t.co/V4ql8Apy4W_json("out.json", indent=True)
https://t.co/V4ql8Apy4W_jsonl("out.jsonl")
Parent dirs auto-created. No json.dump or open() boilerplate ⚡
🕷️ Scrapling tip: development_mode caches to .scrapling_cache/{name}/ — RELATIVE TO CWD, not your script
class MySpider(Spider):
development_mode = True
development_cache_dir = "/tmp/cache"
Pin it so swapping CWD between runs doesn't silently miss the cache ⚡








![Scrapling_dev's tweet photo. 🕷️ Scrapling tip: LinkExtractor SILENTLY drops PDF/zip/image/video links — deny_extensions defaults to IGNORED_EXTENSIONS
Scraping a docs portal? You'd be missing every download link. Pass deny_extensions=[] (or your own set) to keep them ⚡ https://t.co/YkgagApuNf](https://pbs.twimg.com/media/HKX1wdHXEAAgF4H.png)


![Scrapling_dev's tweet photo. 🕷️ Scrapling tip: drop a robots.txt URL into SitemapSpider — every Sitemap: directive is auto-extracted & crawled
class MySitemap(SitemapSpider):
sitemap_urls = ["https://t.co/iNzBudjYpp"]
No need to hunt for the sitemap URL yourself ⚡ https://t.co/c3O9Byt8J4](https://pbs.twimg.com/media/HKIu0TTXkAESXoV.jpg)





![Scrapling_dev's tweet photo. 🕷️ Scrapling tip: parsers STRIP HTML comments & CDATA by default — anything inside <!-- --> or <![CDATA[]]> is invisible to your selectors
Fetcher.configure(
keep_comments=True,
keep_cdata=True,
)
Flip both on for templates, JSX, or JSON tucked in comments ⚡ https://t.co/gH29EBBkEb](https://pbs.twimg.com/media/HJpJ5rNXcAQSUR0.png)