Hi all, my name is Alisa, I am making the online training "Zero Day Engineering". If you want to get into the *real* offensive cyber security (reverse eng, vulns, exploits, fuzzing, pwn, ... 0days), eager to get your hands dirty, and haven't seen it yet, you probably should:
New course: Spec-Driven Development with Coding Agents, built in partnership with @jetbrains, and taught by @paulweveritt.
Vibe coding is fast, but often produces code that doesn't match what you asked for. This short course teaches you spec-driven development: write a detailed spec defining what to build, and work with your coding agent to implement it. Many of the best developers already build this way.
A spec lets you control large code changes with a few words, preserve context across agent sessions, and stay in control as your project grows in complexity.
Skills you'll gain:
- Write a detailed specification to define your mission, tech stack, and roadmap, giving your agent the context it needs from the start
- Plan, implement, and validate features in iterative loops using a spec as your agent's guide
- Apply the same repeatable workflow to both new and legacy codebases
- Package your workflow into a portable agent skill that works across agents and IDEs
Join and write specs that keep your coding agent on track!
https://t.co/hI4GwuvhtN
Long-horizon AI research agents are mostly a state-management problem.
It is not enough for an agent to reason well in the next turn. ML research requires task setup, implementation, experiments, debugging, and evidence tracking over hours or days.
This new paper introduces AiScientist, a system for autonomous long-horizon engineering for ML research.
The key idea is to keep control thin and state thick. A top-level orchestrator manages stage-level progress, while specialized agents repeatedly ground themselves in durable workspace artifacts: analyses, plans, code, logs, and experimental evidence.
That "File-as-Bus" design matters. AiScientist improves PaperBench by 10.54 points over the best matched baseline and reaches 81.82 Any Medal% on MLE-Bench Lite. Removing File-as-Bus drops PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points.
Why does it matter?
Autonomous research agents need durable project memory, not just longer chats.
Paper: https://t.co/A84c75oumP
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
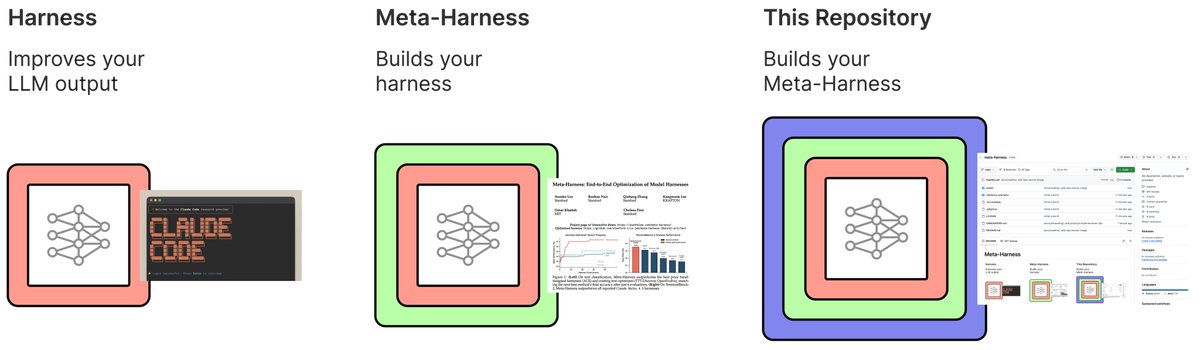
We just released code for Meta-Harness! https://t.co/OdU7zocdPl
Aside from replicating paper experiments, the repo is designed to help users implement good Meta-Harnesses in completely new domains! Just point your agent at ONBOARDING.md and have a conversation
Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey https://t.co/Mh19vMYrH7
As AI agents move beyond static benchmarks into long-horizon, real-world environments, memory becomes the critical infrastructure for bridging the utility gap. This survey unifies foundation agent memory across three dimensions:
🧠 Memory Substrate → internal (weights, KV cache, latent states) vs. external (vector stores, knowledge graphs, text records)
🔄 Cognitive Mechanism → sensory, working, episodic, semantic, and procedural memory, mapped from human cognition to agent architectures
👤 Memory Subject → who is memory serving? User-centric memory for personalization vs. agent-centric memory for skill accumulation and task transfer
→ Analyzes memory operations across single-agent and multi-agent topologies, including architecture, routing, and conflict resolution
→ Covers learning policies for memory management: prompting, fine-tuning, and RL-based approaches
→ Reviews 218 papers across 2023–2025 with evaluation benchmarks and metrics for both user- and agent-centric settings
→ Identifies six open challenges including continual learning, privacy-preserving memory, multimodal grounding, and real-world evaluation
@Salesforce authors: Zixuan Ke @KeZixuan, Liangwei Yang @Liangwei_Yang, Juntao Tan @chrisjtan, Shelby Heinecke @shelbyh_ai, Huan Wang @huan__wang, Caiming Xiong @CaimingXiong
#FutureOfAI #EnterpriseAI #LLMAgents
NEW research from CMU.
(bookmark this one)
The biggest unlock in coding agents is understanding strategies for how to run them asynchronously.
Simply giving a single agent more iterations helps, but does not scale well.
And multi-agent research shows that coordination > compute.
A new paper from CMU proves this with a practical multi-agent system.
CAID (Centralized Asynchronous Isolated Delegation) borrows proven human SWE practices: a manager builds a dependency graph, delegates tasks to engineer agents who work in isolated git worktrees, execute concurrently, self-verify with tests, and integrate via git merge.
CAID improves accuracy over single-agent baselines by 26.7% absolute on paper reproduction tasks (PaperBench) and 14.3% on the Python library
development tasks (Commit0).
The key insight is that isolation plus explicit integration beats both single-agent scaling and naive multi-agent approaches.
For long-horizon software engineering tasks, multi-agent coordination using git-native primitives should be the default strategy, not a fallback.
Paper: https://t.co/cRAbG7SrR5
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
@CrownRelo We had a very distressing experience with our relocation shipment from Singapore. After our goods were already in transit, we were suddenly told very late, close to delivery, that we had to pay more due to an alleged “volume increase.”
After unpacking, we also discovered one Garmin pedal from our bicycle was missing and the other was damaged. The bicycle had been packed by the moving team. We are still seeking a proper resolution.
We paid, but the delivery situation still became chaotic and was delayed. This happened while our family was dealing with a bereavement and funeral. Instead of clear coordination, we were passed between different people and offices and had to keep chasing updates ourselves.
This was never clearly raised during survey or packing. The timing and manner of this demand were deeply unreasonable. We were contacted late at night and felt pressured to pay in order to avoid further delay to delivery.
Context-Bench evaluating the performance on models for Filesystems and Skills. It measures an LLM's ability to manage its own context window, deciding what information to retrieve, load, and discard to solve long-horizon tasks.
- Filesystem: Evaluates how well agents can chain file operations, trace entity relationships, and manage multi-step retrieval.
- Skills: Evalutes how well agents can discover and load skills to complete tasks.
Great work by @Letta_AI. Link and Leaderboard below 🤗
A 100% automated QA team that works 24/7:
1. Write your test in plain English
2. AI generates the test cases
3. Web agents execute the tests in parallel
4. Live browser preview with everything that happens
Try this for free in your project.
I reverse-engineered Claude Code's internal protocol.
Now you can spawn and orchestrate agents from TypeScript.
No SDK. No -p flag. Full programmatic control.
OSS below 👇
https://t.co/7f6GNVKWvr
I think one of the most underappreciated findings in AI engineering is what this paper calls the "Grep Tax."
First, they ran nearly 10,000 experiments testing how agents handle structured data, and the headline result is that format barely matters.
But here's the weird finding: a compact, token-saving format they tested (TOON) actually consumed *up to 740% more tokens* at scale because models didn't recognize the syntax and kept cycling through search patterns from formats they already knew.
It's one of the reasons my preferred formats are XML and Markdown. LLMs know those really well.
The models have preferences baked into their training data, and fighting those preferences doesn't save you money. It costs you.
The other finding worth sitting with: the same agentic architecture that improves frontier model performance actively *hurts* open-source models. It seems that the universal best-practices guide for AI engineering may not exist.
New paper on how to finetune any multiagent system on any task.
They have used AI feedback as per-action process rewards to solve credit assignment and sample efficiency without needing expensive rollouts.
Wild.
By far the most complete Claude Skills repo yet 🤯
@Composio’s Awesome-Claude-Skills packs 100`s of ready-to-use workflows:
↳ PDF tools, changelog generation
↳ Playwright automation
↳ AWS/CDK tools, MCP builders
... and much more!
Free and open-source.
Repo in 🧵↓
The playbooks skills directory looks a bit more diversified now it's sorted by trending skills 📈
Popular skills this week:
- bird by @openclaw
- prd by @ryancarson
- multi-pr-preview by @dyad_sh