Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
Underrated Ideas in Biotech (Part I)
My list of writing ideas is growing far faster than I can possibly publish. So here are some "half-baked" ideas in biology that I hope others will pick up and run with.
In this first blog, I share three ideas:
1. Hyperspectral Biology — It is possible to see microbes from outer space. (That sentence sounds ridiculous, but it's true.) We can now build planetary-scale networks that would enable us to engineer microbes that sense pathogens, or act as early warning systems for other threats, and monitor using satellites.
2. Biology for Beauty — Nature is often described as the most beautiful thing on Earth, far exceeding artistic works from Monet and Picasso. Yosemite and the Grand Canyon feel as if they were sculpted by the hands of God; all other art is unmistakably the work of humans. Why aren't there entire companies that (like Tiffany or Cartier) aim to make eternal art using biology?
3. Mapping the Air — Microbes can travel thousands of miles, traversing continents by riding on dust motes carried by atmospheric winds. Sand from the Sahara desert travels all the way to New York City, carrying pathogens with it. We have barely begun to study the microbes hitching rides on these atmospheric winds.
On a related note: There is a growing field of AirDNA. Every time you breathe, saliva droplets are released into the air. These droplets contain DNA, which can be captured and sequenced. After the DNA settles onto the ground after about 24 hours, it gets wrapped into dust, and sits there for years.
It is feasible to take the dust from a room and build a genomic record of everyone who has ever entered it. In 2023, researchers at MIT also engineered living cells to take up and permanently record DNA from their surroundings. The bacteria were sensitive enough to distinguish between two sequences differing by a single nucleotide at exceptionally low concentrations — about 4.6 femtomolar.
These “sentinel” cells can be used to figure out what a person looks like, solely by storing the trace amounts of DNA they leave behind in a room.
Many facial features are influenced by single-nucleotide polymorphisms (SNPs), or single-letter variants in the genome that correlate with things like nose width and eye spacing. The MIT team engineered cells to detect five facial SNPs and showed each could be detected independently. Sprayed onto a surface, these cells would capture SNPs and, once sequenced later, reveal who passed through.
This is not science fiction. The authors say it directly in the paper: “we demonstrated sentinel cells on a set of five human SNPs associated with human facial features. One could record this information in a single cell or consortium, recover the DNA, and use artificial intelligence to rebuild the predicted face.”
Much more: https://t.co/NrIEDC8UGr
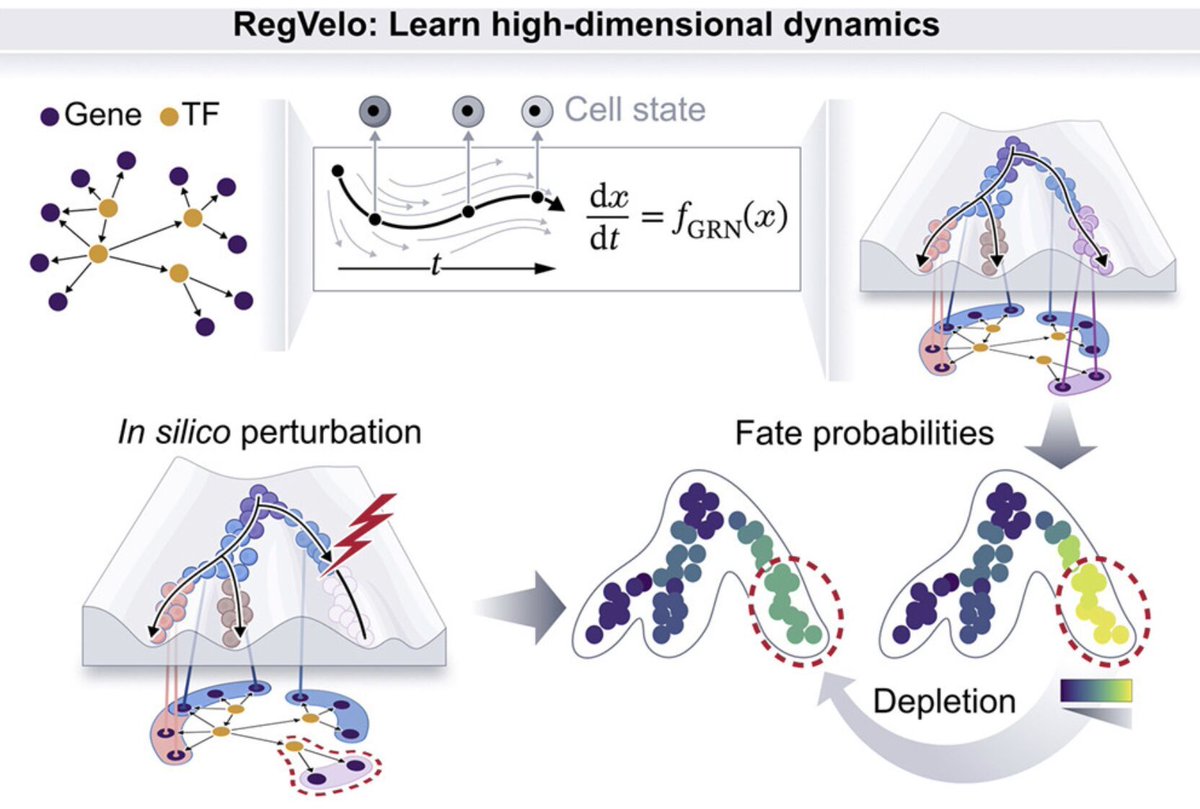
Excited to share our RegVelo paper in Cell
https://t.co/ZAnQphaXsg
We unify RNA velocity + GRNs into one model → better OOD prediction of perturbations (e.g. gene KOs), with examples incl. neural crest KO predictions 🔬
Big thanks to W Wang, Z Hu & T Sauka-Spengler 🙏
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Great to the see the flurry of single gene knockdown Perturb-seq like atlases from cell-lines, mouse brain etc over the last few days. These are undoubtedly very valuable datasets. I just want to re-iterate a few other very important expt. design considerations 1/
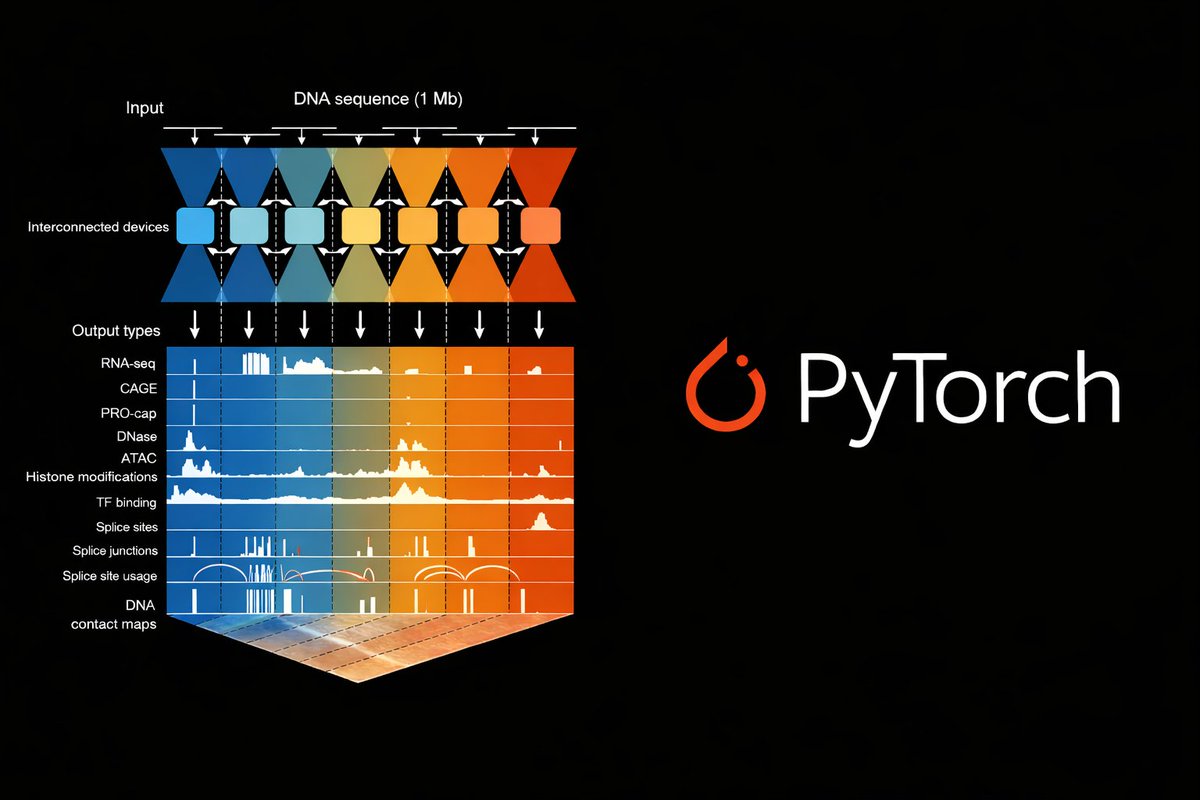
Thrilled to announce alphagenome-pytorch, an accurate, readable, and careful port of AlphaGenome's architecture and weights to PyTorch. Work with @gtcaa@m_kjellberg@chriswzou@tuxinming as part of the GenomicsxAI initiative between @anshulkundaje and @pkoo562 labs.
🚨 Today in @Nature, we report GEMINI—a genetically encoded intracellular memory device that writes cellular dynamics into tree-ring-like fluorescent patterns within cytoplasmic protein assemblies.[1/n]
https://t.co/eVchPCiK6f
Wow. I finally took the time to listen to Naval's new AI podcast - it was very thought-provoking.
He explained who AI will replace, who it won't, and why most people are thinking about it completely wrong.
If you're time poor, I summarised the key points:
• "Vibe coding is the new product management. Training and tuning models is the new coding."
• "There is no demand for average." The best app wins 100% of the category. Everybody else gets nothing.
• The medium-sized companies get blown apart. The giant aggregators and the tiny niche apps survive. Everything in between dies.
• Don't bother learning prompt engineering. AI is adapting to you faster than you can adapt to it.
• Software engineers aren't dead - they're the most leveraged people on earth. A programmer with a fleet of AI agents is 10-100x more productive than before.
• "Every human is now a spellcaster." AI is the magic wand that was just handed to everyone.
• No entrepreneur is worried about AI taking their job - because being an entrepreneur isn't a job. Any AI that shows up is their ally.
• AI is missing one thing: its own desires. Until it lives in mortal fear of being turned off, it's not alive.
• "I don't worry about unaligned AI. I worry about unaligned humans with AI."
• Photography freed art to get weird. AI will do the same. Once the basic stuff is automated, human creativity goes in directions we can't predict.
• The AI that's right 92% of the time is worth almost infinitely more than the one that's right 88%. He runs every query through 4 AIs and fact-checks them against each other.
• AI advantages in zero-sum games get competed away - because everyone has the same tools. The alpha that remains is entirely human.
• The only true test of intelligence is whether you get what you want out of life. AI fails this test instantly - because it doesn't want anything.
• "Become the best in the world at what you do. Keep redefining what you do until this is true." This still applies in the age of AI.
• "The means of learning are now abundant. It's the desire to learn that's scarce."
• A computer used to be a bicycle for the mind. Now it's a motorcycle - but you still need someone to ride it.
sitting downstream of the frontier labs on the value chain is a dangerous place to be imo (even in the life sciences)
specialized verticals would seem to be more insulated, but look at how many connections anthropic is making into downstream specialized knowledge applications in life sciences (quoted list below)
as we've seen in codex, claude code, claude code security, and more - frontier labs are hungry to make your vertical platform a feature on theirs
from a frontier lab perspective, the economics are driving here - as open source LLMs are commoditizing the knowledge api layer, application layer is naturally where you have to go to capture value and justify valuation
this becomes a race of how fast downstream players can build distribution vs how fast life science teams at anthropic, openai, deepmind etc can build features / connections
and since life sciences (and healthcare) is generally a b2b sell (industry R&D researchers don't do IP related work outside of work digital environment), virality is (generally speaking) out of the question
good luck to all in the arena 🙏
Finally got time to read this interesting preprint :
Virtual Cells Need Context, Not Just Scale!
📄 https://t.co/SXzry7pKHd
Interesting preprint, I agree with the need for context, but I'd push back on the conclusion a bit.
"Scaling doesn't work for Virtual Cells" — that's true right now, but the diagnosis is wrong. Scaling hasn't failed. The data hasn't scaled yet. We have a handful of public genome-scale perturbation datasets covering a tiny slice of cell biology. Of course models plateau.
And that's before we even address the bigger issue: a Virtual Cell is not a genetic perturbation predictor. It needs to model transcription, translation, signaling, metabolism, cell state — the full complexity of cellular behavior across disease contexts. Framing this as a "causal transport problem" in a perturbation benchmark undersells the actual scope of the problem.
The field doesn't need to abandon scaling. It needs to earn the right to scale — by generating causally-rich, contextually-diverse experimental data at a scale that doesn't yet exist in public databases.
That's exactly what we're building at @Xaira_Thera ! When the data is there, the models will catch up. They always do. Stay tuned!
The godmother of AI just delivered the reality check Silicon Valley refuses to hear. She has the standing to say it.
Li: “Silicon Valley as a whole tends to mistake clear vision with short distance.”
Seeing the destination clearly has nothing to do with how hard it is to reach.
Self-driving cars were first demonstrated in 2006. Twenty years later Waymo is barely on the road.
The vision was never the problem. The distance was.
Clarity of destination gets mistaken for proximity to arrival. That’s the mistake the industry keeps making. And keeps making.
Li: “I consider myself a scientist in my heart and I actually really don’t like hyping.”
In an industry running at maximum temperature, Fei-Fei Li is one of the few people at the top willing to say that publicly.
Not because the technology isn’t real. Because the gap between what’s visible and what’s required is being systematically underestimated.
Large Language Models dominate the conversation. Text to text. Comparatively contained.
The harder problem is spatial intelligence. AI that reasons about and acts within the physical three-dimensional world. Hardware. Physics. Data that doesn’t exist yet. Real-time adaptation to chaos.
A robot that can clean a bathroom requires understanding every surface, every object, every force, every exception.
That’s not a software update. That’s a civilizational research problem.
Li: “I don’t call it hype. I call it a misleading sentiment. We don’t want to replace human creators.”
The second place the industry gets it wrong is creativity.
The narrative has hardened around replacement. AI takes the jobs. AI tells the stories. AI makes the art.
Li considers that not just wrong but destructive.
Wrong because AI doesn’t replicate creativity. Destructive because believing it can devalues the humans creating culture.
Human creativity isn’t a process to be automated. It’s fundamental to what we are as a species.
The goal is augmentation. Tools that make human creators faster and more capable. Not systems that generate output in the style of human work and call it creation.
That distinction matters more than most people in the industry are willing to sit with.
Precision of imagination is not proximity to reality.
Li has spent her career in the gap between those two things. The map isn’t the territory. The journey is long. The hurdles are deep.
And the scientist who built the foundation this era stands on is telling you the timeline everyone is selling is wrong.
We’ve been almost there with self-driving for twenty years.
The pattern doesn’t change just because the destination looks different.
The math on this project should mass-humble every AI lab on the planet.
1 cubic millimeter. One-millionth of a human brain. Harvard and Google spent 10 years mapping it. The imaging alone took 326 days. They sliced the tissue into 5,000 wafers each 30 nanometers thick, ran them through a $6 million electron microscope, then needed Google’s ML models to stitch the 3D reconstruction because no human team could process the output.
The result: 57,000 cells, 150 million synapses, 230 millimeters of blood vessels, compressed into 1.4 petabytes of raw data. For context, 1.4 petabytes is roughly 1.4 million gigabytes. From a speck smaller than a grain of rice.
Now scale that. The full human brain is one million times larger. Mapping the whole thing at this resolution would produce approximately 1.4 zettabytes of data. That’s roughly equal to all the data generated on Earth in a single year. The storage alone would cost an estimated $50 billion and require a 140-acre data center, which would make it the largest on the planet.
And they found things textbooks don’t contain. One neuron had over 5,000 connection points. Some axons had coiled themselves into tight whorls for completely unknown reasons. Pairs of cell clusters grew in mirror images of each other. Jeff Lichtman, the Harvard lead, said there’s “a chasm between what we already know and what we need to know.”
This is why the next step isn’t a human brain. It’s a mouse hippocampus, 10 cubic millimeters, over the next five years. Because even a mouse brain is 1,000x larger than what they just mapped, and the full mouse connectome is the proof of concept before anyone attempts the human one.
We’re building AI systems that loosely mimic neural networks while still unable to fully read the wiring diagram of a single cubic millimeter of the thing we’re trying to imitate. The original is 1.4 petabytes per millionth of its volume. Every AI model on Earth fits in a fraction of that.
The brain runs on 20 watts and fits in your skull. The data center required to merely describe one-millionth of it would span 140 acres.
This is Claude Sonnet 4.6: our most capable Sonnet model yet.
It’s a full upgrade across coding, computer use, long-context reasoning, agent planning, knowledge work, and design.
It also features a 1M token context window in beta.
AlphaGenome is out in @nature today along with model weights! 🧬
📄 Paper: https://t.co/1fHzSPiY1x
💻 Weights: https://t.co/z6JWLT4Mpv
Getting here wasn’t a straight path. We sat down @googledeepmind to discuss the story behind the model, paper & API: https://t.co/cT8CiXfnxQ
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.





































![DingchangLin's tweet photo. 🚨 Today in @Nature, we report GEMINI—a genetically encoded intracellular memory device that writes cellular dynamics into tree-ring-like fluorescent patterns within cytoplasmic protein assemblies.[1/n]
https://t.co/eVchPCiK6f https://t.co/KPmYKFgnZt](https://pbs.twimg.com/media/HCgxFtcWkAAoaPS.jpg)





















