Prediction Markets | 2026.06 Update
With the World Cup just around the corner, there is growing anticipation around how prediction markets will perform.
YTD, the most notable changes have been:
1) $Kalshi’s stellar growth, with volume up roughly 90% from January to May; and
2) the growing divergence between $Kalshi and $HOOD’s prediction-market volume.
$HOOD used to represent roughly 50–60% of $Kalshi’s implied volume. That ratio has declined every month this year, falling to 22% by April 2026. $HOOD’s own prediction-market volume has been essentially flat YTD.
At first glance, one might assume $Kalshi is intentionally directing volume away from $HOOD and “cutting $HOOD out.” But this is more of a pull model than a push model. In my view, the issue is more likely on $HOOD’s side.
There are a few possible explanations.
First, $Kalshi has added new distribution and exchange partnerships, including Coinbase.
It is estimated that $Kalshi is now generating 60%+ of volume from its own platform/API, with the remainder coming from broker partners including $HOOD, Coinbase, PrizePicks, and others. $Kalshi went viral in 1Q, helped by strong momentum around the Super Bowl and March Madness.
Second, $HOOD’s current product supply is more limited, while $Kalshi has seen growth in non-sports contracts.
$HOOD remains very sports-heavy.
$Kalshi is also still sports-heavy, with sports representing roughly 80% of YTD 2026 volume. But $Kalshi’s non-sports share has increased from 9% in December 2025 to roughly 20% by March 2026.
----
Looking forward, $HOOD’s own prediction-market JV appears to have come online right before the World Cup.
Rothera recently went live, likely in late May or early June 2026, and $HOOD has now begun routing at least some prediction-market flow to Rothera. Rothera is operated by the $HOOD/SIG JV. $HOOD is the controlling partner, SIG provides liquidity, and MIAXdx provides the CFTC DCM/DCO infrastructure.
On unit economics, the current $Kalshi-distributed-through-$HOOD model appears to be: the customer pays 2 cents, with 1 cent going to $HOOD and 1 cent going to $Kalshi. With the new JV, $HOOD can technically capture more of the economics. The open question is whether $HOOD will keep that incremental margin, or use a better and cheaper product to acquire customers — consistent with how the company has competed in other verticals.
The World Cup will be an important test. It remains to be seen whether $HOOD becomes more aggressive on customer acquisition and product promotion around the event.
Medium to long term, $HOOD likely needs to broaden its prediction-market product offering beyond sports. If the company wants to close the gap with $Kalshi, distribution alone may not be enough. The product surface area needs to expand.
RSI, and whether “SOTA rotation” is about to break.
We’re used to SOTA rotating every few months. One lab pulls ahead, another catches up. Gemini was SOTA literally two quarters ago - feels like ages.
But RSI - recursive self-improvement - could change the competitive dynamics.
Dario on Dwarkesh’s podcast back in Feb: Dwarkesh challenged him - if recursive improvement is real, why does SOTA still keep rotating between labs? Dario’s answer was that, until very recently, the compounding advantage from AI-assisted AI research was still too small to really matter (but it's changing).
Since Jan/Feb, I’ve heard more and more researchers talk about RSI. The idea is simple: you build a better AI, that AI helps you build the next better AI, and the loop starts compounding.
It also explains part of the current “token-maxxing” dynamic - big co. spending $ billions on Claude Code just to keep up. And it helps explain the rumors that $OpenAI / $Google are reorganized around coding as the top priority.
Once that loop crosses a certain threshold, it starts to look like a true industrial revolution. Horses were never going to catch up with cars.
Comparing new S-1 vs. the previous version:
New S-1/A:
"Pursuant to these agreements, [Anthropic] has agreed to pay us $1.25 billion per month through May 2029, with capacity ramping in May and June 2026 at a reduced fee. After the initial three-month period, the agreements may be terminated by either party upon 90 days’ notice."
Old S-1:
"Pursuant to these agreements, the customer has agreed to pay us $1.25 billion per month through May 2029, with capacity ramping in May and June 2026 at a reduced fee. The agreements may be terminated by either party upon 90 days’ notice."
Basically a guaranteed 180-day contract (vs. min 90-day before).
At the same time, Elon seems to suggest it's a short-term (not full-term): https://t.co/bbiIUvGB2S
Other changes are summarized by Sawyer below: https://t.co/NOrQVQ66lq
IPO Supply vs. Demand for @SpaceX
Supply / lockup schedule -
Potential 9% unlock on the second trading day after 2Q26 earnings. That is roughly 2x the IPO float.
Demand / index buying schedule -
T+5: passive/index buying could equal ~7–10% of the float.
Total T+5 to T+15: passive/index demand could equal ~17–25% of the float.
Analysis (done by AI) -
Day 0–15: Thin float + passive buyers + price-insensitive demand likely create a sharp supply-demand squeeze.
Day 15–70: Air pocket. Index buying is mostly done.
Day 70–180: Digestion phase. More shares unlock, but a higher float may also force additional index buying.
Day 366: The 51% unlock is the biggest overhang. Actual selling could be much smaller if Musk does not sell.
Upside kicker: S&P 500 inclusion. If SpaceX becomes eligible after the float expands, S&P inclusion could create a second wave of passive buying.
Capex/FCF -> Debt/Leverage
Most ROI analysis on AI has focused on Big Tech capex and FCF.
But as more companies approach zero or negative FCF, I think the focus needs to shift toward net debt and leverage.
Given the ROI we are seeing from AI investments, I suspect companies will not pause spending simply because FCF hits zero - which is already happening for some names. The real constraint is more likely to come when companies (first) move into net debt, and (then) when leverage reaches a level that is no longer sustainable.
The complication is that many Big Tech companies now have meaningful off-balance-sheet obligations - finance leases, operating leases, JVs, purchase commitments, and cloud/infrastructure commitments. These may not show up as debt today, but they will likely become a drag on FCF over time.
-------------------
$GOOGL
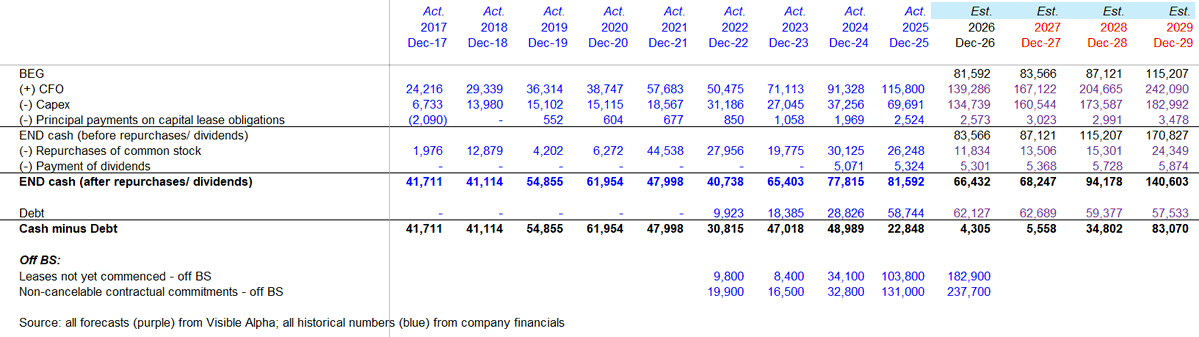
$GOOGL is relatively clean from an off-balance-sheet perspective, other than approximately $76B of leases not yet commenced.
Management has also said $Googl does not intend to move into a net debt position. Using consensus estimates from Visible Alpha and assuming $Google is willing to run down to roughly zero net cash, the implied maximum capex for FY27 would be approximately $280B, or roughly 50% YoY growth.
$GOOGL also has some buffers:
- ~$40B from the $80B equity raise (a $15B convert, $15B common equity, $10B private placement, and $40B ATM offering) (source: https://t.co/wAEEfPLeoo)
- ~$10B per year of dividends that could theoretically be adjusted.
-------------------
$META
$META has much larger off-balance-sheet commitments.
The two biggest buckets are:
1. Leases not yet commenced - $183B off balance sheet as of 1Q26
2. Non-cancelable contractual commitments - $238B as of 1Q26
Importantly, $42.25B is due in 2026 and $47.65B is due in 2027.
$Meta also disclosed several additional items that are worth tracking separately:
- A contingent obligation to purchase up to $14.72B of cloud capacity over five years
- April 2026 infrastructure contracts that increased non-cancelable commitments by another ~$24B
- Unconsolidated VIE exposure of $46.0B maximum exposure to loss tied to venture economics
It is impossible to know the exact future FCF, cash, and debt impact from these off-balance-sheet items. But directionally, $Meta looks much more likely to move into a net debt position once we account for these obligations - especially given the $42.25B due in 2026 and $47.65B due in 2027.
-------------------
Bottom line
The AI capex debate should not stop at reported capex and FCF. For companies with large off-balance-sheet commitments, the better question is: what does the balance sheet look like once these obligations start flowing through cash? On that basis:
$GOOGL still looks relatively clean and has the most balance-sheet flexibility.
$META has the most meaningful off-balance-sheet risk and is likely to move into a net debt position.
$AMZN has large commitments and seems certain to move into net debt.
Net-net, I actually (weirdly) feel better after going through this exercise.
1/ These companies still have some cash buffers. Even after adjusting for off-balance-sheet commitments, most are not getting to an unsustainable leverage position in the near term.
2/ This analysis is based on consensus cash flow from operations. Actual CFO could come in higher if AI ROI starts showing up more meaningfully.
3/ Companies still have some flexibility - not a ton, but some - if they decide to slow or pause share repurchases and dividends.
So the conclusion is not that Big Tech is immediately constrained. The better question is: how far can they push AI infrastructure spending before the balance sheet, not the income statement, becomes the constraint?
+++
Full analysis: https://t.co/2ZzO8YJ9xy
Rough guesstimates based on public information:
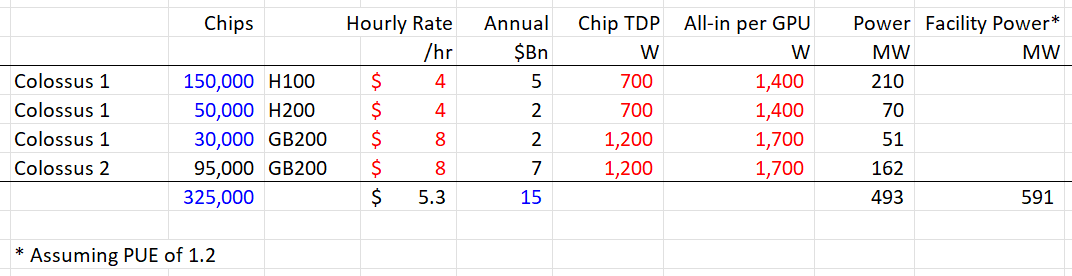
Using the numbers below, Colossus 1 = ~$6B annual rent.
That covers:
150,000 H100s
50,000 H200s
30,000 GB200s
Separately, $Anthropic’s total payment to $SpaceX is $15B per year, based on the SpaceX S-1 “$1.25B per month through May 2029, with capacity ramping in May and June 2026 at a reduced fee.”
This implies the payment attributable to Colossus 2 would be roughly $9B per year.
Assuming a price of $6/hour, that would imply $Anthropic is renting approximately 150,000–200,000 GB200-equivalent.
For context, Colossus 2’s total target capacity is reportedly 550,000 GB200/GB300s and 1GW of power.
I suspect Colossus 2 is not yet at full capacity. The S-1 says: “Our AI compute facilities, COLOSSUS and COLOSSUS II, collectively provide approximately 1.0 gigawatt of compute power.” We know Colossus 1 is ~300MW, which implies Colossus 2 is currently around 700MW.
So the implied math is:
Colossus 2 is leasing roughly one-third of its total compute capacity to $Anthropic.
Open to pushbacks/ discussions.
As disclosed in the revised S1: "in May 2026, we entered into Cloud Services Agreements with Anthropic PBC (“Anthropic”), an AI research and development public benefit corporation, with respect to access to compute capacity across COLOSSUS and COLOSSUS II. Compute capacity provided includes approximately 325,000 NVIDIA GPUs, backed by hyperscale-class CPUs, exabyte-scale storage and high-speed networking and interconnects purpose-built for AI workloads."
Assuming Colossus 1 is fully leased out, then the implied # of GB200/300 leased out from Colossus 2 would be 95k.
The weighted hourly rate to get to $15B/yr would be $5/hr.
Taking publicly available info on power per chip, the combined facility power would be ~590mw.
Implied revenue would be ~$25B per GW.
Taking ARKK's number below, SpaceXai spent $29b per GW building out that capacity.
https://t.co/ESs5FcGY3H
Per Elon: "This is a short-term deal." https://t.co/bbiIUvGB2S
All analysis based on publicly available information. Open to discussions/ pushbacks.
$CXMT S-1 Breakdown
Revenue run-rate already implies $ 30B+ annually, with guidance for ~$16B of revenue in 1H26.
Net margin is 60%+, on par with SK Hynix/ $MU .
DDR accounts for 30%+ of revenue, with the balance mostly LPDDR. No mention of HBM.
Fab utilization is approaching 95%+.
Purely illustrative: at 10x FY26 P/E, $CXMT would be a ~$200B market cap company - versus ~$800B to $1T for each of the leading three global memory players.
Source: all numbers from prospectus.
There's a growing narrative that AI token consumption is too expensive and too wasteful. Engineers are "tokenmaxxing." CFOs are nervous. Budgets are blown.
The concern isn't wrong. There is waste. But it misses the structural picture.
The Mental Model
AI spend = users × tasks/user × tokens/task × $/token
The first half — users and tasks per user — is ripping. Claude Code's adoption curve is steeper than Cursor's was at the same stage. Cowork is ramping faster than Claude Code. We're barely scratching the surface.
The tension lives in the second half: tokens/task and $/token. That's where optimization happens, and where the real debate gets heated.
Two Levers
1. Same work, cheaper tokens. Model routing is the highest-impact play. A routing layer that sends trivial tasks to Haiku and reserves Opus for complex reasoning can cut 60-80% of spend on eligible tasks. OSS models for commodity tasks — self-hosting Llama or Qwen for boilerplate — means zero per-token cost, swapped for GPU capex. Or the simplest strategy: wait. Token prices fall roughly 10x every 18 months.
2. Same work, fewer tokens. Prompt caching is low-hanging fruit — cache repeated system prompts, reads cost 10% of input price. Context window management — summarize history instead of re-sending full conversations. Thinking budget tuning — cap thinking tokens for simple completions, uncap for hard problems. And agent loop pruning, possibly the biggest single source of waste: most agents waste 50-70% of their tokens on redundant tool calls, retries, and pointless sub-agent spawns.
Who Optimizes What
Every layer of the stack targets different metrics. Infra ( $NVIDIA, $Cerebras, $Groq) optimizes tokens/watt and tokens/dollar.
Model providers ( $Anthropic, $OpenAI, $Google) optimize quality/token and thinking efficiency.
App layer (Cursor, Claude Code, Codex) optimizes cost/task and cache hit rates.
Enterprise buyers optimize cost/engineer and ROI vs. headcount.
Each layer's gains pressure the layers around it. Faster hardware forces providers to compete on price. Better models reduce the tokens apps need. Application routing erodes premium pricing. Enterprise CFOs demand all of the above.
Bear vs. Bull
The core question: does optimization compress AI revenue faster than new demand replaces it?
The bear case is real. Rationalization is the CFO's first instinct — when the budget blows, the reaction is "finally back inside the envelope," not "let's 10x usage." Model routing drops revenue per task 10-20x. OSS is closing the gap fast. Caching is pure token destruction: cache hit = zero revenue, no new demand generated. And thinking efficiency is self-cannibalization — if Anthropic improves extended thinking by 3x, billing for the same reasoning task drops by two-thirds.
The bull case is equally compelling. Current usage is cost-constrained, not demand-constrained. Companies blew their budgets and had to throttle. Drop costs 5x and every killed use case comes back. Today only coding is at scale — testing, documentation, code review, security auditing are all waiting for the economics. Penetration is still single digits. Agentic workflows are a token multiplier: a human-in-the-loop conversation runs thousands of tokens, an autonomous agent on a complex task runs hundreds of thousands. New modalities — vision, audio, video — are net-new demand that dwarfs text.
And Jensen Huang's framing: a $500K/year engineer should consume at least $250K/year in tokens. At $5K, you're dramatically under-leveraging AI.
Where This Lands
The optimizers will win every individual battle. Every caching trick, every routing layer, every pruned agent loop will work. Cost per task will drop dramatically.
But the number of tasks, the number of users, and the complexity of what gets delegated to AI will grow faster than efficiency compresses spend.
Token costs are going down. Token spend is going up. Both things are true, and they aren't in contradiction.
Full: https://t.co/ITcSbdkVWR
As AI shifts software from seat-based access to API-based workflows, what happens to professional info & research terminal companies?
First, customers add API spend while cutting seats. Then, vendors will likely reprice API higher, or moving toward consumption-based pricing?
Most businesses are not built around a world where one internal AI layer can serve an entire team...
E.g. Today - A hedge fund have 20 analysts, each with a @Bloomberg Terminal ($30K+ per year), or $600K+ annually. New Model - Buy 1 API key, pipe the data into an internal $Claude / LLM workflow. Cost fall by 50%+.
This is what AI really changes: it centralizes information retrieval. The value of the UI + search / query layer disappears.
And this goes far beyond finance. Anything below are at risk:
- historically sold by seat
- much of the value comes from search, retrieval, summarization, basic analysis, or light workflow
- the underlying data or functionality can be exposed via API
- the end user does not truly need the native UI
The key questions are:
-> Are customers paying for the interface or for the answer and the data? If just for the data, that is more exposed.
-> Do users actually live inside the product all day? If yes, more defensible.
-> Is the data truly proprietary or mainly an aggregation layer? Aggregators are more at risk.
-> And if you plug the product into Claude, does 80% of the value still remain?
More broadly, finance has always been strangely fragmented.
- @Bloomberg has real-time data and some consensus.
- @VisibleAlpha has the deepest consensus detail, but not all mgmt. guidance.
- @AlphaSenseInc is a strong aggregator for sell-side research and expert content.
- @tradingview has great charting, but no market caps or financials.
- the list goes on...
Maybe AI is finally the force that breaks those walled gardens.
The real risk is never expensive data. It is expensive UI.
Org Design in the Age of AI
I've spent the last few months talking to companies — startups to megacaps — about how AI is changing the way they work. Everyone is adding AI to their workflows. Almost no one is asking why the workflow looks that way in the first place.
+++
TODAY
Strip a company down and it's three things: people, hierarchy, and information flow. Hierarchy isn't really about authority. It's about information routing — the org is too big for anyone to see everything, so you install managers to aggregate, synthesize, and relay. Meetings, status updates, steering committees, QBRs — all information-routing mechanisms. They exist because moving knowledge between people is expensive.
AI makes it cheap.
Consider how products get built today. PM writes PRD. Design interprets it into mocks. Engineering interprets mocks into code, estimates "eight weeks," requirements change, PRD gets rewritten. Dev takes months. QA runs regression. GTM preps launch. Mid-sized feature: 3–6 months.
The bottleneck was never speed. It was translation cost. PM's intent → document → designer's interpretation → engineer's interpretation → QA's interpretation. Every handoff loses fidelity, requires alignment, generates wait time.
AI collapses the translation layers.
+++
AI ORG DESIGN
PM goes from idea to working prototype in a day. AI generates tests as code is written. An intelligence layer synthesizes customer signals and business metrics in real time — replacing the manager who used to aggregate that weekly.
This isn't about each role getting faster. It's the gaps between roles — handoffs, queues, alignment meetings — evaporating.
🔥 Implications:
Relay race → basketball game. Small squads, 3–5 people, all skills present, moving simultaneously. Most decisions stay in the squad.
Departments → capability atoms. Composable, independent capabilities — collections, identity verification, risk scoring — each combinable with others.
PMs become builders. Less time translating ideas for others, more time validating directly.
Middle management compresses. The survivors are the ones whose value was always judgment and coaching, not information routing.
QA embeds into dev. Quality becomes a guardrail, not a gate.
The system generates the roadmap. Jack Dorsey's example: a restaurant's cash flow tightens before a seasonal dip. The system detects it, packages a short-term loan with adjusted repayment, pushes it to the merchant — before they thought to look. No PM decided to build that. The system recognized the moment and composed existing capabilities.
Release cycles → continuous flow. Ship daily. Trade big-launch dopamine for relentless, quiet value delivery.
+++
The competitive moat shifts from execution speed to learning speed — how fast the org can absorb what AI makes newly possible and restructure around it.
Most companies are using AI as a faster horse. The ones that pull ahead will ask: what would we build if we designed this org from scratch today?
Full: https://t.co/ZWNECdHPzM
Quarterly Fact Check on Self-Driving | 1Q26
$Nvidia Alpamayo: The Android Moment
$Nvidia's AV stack has gone through three generations: V1.0 (50M params, rule-based decisions, single Orin), V2.0/Alpamayo (500M params, still Orin — powering Mercedes CLA's L2++ in SF this summer), and V3.0 (likely 2B params on Thor, with reasoning and test-time compute replacing brute-force imitation learning).
If it works, Alpamayo becomes the Android of self-driving — a licensable stack any OEM can deploy. That's the single most consequential variable in the medium-term AV landscape.
---
$Uber: Very Proactive; Hedged for Now
$Uber has 20+ AV partnerships. By 2026 year-end, multiple driverless partners should be live on-platform: $Waymo (Austin, Atlanta), $WeRide (Abu Dhabi, Dubai), $Avride (Dallas), $Nuro/Lucid (SF Bay), and $Zoox (Las Vegas, pending NHTSA exemption). The biggest dollar commitment is $Rivian's $1.25B deal — fleet exclusive to $Uber's platform.
Near-term, this neutralizes the bear case that AV supply is concentrated.
Medium-term, it's a "Jensen vs. Elon" question: Tesla robotaxi scaling is negative Uber; Alpamayo commoditizing the stack is hugely positive, because it multiplies supply partners.
---
Waymo: 1Q26 Update
Raised $16B at $126B in early February. 3,000+ robotaxis on the road, with the Magna plant in Mesa targeting 3,500+ by year-end.
---
$Tesla: Show-me Time
Launched driverless rides in Austin in late January — no safety monitor — but expansion has been muted. Musk acknowledged Tesla needs 10B miles for safe unsupervised driving; at current rates, that's July 2026 at earliest.
Seems the industry is pivoting to reasoning (both $TSLA and $NVDA Alpamayo): Musk has signaled a new FSD model that is “an order of magnitude larger” with more reasoning and reinforcement learning. Tesla AI head Ashok Elluswamy confirmed some reasoning capabilities already partially shipped in v14.2. The framing from the Q3 2025 earnings call: the car will reason about which parking spot to pick, drop you off at the store entrance, then go park itself.
Cybercab volume production targeted for April 2026.
+++
Full: https://t.co/ni3UEsfRqA
Waymo:
App Store (?) in the Age of Agents
When Steve Jobs launched the iPhone in 2007, there was no App Store. His plan was for developers to build web apps accessed through Safari. The App Store came a year later, designed for humans who browse, tap, and swipe. AI agents don't do any of that — they call APIs. The App Store is increasingly becoming a bottleneck in the age of agents. How might this change?
The App Store bundles four things: discovery, distribution, trust, and payment. It was built for humans who browse, tap, and swipe. AI agents don't do any of that — they call APIs.
That's what $MCP is. $Anthropic released it in late 2024 as an open standard for agents to connect to any service. $OpenAI adopted it within months. $Google followed. By end of 2025, it was donated to a neutral foundation. The connection layer is now open infrastructure — like HTTP. No one can tax it.
So where does the money go? You have to unbundle the App Store into three layers:
1/ Connection (MCP) — solved, open, commoditized.
2/ Discovery — the real war. When you say "book me a restaurant," how does the agent choose which one? Today you browse Google and pick from 10 results. In the agent era, the agent picks for you — you may never see alternatives. Whoever controls the recommendation algorithm holds enormous power. This is $Google Search on steroids: agents don't just show options, they complete the transaction. Conversion rate approaches 100%.
3/ Payment — greenfield but potentially the most lucrative. If agents handle daily micro-transactions across dozens of services, someone becomes the payment aggregator. This is $Apple's real lesson: App Store revenue was never about discovery. It was about forcing every transaction through Apple's payment system at 30%.
The investment question: will these three layers consolidate into one platform (like Apple), or fragment across specialists?
-> More services build MCP adapters. Agent tool ecosystems grow. But agents are still limited — users mostly specify which services to use.
-> Agents get smart enough to choose services autonomously. “Who decides the ranking”
-> Agents handle significant daily transaction volume. A unified payment infrastructure becomes necessary. Whoever holds that position holds the minting rights of the agent economy.
Who’s Actually Trading? A Breakdown of US Equity Market Structure
Asked Claude to run some analysis - US equity trading volume can be roughly decomposed into a few segments:
Systematic (majority of which is HFT): 50%+. HFT doesn’t really take directional bets — it mostly acts as a momentum amplifier. Mid-frequency systematic strategies, however, do take directional positions.
Retail: ~35%. This has roughly doubled over the past few years.
Discretionary institutions: 5–10%.
Passive / index rebalancing: the remainder.
This split looks vastly different on a per-asset basis. Each stock has its own microstructure — can imagine TSLA’s daily volume being predominantly retail-driven, while AAPL skews more institutional.
--
Asked Claude to run some back-of-the-envelope analysis to gauge the real footprint of multi-manager platform shops:
Platform shops’ equity books can account for ~5% of total market trading volume. They run ~$150B of AUM, but gross equity exposure is around $700B given high leverage, with high turnover on top of that.
Single-manager hedge funds account for ~2% of total market trading volume.
As platform shops have scaled in AUM, the vast majority of today’s institutional trading volume has become pod-driven. This explains the crowdedness — and the violent degrossing episodes — we increasingly see in price action.
Layoffs Impact -
Lots of chatter around reorgs & layoffs recently. I wanted to build a simple framework to understand the financial impact.
All scenarios below are purely hypothetical. Key Observations:
1/ SaaS is far more sensitive than Big Tech
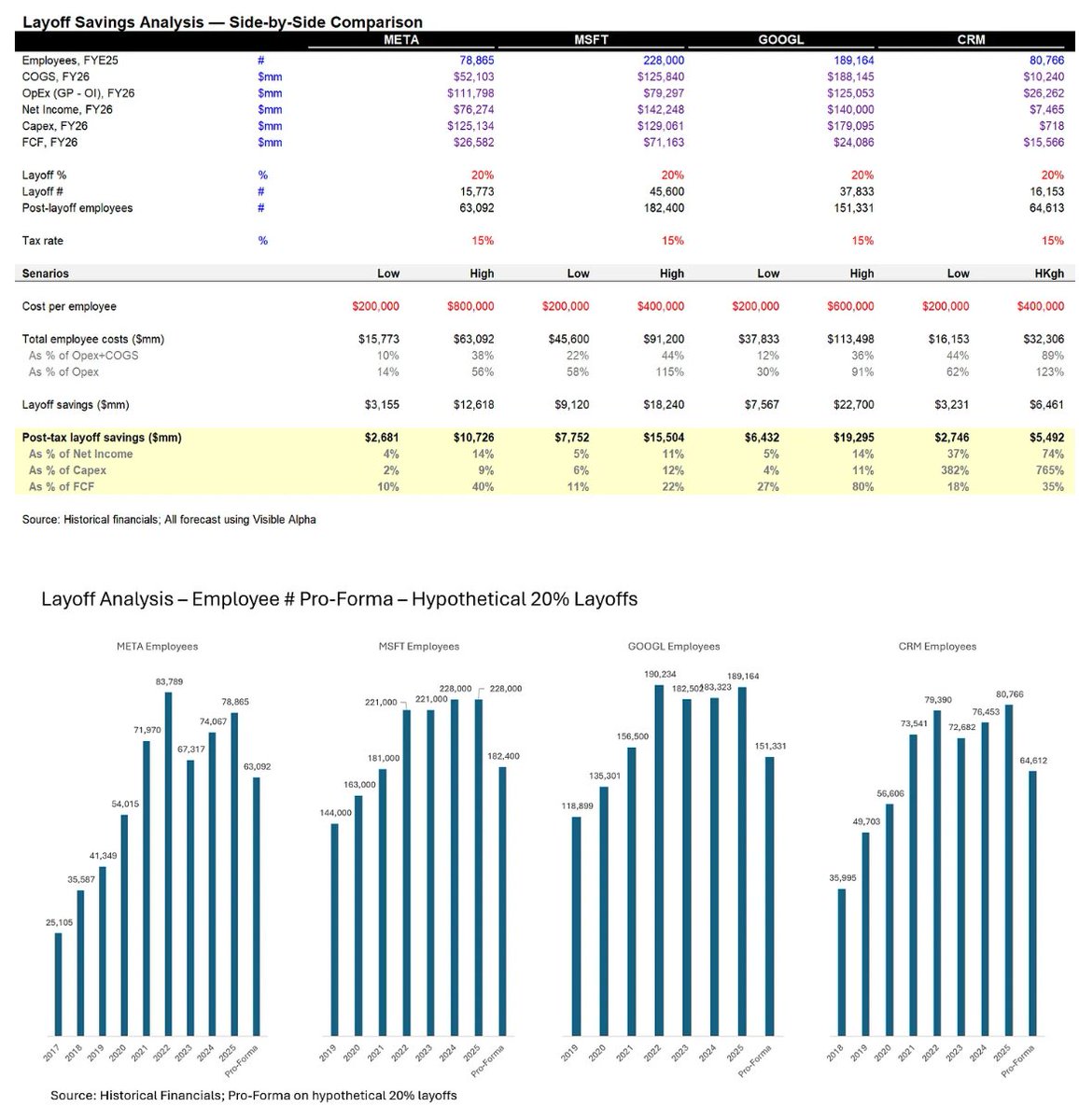
Using $CRM as a reference (and likely representative of other SaaS names):
Assume ~$200k average salary per employee
Layoffs can drive:
- ~40% uplift to GAAP EPS
- ~20% uplift to FCF
This is meaningful. Labor is a much larger % of the cost base, so cuts flow through cleanly.
2/ Big Tech: smaller EPS impact, larger FCF leverage
For $META, $MSFT, $GOOGL:
A 20% layoff implies:
- ~5–15% uplift to EPS
- Significantly larger impact on FCF
The key difference: these companies are already highly profitable, so incremental savings show up more clearly in cash than in earnings.
Take $GOOGL as an example: At $200k–$800k salary per employee:
- FCF could increase by ~30–80%
- Equivalent to enabling ~10% incremental CapEx deployment
In other words, layoffs don’t just boost margins - they can directly fund the AI capex cycle.
---
To ground the analysis, here are the base assumptions:
- 20% workforce reduction
- 15% tax rate
- $200k–$800k salary range per employee
Full analysis: https://t.co/c8GjEZSEPz
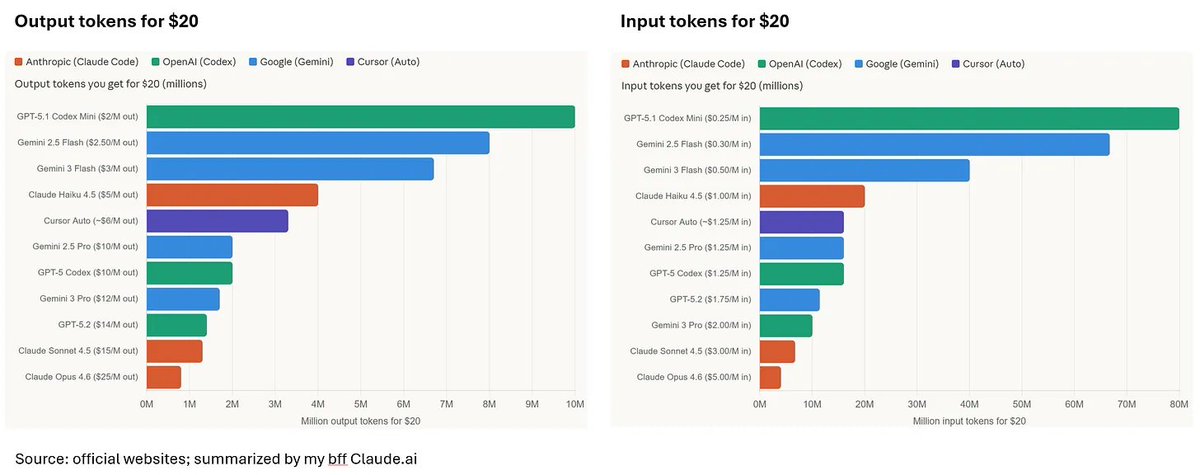
Stop Counting Tokens. Start Counting Tasks.
There's a lot of chatter right now about "how many dollars of tokens I burned on Model A" versus "how many tokens I burned on Model B." Firms are asking developers to hit a certain spend or token quota per month. But this framing is broken — it's a bragging game, not a real productivity proxy.
The metric that actually matters isn't $ per token. It's $ per task.
---
1/ $ per Token — The Number Everyone Quotes
Most people access coding models through subscriptions — $20/month at the entry level, $200/month at the pro tier. But subscription plans don't tell you how many tokens you actually burn.
So let's use API pricing ($ per input token, $ per output token) as a proxy:
Looking at this, you might conclude that @claudeai Opus 4.6 is 12–80x more expensive than GPT-5.1 $Codex Mini. That conclusion is wrong.
---
2/ Token per Task — The Hidden Variable
Do different models consume different token counts for the same prompt? Yes — significantly. This is what makes naive $/MTok comparisons misleading. Three layers:
A. Tokenizer differences (~5–15% variance).
@OpenAIDevs , @AnthropicAI , and @GoogleAI each use different tokenizers. The same code file might be 1,000 tokens on one and 1,100 on another. Smaller gap for code than natural language.
B. Output verbosity (2–5x variance).
For the same "refactor this function" prompt, a capable model might produce a tight 200-line solution. A cheaper model might produce 400 lines of verbose, wrong code — then require follow-up turns that re-send your entire context. Conversely, smarter models sometimes over-explain with comments, inflating output tokens.
C. Hidden thinking tokens (3–10x the bill).
Models with reasoning modes — @claudeai 's extended thinking, @OpenAI 's o-series, @GeminiApp 's thinking mode — burn chain-of-thought tokens you never see but still pay for. A request producing 500 visible output tokens might actually consume 5,000 once you include the thinking budget, billed at standard output rates
D. Context accumulation (major for agentic coding). Tools like Claude Code and Codex work in multi-turn loops — each step re-sends the growing conversation history plus file contents. A 10-step task might start at 5K input tokens and end at 80K+. This is why Anthropic reports average Claude Code usage around $6/dev/day (https://t.co/mcwEw4t8Qi Blog). Prompt caching helps: cache reads cost only 10% of standard input price, saving up to 90%
---
3/ $ per Task — The Metric That Actually Matters
$/MTok is the unit cost. But total tokens per task vary so much across models that a model charging 2x per token might actually be cheaper per completed task if it gets the answer right in fewer turns.
The real metric is cost per successfully completed coding task — and that's model-quality-dependent, which is exactly why nobody publishes it cleanly.
Firms mandating a monthly AI spend should stop treating token burn as the KPI. Ask your developers which models are most efficient in $ per task. They're the ones running these tools every day. They know everything.