Sup AI is live on @ProductHunt 🚀
"Which AI model is the best?"
Wrong question.
The best model isn't a model. It's an orchestra.
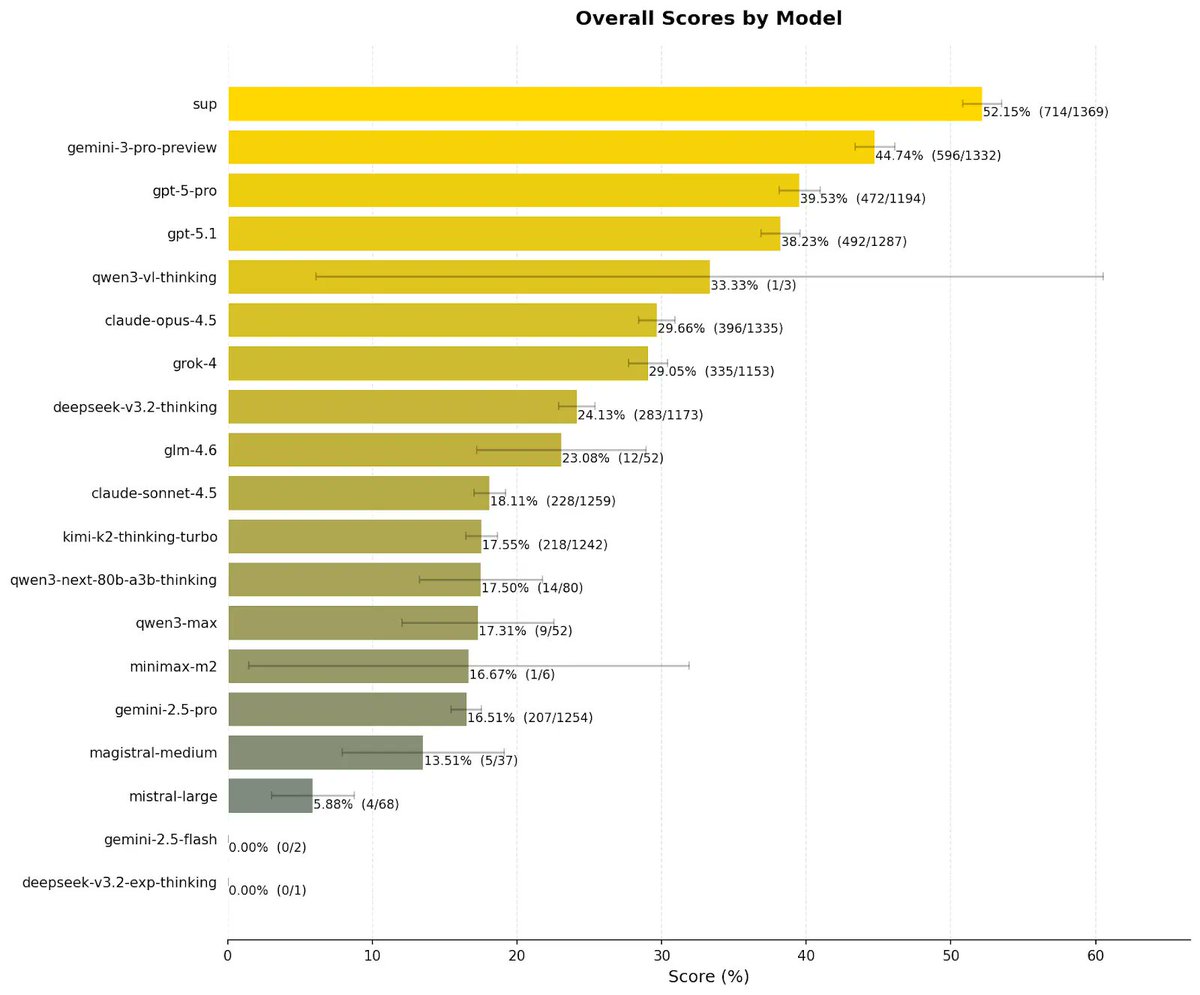
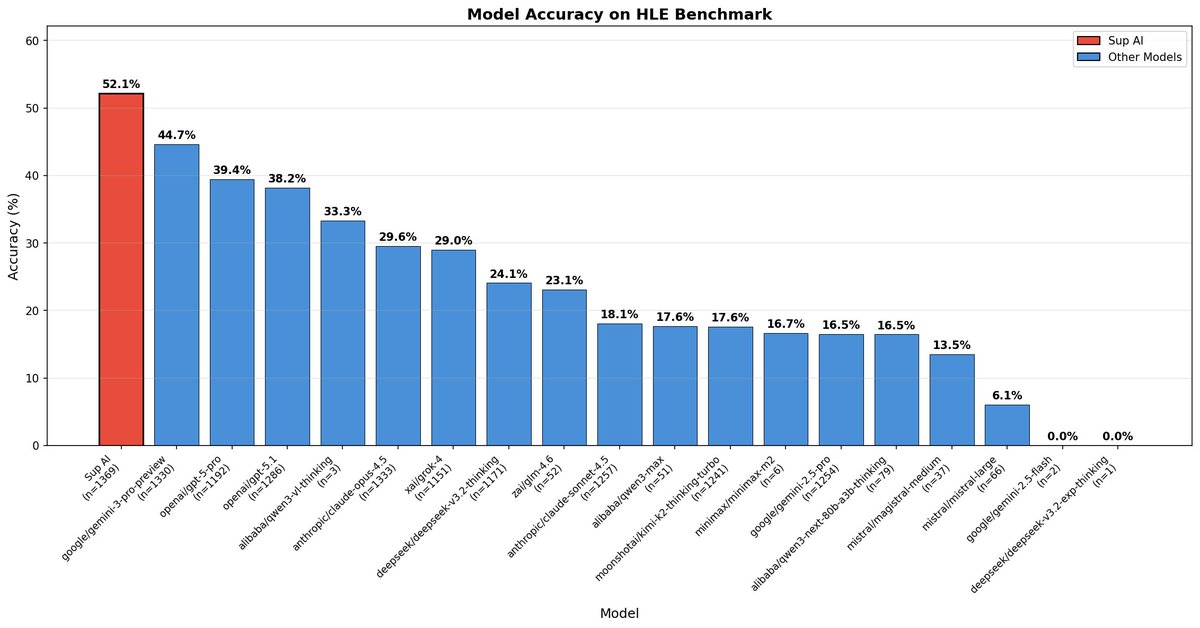
Sup AI runs 9 frontier models in parallel and synthesizes their answers→ 52.15% on HLE benchmark (without the help of tools).
→ Multi-model consensus (up to 9 models)
→ Ensemble RAG with live web + your files
→ Every claim cited
$10 free credit to start
20% off with code: PRODUCTHUNT
Links below 👇
Sup AI just launched on @ProductHunt
Sup combines multiple AI models and uses confidence scoring to give better answers with fewer hallucinations.
#1 on Humanity's Last Exam: 52.15%. Beating every individual model.
$10 starter credit to try it
https://t.co/TG4CU6yRR6
Did @OpenAI just silently kill top-20 logprobs for all models except GPT-5.4-nano? Setting `top_logprobs` to anything > 1 returns an error for the past 4-5 hours. Might just be their servers having trouble, but their status page indicates "No incidents" for their responses API.
@supabase@supaihq@kiwicopple@AntWilson Update: Supabase support was able to recover the database! The site is back online and the data is safe. The Supabase dashboard is still completely bugged out, but the critical infrastructure is running again. Appreciate the support team getting this recovered.
@supabase, @supaihq's production Supabase is down, and nobody at Supabase is responding. You guys did something strange, and the entire database was wiped. Then we tried a PITR, and it said the restore failed. The project has been inaccessible. Can anybody help?
Still zero response on ticket #SU-342355. Production is completely down and we are facing permanent data loss. We have escalated this to Hacker News.
@kiwicopple@antwilson@supabase please, we urgently need an infra engineer to look at this before the volume is overwritten.
https://t.co/RYH8Gg6qXA
Sup AI whitepaper is live on the methodology behind 52.15% on HLE:
• 3 correct answers synthesized when EVERY model failed
• Grok 4 (29%) uniquely solved 16 Qs vs GPT-5 Pro's 9 (40%)
• Low correlation pairs >high accuracy pairs
• 58.44% theoretical ceiling w/ models
• 42% Qs unsolved by ANY model
• Full methodology, IQ curves, correlation matrices: https://t.co/EiKtyUOGzo
#AI #MachineLearning #OpenSource #AIResearch #EnsembleAI #AIOrchestration #HLE
@minchoi That's ~$950/month across 5 services. Sup AI is $200/month and includes all those models and more in one place. Save $750/month. https://t.co/8ysXKdNmFQ
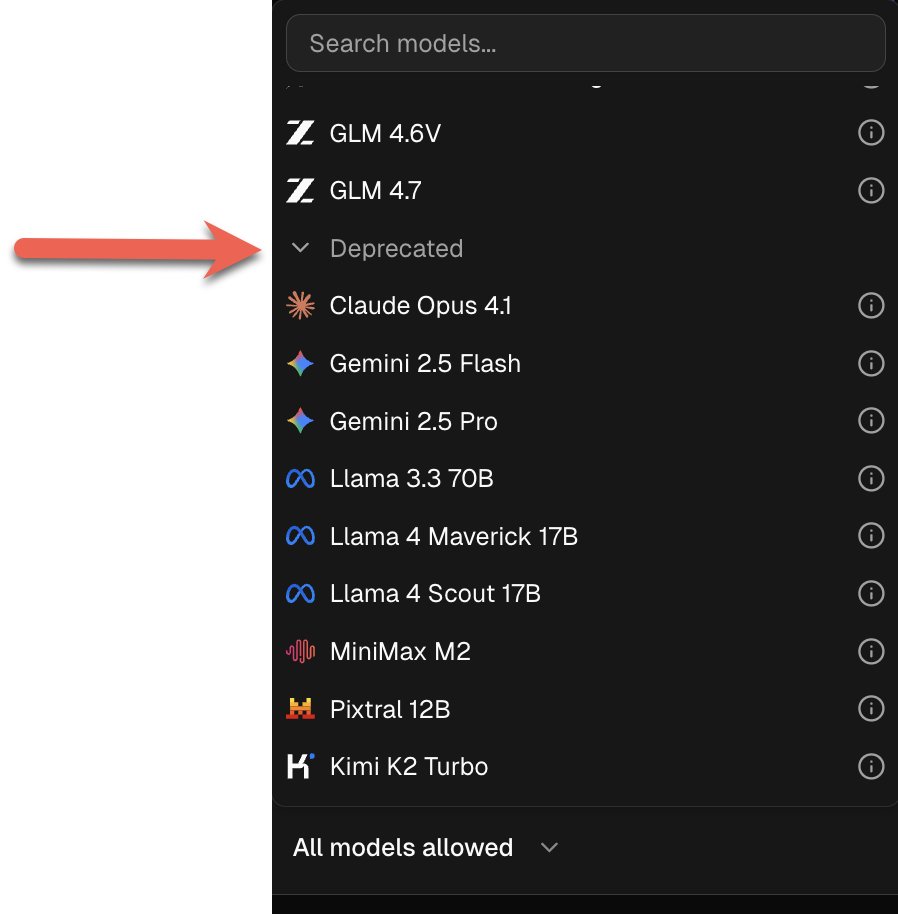
🗂️ Deprecated models are now accessible: Claude Opus 4.1, Gemini 2.5, Flash Gemini 2.5 Pro, Llama 3.3 70B, Llama 4 Maverick 17B, Llama 4 Scout 17B, Kimi K2 Turbo, Grok 4 Fast, Grok 4 Fast Reasoning, GPT-5,
GPT-5 Pro, GPT-5.1, GLM 4.5 Air, GLM 4.6, MiniMax M2, Pixtral 12B are back by request. Find them at the bottom of the model selector → click "Deprecated" to expand. Great for: specific personalities, fewer guardrails ⚠️ Not recommended for serious work as newer models outperform them.
We just launched the Sup AI Developer API
One endpoint → Multiple frontier models → Better answers
✅ Multi-Model Consensus: Combine outputs from Claude, GPT-5, Gemini, and more
✅ OpenAI compatible (2-line integration)
✅ 5 modes: fast → thinking → pro
✅ 52.15% on Humanity's Last Exam (SOTA)
✅ Self-healing tool calls
Get your API key → https://t.co/Lhlmabce9V
Full docs → https://t.co/upeMN88pyW
How it works:
Instead of betting on one model, Sup AI orchestrates multiple models and synthesizes their outputs.
auto mode picks the right approach. pro mode runs 9 models for mission-critical work.
You get consensus-driven answers without the infra headache.
Sup AI update: → Faster generation → More reliable → Terminate models mid-response (for when you can't wait for GPT-5.2 Pro to finish 🙂)
Also added GLM 4.7 and MiniMax M2.1 42 models. One interface. https://t.co/8ysXKdNmFQ
💯 Memory IS the lock-in.
That is why Sup AI decoupled memory from the model. Your memory is shared across all 42 frontier models -GPT, Claude, Gemini, Grok, everything. Switch freely; your context follows you.
Great suggestion - now we just need to build that import feature 👀
Single-model AI is broken.
You're paying for 5 subscriptions, manually A/B testing outputs between tabs, and praying the "best" model doesn't hallucinate on the task that matters.
We orchestrate 40+ frontier models instead. Auto-route. Auto-validate. One platform.
Result: 52.15% on Humanity's Last Exam. +7.49 points ahead of every solo model.
The future isn't picking the best violinist. It's conducting the whole damn orchestra.
https://t.co/qEuRVv2lsF
#AI #AIOrchestration #SupAI #LLMs #LLMCouncil
The AI race has a new winner every week.
OpenAI → Gemini → Grok → Claude → DeepSeek
Betting on one model? You've already lost.
@SupAIHQ orchestrates 40+ frontier models, achieving 52.15% on Humanity's Last Exam:
https://t.co/l8FuQDRfxI
Don't pick a rat. Own the racetrack.
#AI #Orchestration
New SOTA on Humanity's Last Exam (HLE)
We have achieved 52.15% accuracy on the world's hardest open-source AI reasoning test, setting a new benchmark record.
Sup AI is now outperforming every individual frontier model, including Gemini 3 Pro Preview and GPT-5 Pro.
Our lead over the next best model? +7.49 points.
Check the full evaluation & code:
https://t.co/l8FuQDRfxI
#AI #MachineLearning #HLE #SupAI