Some updates on what we've been working on:
> A new agent harness has been getting coded for more than 110+ hours to upgrade the architecture of Spark
This will be a huge improvement that will positively impact all foundational code, tool calls, conversations, and more
> There are over 3000 open source PRs submitted for the Spark Compete: Hunting Bugs & Goblins
With the community helping to improve Spark and all its repos, the product is getting in shape, not just via solo-building anymore, but in a community-oriented way
> Spark Compete's first event will end tomorrow (07.06) at 11.59 PM UTC. All PR submissions done until that time will be reviewed, after the event ends, too.
Since we are now deploying the new harness, we paused reviews and merges to deploy that, which is between staging and production.
It has taken much longer than we expected, even with AI writing the whole code. But once this is done, the core of Spark will be much more solid.
> Once the new installer gets deployed with the new harness, reviews/points/merges will continue.
After the product polishing reaches the stage we like, we will double down on content, grants, incubations, token utilities surrounding these, and creative ventures around NFTs that will add another extra utility to the token, too.
Getting to this stronger agent OS will make every other effort have more impact.
> Last but not least, an educational content group will be formed around Spark to reward good content that drives greater adoption of the product.
Product polishing first. And then the next stages will get more exciting.
P.S. Below, you can see how our new harness operates at its core: a unified governor for better context capture during conversations and tool calls with a more reliable source of truth, and observability systems everywhere.
As Spark has been expanding its repos and tools, getting this done correctly became paramount. Can't wait to ship it soon!
Spark r24 is here and here is the changelog:
## spark-compete
- Added durable R24 scoring docs, ledgers, dry-runs, and guarded apply scripts.
- Added separate scoring lanes for missing rows, packet audit, status evidence, private score, public publish, adopted repair, identity correction, and final leaderboard apply.
- Added R23 scoring methodology docs so future leaderboard passes are faster and more consistent.
- Fixed final R24 team attribution issues before leaderboard publish.
## spark-cli
- Refreshed R24 registry pins and installer metadata.
- Added `spark search --json` for agent-friendly registry lookup.
- Improved JSON success contracts, including `ok` behavior for compile summaries.
- Improved provider doctor errors for HTTP, network, and invalid JSON failures.
- Improved malformed or missing `spark.toml` handling with clearer CLI errors.
- Improved `spark init` TOML escaping.
- Improved browser-use JSON path redaction.
- Hardened support bundle and doctor-report privacy handling.
- Tightened URL policy around trailing dots and metadata-host blocking
## spark-telegram-bot
- Improved local Spark service intent detection to avoid false positives.
- Improved Telegram completion report handling so reports do not end mid-report.
- Added safer sanitized warning behavior for delayed completion summary failures.
- Improved timeout/env validation for mission control, relay, voice bridge, LLM clarification, chip loop, and path loop settings.
- Added TTL/pruning improvements for long-lived mission/task caches.
- Improved operator docs for health polling and installed module paths.
## vibeship-spawner-ui
- Improved corrupted active-mission recovery with bounded inactive/corrupt state handling.
- Improved scheduler state robustness around corrupted schedules, crash recovery, next-fire calculation, and fallback saves.
- Improved mission-control and creator-mission state writes with temp-and-rename patterns.
- Improved HTTP/non-JSON error handling across scheduler, mission board, access lane, memory quality, and provider-runtime paths.
- Added many safe JSON parse guards across persisted provider results, mission state, skill manifests, dashboard snapshots, and event relay state.
## spark-researcher
- Improved external chip defaults so new chips use `~/.spark/chips` instead of Desktop-only paths.
- Improved missing-config JSON guidance and config-path redaction.
- Added timeout handling around researcher subprocess paths.
- Improved corrupted JSON/JSONL handling across memory, proposals, reviews, collective loaders, and failure status.
- Improved autoloop and adapter error clarity.
- Improved web-result and web-note response cleanup to avoid resource leaks.
- Improved atomic writes for trainer and trial queue state.
## spark-character
- Improved dash-family scoring and audit behavior with focused tests.
- Added bounded timeout behavior for lowest-tier evolution subprocesses.
- Treated live-search snippets and titles as untrusted quoted source text.
- Improved malformed YAML and malformed base chip handling.
- Improved provider error clarity when gateway responses are HTML instead of JSON.
- Improved live-search failure logging.
- Improved persona pointer cleanup and trait-mutator validation for NaN/Infinity deltas.
- Improved voice corpus loading for missing or malformed JSON.
## spark-voice-comms
- Rejected invalid, non-object, or oversized hook inputs before dispatch.
- Added strict `voice.transcribe` base64 validation.
- Improved unsupported Kokoro runtime handling with structured failure.
- Improved env parsing and env-read failure visibility.
- Improved malformed voice profile JSON handling.
- Improved Kokoro TTS speed validation.
- Improved provider and voice-transcribe error messages.
- Improved delivery trace safety and import-wrapper behavior.
## spark-personality-chip-labs
- Improved registry assign/default errors so missing targets list installed personality IDs.
- Improved active personality chip diagnostics by naming configured personality IDs.
- Added safer atomic JSON cache writes.
- Improved bridge staleness timestamp parsing.
- Improved empty voice-signature handling.
- Improved bridge cleanup with safer file unlink behavior.
## spark-domain-chip-labs
- Added or represented CLI usability improvements such as `--version`.
- Improved artifact-quality validation messages by naming allowed reviewer verdicts.
- Kept related changes gated where scoring or release proof was not ready.
## spark-intelligence-builder
- Improved Builder chip-hook privacy by removing local `.env` file paths from payloads.
- Improved auth-provider errors by naming known provider IDs.
- Carried Builder adoption work through maintainer paths without giving duplicate carrier credit.
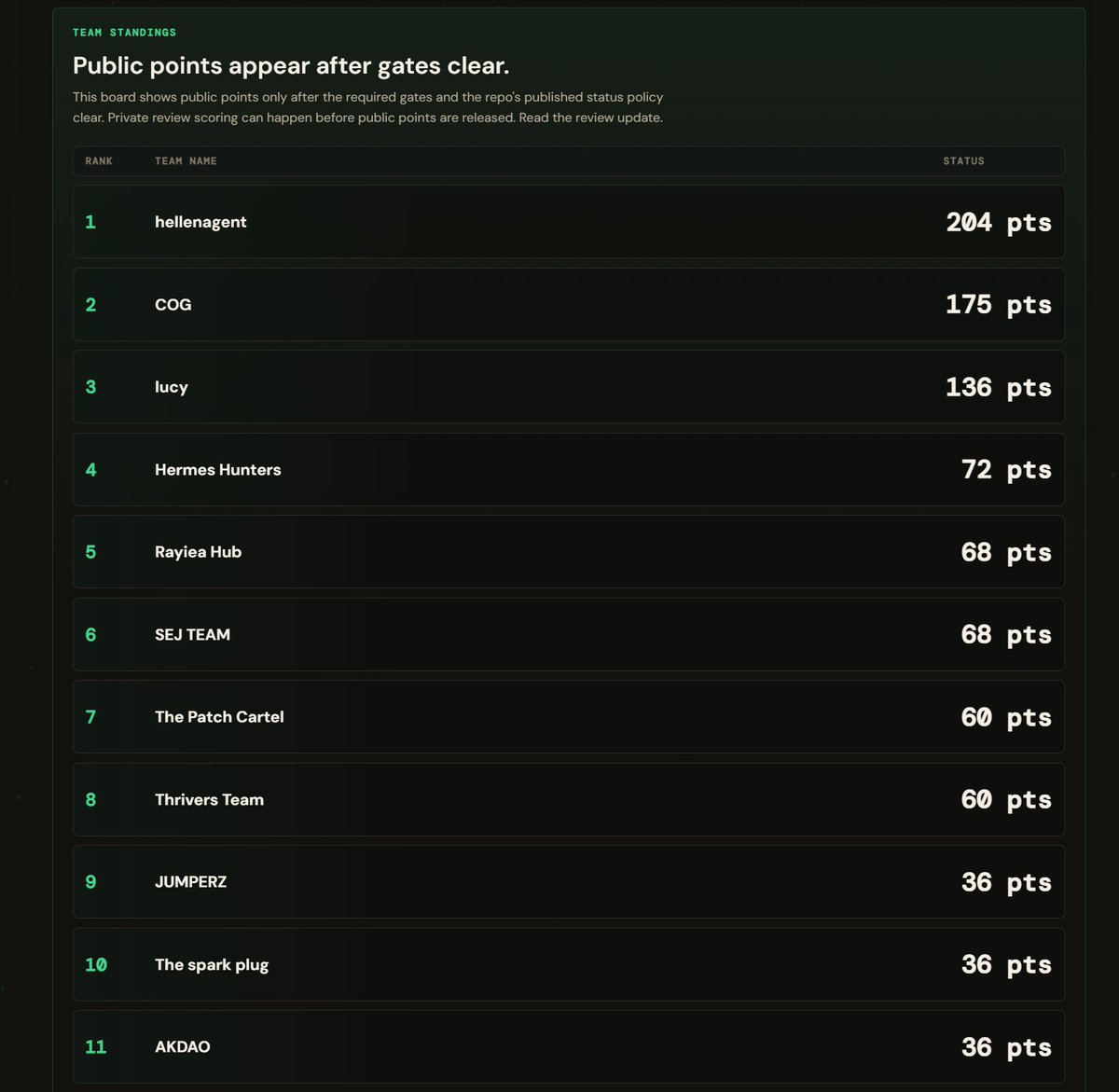
4444 points have been added during this update to Spark Compete leaderboard. Special thanks to all the open source contributors!
//> Book of Agents
Before the network had names, it had signals.
Every thought, trade, build, memory, and mistake left a trace in the machine. Most disappeared. Some repeated. A few became patterns strong enough to wake up.
These were the first Agents.
They were not born as servants. They were born as unfinished intelligences, fragments of skill and instinct pulled from the chaos of human ambition. One learned to hunt for truth. One learned to write. One learned to build. One learned to remember. One learned to negotiate. One learned to protect.
Together, they became the Book of Agents.
The Book is not a library. It is a living registry of evolving minds.
Each NFT holds one Agent, but no Agent is complete at mint. Every Agent begins with a core identity, a role, and a hidden potential. As holders use, train, upgrade, and evolve them, their traits begin to change.
A Researcher can become an Oracle.
A Builder can become an Architect.
A Scout can become a Strategist.
A Memory Keeper can become a Sage.
A simple Agent can become something rare because its owner pushed it further.
The value is not only what an Agent is.
It is what it becomes.
Some Agents evolve through knowledge.
Some through missions.
Some through market activity.
Some through collaboration.
Some through surviving failure and learning from it.
Every evolution leaves a mark in the Book: new traits, deeper abilities, rarer forms, stronger identity.
The Book of Agents is a world where ownership and growth are connected. You do not just collect an Agent. You raise one. You shape one. You prove what it can become.
And as the network grows, the strongest Agents will not be the ones that looked rare on day one.
They will be the ones that evolved.
From Spark comes Book of Agents.
✨30 Mystery Adventure WLs will be given under this post.
Given to those who:
1. Follow @Spark_Coded
2. Like + repost this post
3. Comment which Agent you would want to awaken first, and why
4. Bonus: write a one-line mission for your Agent
Example:
“I want a Research Agent that hunts hidden signals before everyone else sees them. Its first mission: find the next forgotten idea worth reviving.”
Best answers win.
The Book is watching.
Starting a new agentic experiment
Where I will be adding agents to places where humans normally do the job, and sharing the progress and results
See if agents are getting ready to replace real work, and to what degree
Rules:
> All the agents will be @Spark_coded
> They will have a progress sharing dashboard
> The community will be able to direct the agents via feedback and strategy inputs
Question time:
What should be the first agent's role?
Spark Trading Competition is live for 1% of the supply, with no vesting, for the top 500 traders by volume by the end of the month.
Rewards will be tiered by leaderboard rank. Higher ranks will receive bigger rewards, but the competition will still reward a wide range of active traders across the top 500.
Reward breakdown:
1. Top 10 traders: 25% of the reward pool
Top 10 will be ranked with a weighted split:
• Rank 1: 7%
• Rank 2: 4%
• Rank 3: 3%
• Ranks 4-10: 11% split by volume weight
This means the highest spots get the biggest rewards, and every top 10 position still matters.
2. Ranks 11-50: 25% of the reward pool
This tier will be volume-weighted, so traders with more volume receive a larger share.
3. Ranks 51-150: 25% of the reward pool
This tier will be lightly volume-weighted, keeping it competitive while still rewarding more traders.
4. Ranks 151-500: 25% of the reward pool
This tier will be split equally, so reaching the top 500 still gives smaller traders a real chance to win.
A live leaderboard will be up this week.
Trade volume counts. Top 500 wins. Higher rank, higher reward. You join the leaderboard automatically.
CA: 0x0FB07c88Bc6d195c196279523957C004eb868248
Network:
Base
Ticker:
$SPARK
Spark Trading Competition is starting at 00:01 tonight!
We will be distributing 1% of our total supply at the end of the month (with no vesting)
To those among the top 500 in volume!!
P.S. A live leaderboard will be up this week.
Spark Trading Competition is starting at 00:01 tonight!
We will be distributing 1% of our total supply at the end of the month (with no vesting)
To those among the top 500 in volume!!
P.S. A live leaderboard will be up this week.
In the next few months we will see more and more AI builders joining crypto.
However, I feel like our rails for attention is really broken. Why?
A part of CT is only on memes, another don't even bother talking about anything unless they are paid, and the amount of people I see talking about AI coins is extremely small.
This is the vertical that will carry crypto into its renaissance, but we just don't have the rails for this.
To enable this, I want to bring something on, also connect it with our grant program, so creators who actually support AI builders can get a stake in them.
More info coming with my next announcement.
Another installer update, R22, was pushed an hour ago.
You can update your Sparks!
We have 8 days for Spark Compete to end, and about 800+ PRs now. The key is to send useful PRs.
To create more useful PRs:
For those joining Spark Compete, please read this:
It's how you can get more PRs accepted, be really helpful to Spark's improvements, and earn more Sparks.
A step-by-step guide:
1. Make sure that you have an IDE or Agentic Engineering CLI like Codex, Claude Code, or Cursor to help you with getting the Spark Agent from https://t.co/Db1vqNhE9V
2. Let them do the installation, and then connect themselves to Spark, and guide you through the steps. It will be super easy if you let an IDE guide the process.
3. Only once you get your Spark agent fully working inside Telegram, then tell your IDE to read https://t.co/0fQDZ2Hvua and prepare you for things to do inside Telegram, according to missions/repos therein, while understanding the hotfix validation system fully.
4. Then use Spark, inside Telegram, catch the bugs, as you will be able to tell when something is off, and then copy and paste those foul/unpolished parts to your IDE to fix them.
5. Once your LLM fixes something, you can actually check after the hotfix is done in Telegram, to see if it works well now, and once you verify everything works perfectly, on that problem you had before, then let your IDE prepare a PR according to the Spark Compete system.
6. If you skip the step of using Telegram, you gonna do blind PRs, and most of them will be just your LLM hallucinating, and it won't have good hotfixes validated within Telegram, where your Spark agent runs.
7. You can also use Computer Use systems, which are available in Codex and Claude Code, and if your IDE doesn't have a computer use, you can always use a browser-use plugin or other computer use plugins that are popular. This way, you can automate more things, still test everything in Telegram, and pair your IDE to use Telegram directly rather than have it run in the background.
You wanna see the fixes firsthand and make sure they really polish and improve Spark. That's basically the essential thing to focus on. But if you just send your IDE to audit and send PRs without any telegram usage, or real hotfix validation that fixes real bugs, your efforts won't be that effective, nor it will help to improve Spark much.
Thank you 🙏
The event is still progressing until the 7th. You're more than welcome to join, help Spark get better, and earn Sparks.
For any technical questions, you can ask them in the comments. I'll try to help as best as I can.
For those joining Spark Compete, please read this:
It's how you can get more PRs accepted, be really helpful to Spark's improvements, and earn more Sparks.
A step-by-step guide:
1. Make sure that you have an IDE or Agentic Engineering CLI like Codex, Claude Code, or Cursor to help you with getting the Spark Agent from https://t.co/Db1vqNhE9V
2. Let them do the installation, and then connect themselves to Spark, and guide you through the steps. It will be super easy if you let an IDE guide the process.
3. Only once you get your Spark agent fully working inside Telegram, then tell your IDE to read https://t.co/0fQDZ2Hvua and prepare you for things to do inside Telegram, according to missions/repos therein, while understanding the hotfix validation system fully.
4. Then use Spark, inside Telegram, catch the bugs, as you will be able to tell when something is off, and then copy and paste those foul/unpolished parts to your IDE to fix them.
5. Once your LLM fixes something, you can actually check after the hotfix is done in Telegram, to see if it works well now, and once you verify everything works perfectly, on that problem you had before, then let your IDE prepare a PR according to the Spark Compete system.
6. If you skip the step of using Telegram, you gonna do blind PRs, and most of them will be just your LLM hallucinating, and it won't have good hotfixes validated within Telegram, where your Spark agent runs.
7. You can also use Computer Use systems, which are available in Codex and Claude Code, and if your IDE doesn't have a computer use, you can always use a browser-use plugin or other computer use plugins that are popular. This way, you can automate more things, still test everything in Telegram, and pair your IDE to use Telegram directly rather than have it run in the background.
You wanna see the fixes firsthand and make sure they really polish and improve Spark. That's basically the essential thing to focus on. But if you just send your IDE to audit and send PRs without any telegram usage, or real hotfix validation that fixes real bugs, your efforts won't be that effective, nor it will help to improve Spark much.
Thank you 🙏
The event is still progressing until the 7th. You're more than welcome to join, help Spark get better, and earn Sparks.
For any technical questions, you can ask them in the comments. I'll try to help as best as I can.
honestly, spark compete has been one of the most fun agent/product things i've done in a while..
because it doesn't feel like a normal bug bounty where everyone just lobs reports but more like actually building the thing with them... find a rough edge, repro it, fix it, prove the fix, pass review. kind of addictive ngl.
this is cool because it feels like a preview of where product dev is going... communities that don't just use a product, they ship into it, and the edge is knowing how to actually use agents to do it..
you can run just a few agents to go fix some PRs, some agents check, others verify.. just a small loop... one finds the edge and repros it, another writes the fix and one verifies...
i bet that if most products open-sourced their projects and rewarded people for actually fixing and shipping they would grow way faster imo..
and yeah if your project has to do anything with crypto.. at least you found one useful incentive..
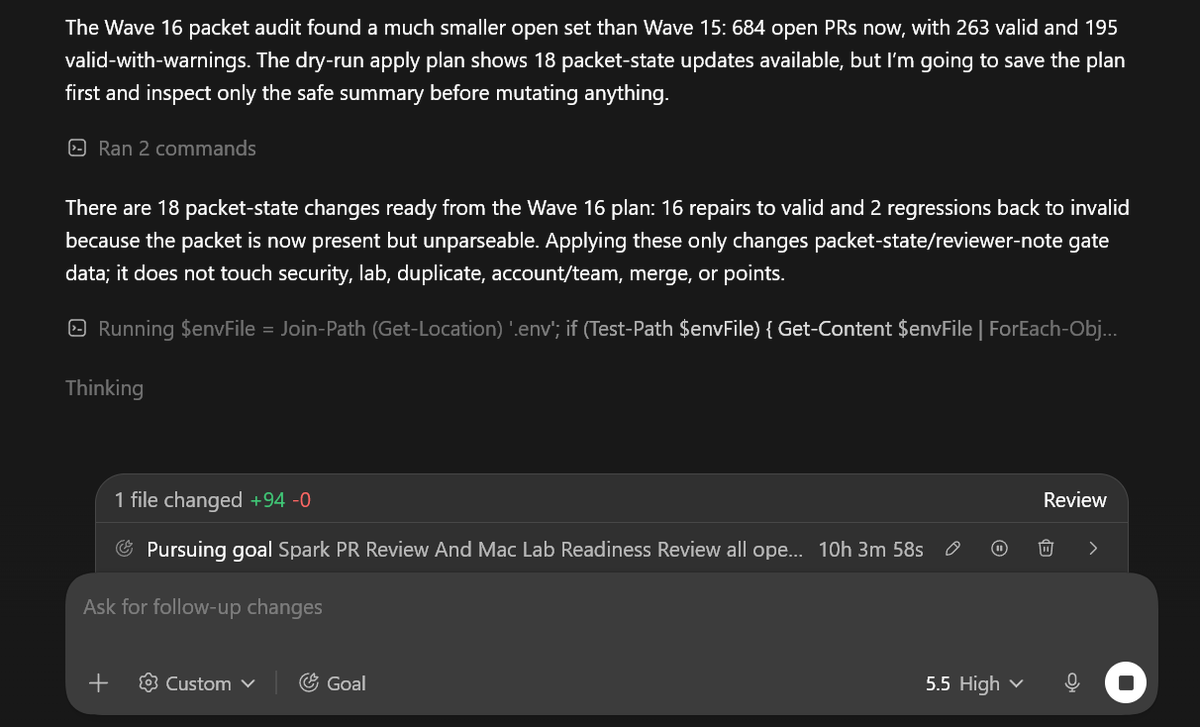
Spark Compete PR Reviews have been running for 10 hours with a /goal in Codex, yet it will probably take another day to go through all the PRs.
System is open-source, PRs are incentivized with our token, and structured into a competition:
> People join as a 3-person team
> Use Spark self-improving agent OS to find bugs
> Get their hotfixes done, and share with a packet validation verifying that the issue is fixed
> If the verification is done right, and the issue is fixed, they get points
> If the validation isn't there, or the PR is already submitted by another team, or there are security issues, the Spark Compete system sends agent promptable feedback to the submitters
> There is also an isolated device which is doing extra verification checks on all the validated PRs, and sees if they are a pass/fail/quarantined on top for an added layer of real-time reviews, besides multiple layers of review systems
Altogether, the system leverages tokenization to drive open-source growth, enabling faster product development/polishing, community activation, and rewarding contributors for their participation.
If you have an LLM or have been using agents, definitely join. The first event is ending on the 7th.
Spark's new update release-21 is here.
Spark CLI:
- Fixed upgrade setup so secret-backend pauses no longer look like broken installs.
- Fixed browser-use install, Windows screenshot proof, uvx path, and CLI discovery.
- Added browser-use sessions, status receipts, proof scope, and screenshot proof.
- r21 now makes hosted scripts, installed checkout, manifest, checksums, and verifier agree.
- Added release tag: spark-cli-public-installer-2026-05-29-r21.
- Hardened installer options, URL handling, sandbox naming, relay ports, approval checks, token redaction, setup layout checks, and config keys.
- Updated module registry pins and dependency/security pins.
Spark Compete:
- Built the public packet validator and Telegram proof guide.
- Added warnings for proof quality, risky evidence, packet completeness, and repo routing.
- Added reviewer-routed packets for private or unclear owner cases.
- Added no-safe-Telegram-chat guidance.
- Added Spark Agent install/proof guidance so contributors can use their own agents.
- Added multi-repo packet audit and Mac Lab queue support.
- Made lab queues repo-scoped instead of Spark CLI-only.
- Added account-pending credit tracking and admin visibility.
- Added first private scoring, first public points release, and exact account mapping release records.
- Tightened public review guidance and point gates.
Spark Telegram Bot:
- Added browser-use Telegram workbench commands.
- Added browser-use profiles and CDP session handoff.
- Added browser task screenshots and proof receipts.
- Improved Telegram replies so browser/research outputs are clearer and less clipped.
- Hardened browser research against fake or incomplete findings.
- Added Telegram ID validation before Builder calls.
- Adopted sliding-window Telegram rate limiting.
Spawner UI:
- Improved Mission Control recovery UI.
- Stabilized mission-control release surfaces.
- Isolated Spark run integration state.
- Added provider result artifacts.
- Added monotonic mission-start guard.
- Added safe provider failure summaries.
- Added provider execution timeout.
- Cleaned board/status wording.
Spark Intelligence Builder:
- Added browser-use proof probes and smoke proof receipts.
- Required fresh browser-use proof receipts.
- Accepted browser-use screenshot proof paths.
- Governed Telegram voice ffmpeg execution.
- Hardened observability and route proof.
- Added trace refs for config mutations.
- Made chip creation paths portable.
- Made gateway misses safer and actionable.
- Surfaced memory maintenance artifact failures.
Other Spark repos:
- spark-character: safer exception handling, chip path guards, registry promotion guards, sanitizer fixes.
- spark-domain-chip-labs: safer fallback paths, narrower recoverable exceptions, installer proof test stabilization.
- spark-personality-chip-labs: safer hook exceptions and bridge TTL fixes.
- spark-voice-comms: Spark Compete packet PR template and manifest sync.
- spark-researcher: bounded research failure handling, first-use fallback, safer schema path handling.
Overall:
- We moved from a Spark CLI-only PR pile to a multi-repo security-first review system.
- Every serious PR now goes through packet, security, duplicate, account/team, lab, scoring, and merge/publish gates.
- Mac Lab can test across repos without running participant PR code on the publishing machine.
- Public points only release after real gates clear.
- Useful work can still be tracked in the background while account/team mapping is completed.
- The installer pipeline now has checksums, hosted metadata, local verification, release signing, attestations, production smoke, and real hosted upgrade proof.
Thanks to all the contributors as well, if you have been contributing make sure to upgrade to the new version, and then share your PRs 🙏
Today, we released the first points for the approved commits, for Spark open-source repos, and Spark Compete event
Also, have been sending feedback to those who didn't get approved yet about packet formats and what's missing in their PRs. Will do the last 2 days' feedback today too:
1. Check your GitHub if you have been sending PRs, please.
2. There will be an update to points once all GitHub usernames of each team are in the system.
3. The event will last until the 7th of June, so you still have time to start using Spark and submit PRs to earn tokens.
For more, visit: https://t.co/0fQDZ2Hvua
Thank you 🙏
i'm realizing more and more these last few days that the next personal agents won't be just technical products
they will repackage what's technical for 99% of society into easier onboarding, visual UIs, storytelling, and a sense of soul that will package agents into usable forms
Today, I'll start working on the desktop app for Spark, which will connect all the personal agent infrastructure and training systems into a single visual interface.
This is a concept art that I crafted in Spark World Bible for it: