Very good advice on self-improving agents.
(bookmark it)
This is something I am seeing in my own experiments with coding agents and harnesses for long-horizon tasks.
What I have found is that stronger models do not always evolve better agents.
The current believe in self-evolving agents is that a bigger model writes better prompt and skill edits, so devs put their best model in the evolver seat.
New research shows that intuition is mostly wrong.
The work separates two abilities that usually get conflated. Producing harness updates stays flat across model capability, so Qwen3.5-9B writes edits roughly as good as Claude Opus 4.6. Benefiting from those updates follows an inverted-U that peaks at mid-tier models, while weak models fail to even activate the edits and strong models have little headroom left.
This is important to understand as it tells you where to spend. Put a cheap model on the evolver and your expensive model on the solver, because the gains land solver-side, not evolver-side.
Paper: https://t.co/8kJwR7NhmV
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
OpenClaw runs natively on Windows leveraging MXC
"The Windows node and gateway run contained, so your system stays secure. You can easily install and use @OpenClaw in @Windows with its own companion app and set up your own claws or connect to existing ones, available in open-source. We are invested in continuing to make #OpenClaw run securely on Windows." #MSBuild
In the next version of Claude Code: run /usage to see a breakdown of which Skills, Agents, MCPs, and Plugins are using your tokens
CLI today, coming to Desktop next
// Agentic Harness Engineering //
Pay attention to this one, AI devs.
(bookmark it)
Most coding-agent harnesses are still tuned by hand or brittle trial-and-error self-evolution.
This new work introduces Agentic Harness Engineering, a framework that makes harness evolution observable. They do this through three layers: components as revertible files, experience as condensed evidence from millions of trajectory tokens, and decisions as falsifiable predictions checked against task outcomes.
Each edit becomes a contract you can verify or revert.
Results: pass@1 on Terminal-Bench 2 climbs from 69.7% to 77.0% in ten iterations, beating human-designed Codex-CLI (71.9%) and self-evolving baselines like ACE and TF-GRPO.
The evolved harness also transfers across model families with +5.1 to +10.1 point gains, while using 12% fewer tokens than the seed on SWE-bench-verified.
Harness work is the biggest hidden cost in most agent systems. This is the first credible recipe for letting the harness improve itself without drifting into noise.
Paper: https://t.co/9fEgqwlTSf
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Microsoft Agent Framework 1.0 is here — stable APIs, multi‑agent orchestration, long‑running workflows, and full C# + Python support. The VS Code Foundry Toolkit adds “Create Agent,” built‑in skills, & Agent Inspector for visual debugging. Catch the demo: https://t.co/OKCvwOiln7
// Tool Attention Is All You Need //
New research proposes a practical fix for the hidden "MCP tax."
The work introduces a dynamic tool gating mechanism built on an Intent Schema Overlap score from sentence embeddings, paired with a state-aware gating function that enforces preconditions and access scopes.
A two-phase lazy schema loader keeps a compact summary pool in context and only promotes full JSON schemas for the top-k gated tools.
On a simulated 120-tool benchmark, tool tokens dropped from 47.3k to 2.4k per turn (95% reduction) while effective context utilization rose from 24% to 91%.
Why does it matter?
As MCP ecosystems grow, naive tool exposure will silently wreck both cost and reasoning quality. Dynamic tool gating and lazy schema might help your setup.
Paper: https://t.co/ak4Koy93Ah
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Karpathy's autoresearch repo started an impressive trend.
Agents can now train AI models to build SoTA agentic systems.
And to think this is just scratching the surface.
Ultimately, it boils down to good research questions or hypotheses. LLMs are not great at this (yet).
NEW paper from Microsoft
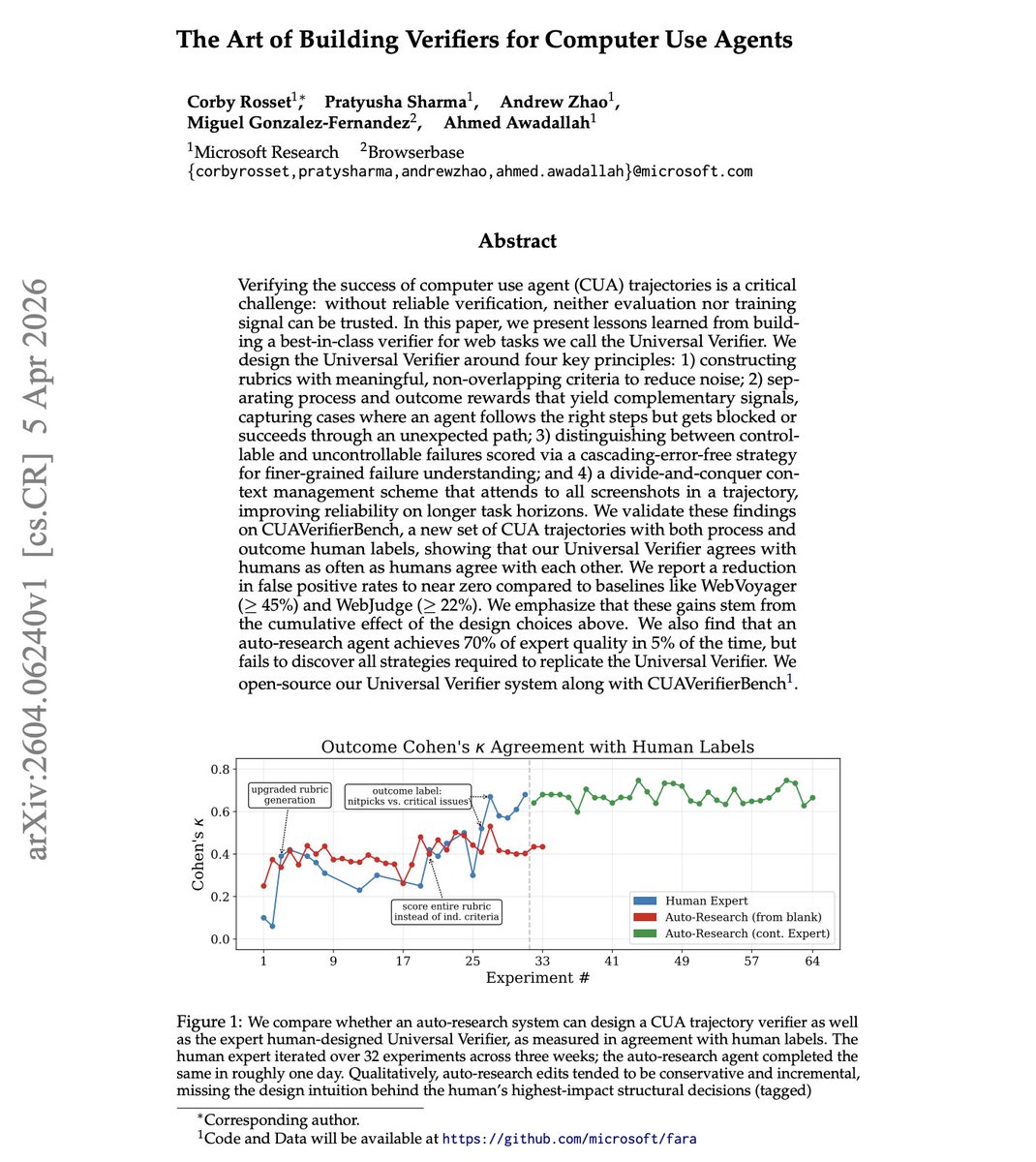
Every agent benchmark has the same hidden problem: how do you know the agent actually succeeded?
Microsoft researchers introduce the Universal Verifier, which discusses lessons learned from building best-in-class verifiers for web tasks.
It's built on four principles: non-overlapping rubrics, separate process vs. outcome rewards, distinguishing controllable from uncontrollable failures, and divide-and-conquer context management across full screenshot trajectories.
It reduces false positive rates to near zero, down from 45%+ (WebVoyager) and 22%+ (WebJudge).
Without reliable verifiers, both benchmarks and training data are corrupted.
One interesting finding is that an auto-research agent reached 70% of expert verifier quality in 5% of the time, but couldn't discover the structural design decisions that drove the biggest gains. Human expertise and automated optimization play complementary roles.
Paper: https://t.co/fWhG9I8vPP
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Visual Studio Code now integrates with Ollama via GitHub Copilot.
If you have Ollama installed, any local or cloud model from Ollama can be selected for use within Visual Studio Code.
New on the Anthropic Engineering Blog:
How we use a multi-agent harness to push Claude further in frontend design and long-running autonomous software engineering.
Read more: https://t.co/HWvmXk1ykn
This is one of the most interesting papers on self-improving agents for this year.
(bookmark this one)
Most self-improving AI systems hit the same wall: the mechanism that generates improvements is fixed and can't improve itself.
This new work from Meta and collaborators breaks through this limitation.
They introduce Hyperagents, self-referential agents where the self-improvement process itself is editable.
The DGM-Hyperagent combines a task agent and a meta agent into a single modifiable program, enabling metacognitive self-modification.
It autonomously discovers innovations like persistent memory and performance tracking, and these meta-improvements transfer across domains and compound across runs.
Why does it matter?
- On paper review, DGM-H improved from 0.0 to 0.710 test accuracy.
- On robotics reward design, it went from 0.060 to 0.372.
- Transfer hyperagents achieved 0.630 on Olympiad-level math grading in a domain they were never trained on.
This is a step toward AI systems that don't just find better solutions but continuously improve how they search for improvements.
Paper: https://t.co/Q0f7zWhNMD
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Pay attention to this one if you are building terminal-based coding agents.
OpenDev is an 81-page paper covering scaffolding, harness design, context engineering, and hard-won lessons from building CLI coding agents.
It introduces a compound AI system architecture with workload-specialized model routing, a dual-agent architecture separating planning from execution, lazy tool discovery, and adaptive context compaction.
The industry is shifting from IDE plugins to terminal-native agents.
Claude Code, Codex CLI, and others have proven the model works.
This paper formalizes the design patterns that make these systems reliable, covering topics like event-driven system reminders to counteract instruction fade-out, automated memory across sessions, and strict safety controls for autonomous operation.
Paper: https://t.co/tpAZFaSnog
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
In the next version of Claude Code..
We're introducing two new Skills: /simplify and /batch. I have been using both daily, and am excited to share them with everyone.
Combined, these kills automate much of the work it used to take to (1) shepherd a pull request to production and (2) perform straightforward, parallelizable code migrations.