⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
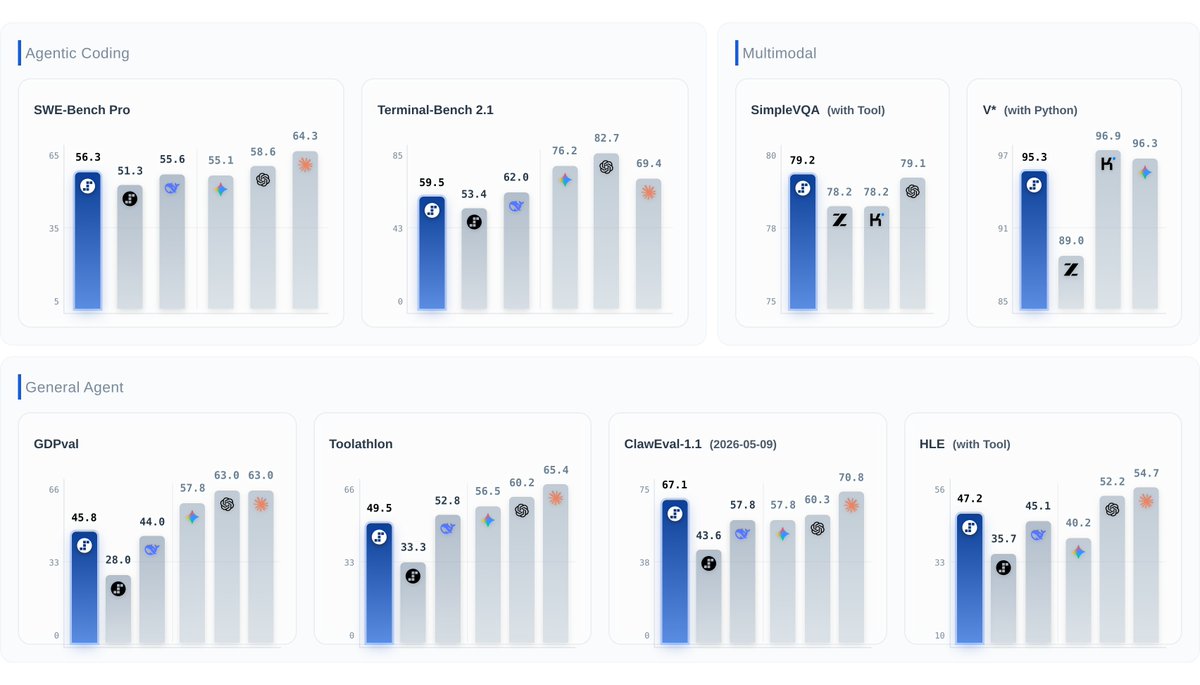
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
Great to see Step 3.7 Flash live on @FireworksAI_HQ.
Designed for inference from day one, Step 3.7 Flash combines a hardware-friendly architecture with MTP-assisted decoding to reach up to 400 tokens/s.
Fast, multimodal, and ready to power capable agents in real-world workflows.
Many research labs only consider inference efficiency after the fact. Step 3.7 Flash is a 198B sparse MoE VLM designed by @StepFun_ai for inference from the start. 196B language backbone with a 1.8B vision encoder.
Built for real-world agent workloads, running at up to 400 tok/sec. Native multimodal understanding and action, reliable tool use, and enhanced web and visual search.
Apache 2.0. Try it now → https://t.co/OYqzBUBxqL
Thanks @ArtificialAnlys for the detailed independent evaluation.
Step 3.7 Flash is built with a clear focus on the intelligence-speed frontier: MTP-assisted decoding, 400+ output tokens/s, stronger agentic performance, native multimodal capabilities, and Apache 2.0 open weights.
This is the direction we believe matters for production agent workloads: capable, efficient, and deployable at scale.
StepFun's Step 3.7 Flash sits on the Intelligence vs Output Speed Pareto frontier, scoring 43 on the Artificial Analysis Intelligence Index and is served at over 400 output tokens/s
Step 3.7 Flash (open weights, Apache 2.0) is a significant upgrade on Step 3.5 Flash and stands out for its speed and gains in agentic performance (particularly GDPval-AA). 400 output tokens/s is more than double other models of a similar size class. Contributing to this speed is that the model has only 11B active parameters and the model ships with trained Multi-Token Prediction heads (3) that predict several tokens in a single forward pass, letting it decode multiple tokens at once using speculative decoding.
Key results for Step 3.7 Flash with the high reasoning level:
➤ 4 point Intelligence Index improvement: Step 3.7 Flash scores 42.6 on the Artificial Analysis Intelligence Index, up 4 points from Step 3.5 Flash 2603 (38.5). It is equivalent to Qwen3.5 122B A10B (41.6) and trails MiniMax-M2.7 (49.6) and DeepSeek V4 Flash (Max Effort, 46.5)
➤ Speed-intelligence frontier: Step 3.7 Flash achieves ~400 output tokens/s on StepFun's first-party API, placing the model on the Intelligence vs Output Speed Pareto frontier. StepFun has released the weights for this model and we expect several third-party providers to serve this model
➤ Agentic capability improvements: Step 3.7 Flash improves over Step 3.5 Flash 2603 across our agentic evaluations, in both GDPval-AA (real-world agentic tasks) and TerminalBench Hard (agentic coding and terminal use). It achieves a GDPval-AA Elo of 1298, up from 1070 for Step 3.5 Flash 2603, and it's TerminalBench Hard score increases to 35.6% from 32.6%. AA-LCR (Long Context Reasoning) improves to 63.7% from 54.3%. Scores for other evals remain relatively flat
➤ Weaker on knowledge and hallucination than peers: While Step 3.7 Flash trails competitors overall on AA-Omniscience (-38), it improves from Step 3.5 Flash 2603 (-44). It has an AA-Omniscience accuracy of 25.4% and a hallucination rate of 84.4%
➤ Native multimodal support, new in this generation: Step 3.7 Flash introduces a 1.8B-parameter vision encoder for native image understanding, where Step 3.5 Flash was text-only. On MMMU-Pro (multimodal reasoning) it scores 75.3%, roughly matching Qwen3.5 122B A10B (75.0%). Among its same-size open weights peers, MiniMax-M2.7, DeepSeek V4 Flash, and gpt-oss-120b are text-only
Key model details:
➤ Context window: 256K tokens ➤ Parameters: 198B total, 11B active (MoE). At BF16 native precision, Step 3.7 Flash requires ~400GB to store the weights. StepFun has also released FP8 (~200GB) and NVFP4 (~100GB) versions for lower-memory deployment
➤ License: Apache 2.0 ➤ Availability: Currently Step 3.7 Flash is available on @StepFun_ai 's first-party API
Deploy Step 3.7 Flash on @modal with SGLang 🚀
Modal is a serverless AI platform for deploying and scaling compute-intensive workloads without managing infrastructure.
Their new guide shows how to serve our open-weight Step 3.7 Flash with SGLang on Modal, using 8×H100 GPUs, Modal Volumes, and an OpenAI-compatible chat completions endpoint.
Excited to collaborate with Modal to make StepFun models more accessible to builders.
https://t.co/E7gaNPq02H
Great demo by @atomic_chat_hq.
Step 3.7 Flash was designed for real-world agentic coding tasks — not just generating code fast, but keeping logic, visuals, and execution coherent across complex outputs.
Love seeing builders test it in creative ways!
StepFun Step 3.7 Flash smashed DeepSeek V4-Flash in a physics contest
We gave two open-weight models the same task: write a self-contained HTML5 canvas animation with real physics in one file without libraries. Three scenes - a Galton board, balls bouncing in a spinning hexagon and five metronomes that sync up
Outputs:
Step 3.7 Flash: 59.6k tokens, 9m 57s
DeepSeek V4-Flash: 52.5k tokens, 6m 21s
DeepSeek was faster, but that's all it had. StepFun's model won on every front: physics simulation, visuals, and logical rendering of each scene
Open weights are moving from model cards into real coding workflows.
Step 3.7 Flash is designed for fast agentic coding, reliable tool calling, and multimodal understanding.
Big thanks for the blog from the @kilocode team:
https://t.co/twCxrlgXpp
The open-weight labs did not come to play this week.
StepFun dropped Step 3.7 Flash.
MiniMax dropped M3.
Both with open weights, both already live in Kilo.
The "model wars" just got a lot more interesting.
A Lab note for Step 3.7 Flash launch.
--
When Flash models bring speed, cost, and intelligence into the “usable” range all at once, the way intelligence is supplied changes structurally.
--
https://t.co/WI9k8GwYiR
Step 3.7 Flash is now FREE in @kilocode 🎉
It was built for how coding agents actually work. That means multi-step orchestration and reliable tool use across a real codebase, not just fast replies.
Try it on a real task in your editor, like a multi-file change or an actual bug!
Intelligence got us here. Efficiency is what gets real work done.
At ClawCon Macao, our GM of Developer Business @EileenTal laid out the next frontier for agents — and the thinking behind Step 3.7 Flash. 👏
Today at BEYOND ClawCon Macao, I shared our view on the next phase of model competition:The new frontier is agent efficiency.
Not just intelligence.But the ability to get real-world agentic work done — reliably, efficiently, and at scale.
That’s the thinking behind Step 3.7 Flash