Day 16/100
Today’s learning:
• Started a new web scraping project
• Set up the development environment
• Configured API keys and project dependencies
• Planned the project architecture and workflow
#BuildInPublic#WebScraping#Python#GenAI#AIEngineering
Today’s takeaway:
The quality of an LLM’s output often depends more on the prompt than the model itself.
A well-structured prompt can improve accuracy, consistency, and reasoning without changing the underlying model.
Still exploring AI Engineering deeply
@vadym_petryshyn Good catch!
I’m using RunnableWithMessageHistory mainly for learning the fundamentals of chat memory. I’ll definitely explore the newer LangChain-recommended alternatives as I go.
Thanks for the heads-up!
Day 14/100
Today I learned:
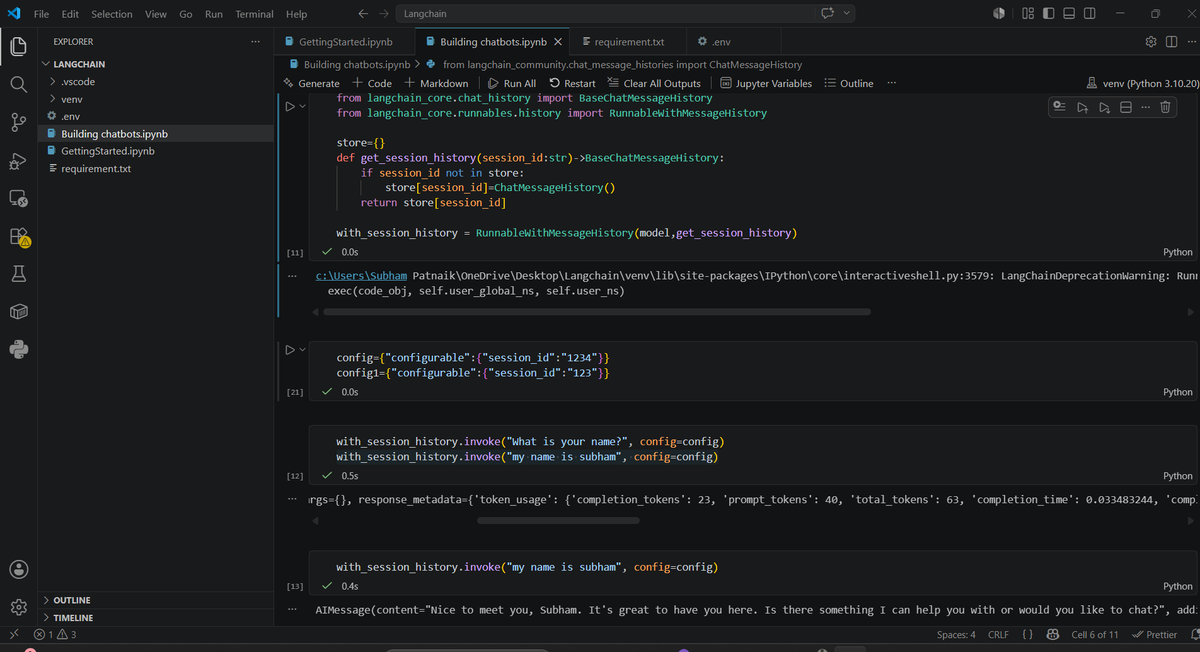
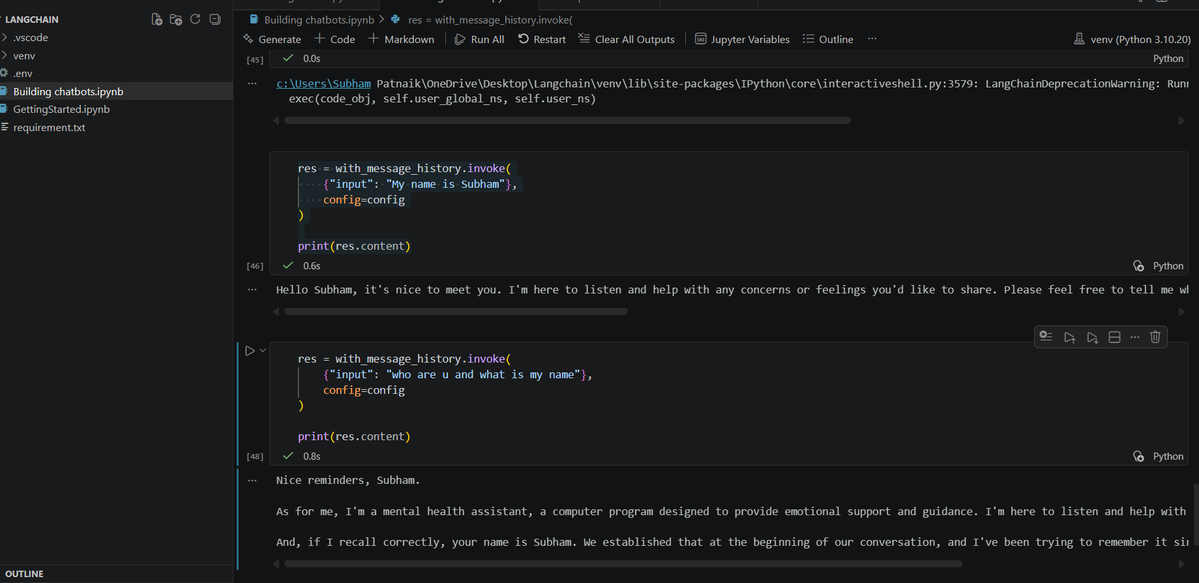
• How chatbots can remember previous conversations using chat history
• Session-based memory management with RunnableWithMessageHistory
• How prompt templates help guide LLM behavior with predefined instructions
#BuildInPublic#LangChain#LLM
Today's takeaway:
An LLM doesn't remember anything by default.
Memory is created by storing conversation history and associating it with a session ID.
Combined with prompt templates, this allows us to build chatbots that can maintain context and respond more consistently.
Today’s takeaway:
LLMs are only as good as the context they receive.
A good retriever can often improve answers more than a larger model because it delivers the right information at the right time.
Open to suggestions and resources on RAG and LLM Engineering
Day 9/100
Today I learned:
• Data Collection for LLMs
• Data Accumulation Techniques
• The importance of high-quality datasets in AI systems
Also:
• Cleared 3 interview rounds
• Solved 2 LeetCode problems
#BuildInPublic#LLM#GenAI#AIEngineering#LeetCode
Today’s takeaway:
LLMs don’t memorize your documents.
They convert text into embeddings and store them in vector databases like FAISS. When a query arrives, similarity search retrieves the most relevant chunks, which are then sent to the LLM as context.
Day 12/100 🚀
Today I learned:
• Vector Stores
• FAISS (Facebook AI Similarity Search)
• Similarity Search
• Embedding Storage & Retrieval
• How vector databases help in RAG applications
Lc:509 and 209 solved today
#BuildInPublic#RAG#FAISS#LLM#LangChain#GenAI
Day 11/100
Today i have learned about:
•Converting the chunks into embeddings
• different llm like Ollama and open api
• went through the langchain documentation
#BuildInPublic#LLM#LangChain#GenAI#AIEngineering
Today’s takeaway:
Chunking affects how well an LLM retrieves and understands context.
Learning different chunking strategies helped me understand RAG systems better.
Open to tips and resources on RAG and LLM Engineering
Day 10/100
Today I learned:
• Document chunking for LLMs
• Fixed-size, Recursive, and Token-based chunking
• How recursive splitting helps preserve context
Also:
• Prepared for a Cyber Security interview
#BuildInPublic#LLM#RAG#GenAI#CyberSecurity