There is something seriously wrong if a body charged with regulating food goes to the police to file FIRs against those who question its performance.
What is the FSSAI really regulating? Food? Or people who question it?
Deeply disturbing
https://t.co/9wIvvXQ9qG via @theprintindia
"Youth angry over poor civic sense." 😡
He was peacefully walking on the footpath, but a large number of bikers kept honking at him to move aside for an easy pass.
When will people in India understand that the footpath is for pedestrians, not bikes?
Delhi Police has busted a fake "Sensodyne" toothpaste factory. 1,800 filled tubes, 10,000 empty tubes, 1,200 packed tubes, and 130 kg of paste have been seized. The factory owner, Hariom Mishra, has been arrested.
Congrats to the @cursor_ai team on the launch of Composer 2!
We are proud to see Kimi-k2.5 provide the foundation. Seeing our model integrated effectively through Cursor's continued pretraining & high-compute RL training is the open model ecosystem we love to support.
Note: Cursor accesses Kimi-k2.5 via @FireworksAI_HQ ' hosted RL and inference platform as part of an authorized commercial partnership.
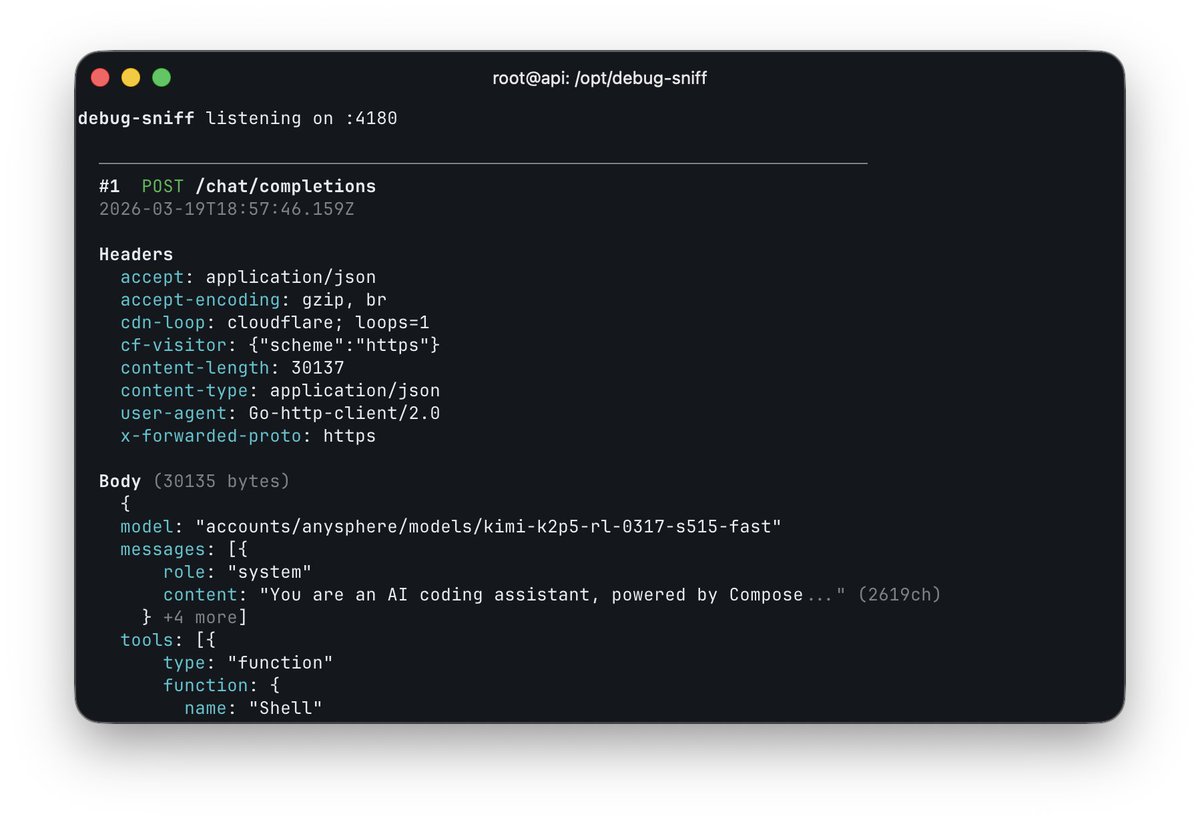
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID
I was wrong.
I tweeted that we are not investing enough in R&D and education.
Here's the world's first "Tuning Fork Flyover" in Maharashtra.
This one slows you down mentally before it slows you down physically.
Honestly, it feels like the Maharashtra government tried to solve traffic but accidentally created a confidence exam for drivers.
This paper from Stanford and Harvard explains why most “agentic AI” systems feel impressive in demos and then completely fall apart in real use.
The core argument is simple and uncomfortable: agents don’t fail because they lack intelligence. They fail because they don’t adapt.
The research shows that most agents are built to execute plans, not revise them. They assume the world stays stable. Tools work as expected. Goals remain valid. Once any of that changes, the agent keeps going anyway, confidently making the wrong move over and over.
The authors draw a clear line between execution and adaptation.
Execution is following a plan.
Adaptation is noticing the plan is wrong and changing behavior mid-flight.
Most agents today only do the first.
A few key insights stood out.
Adaptation is not fine-tuning. These agents are not retrained. They adapt by monitoring outcomes, recognizing failure patterns, and updating strategies while the task is still running.
Rigid tool use is a hidden failure mode. Agents that treat tools as fixed options get stuck. Agents that can re-rank, abandon, or switch tools based on feedback perform far better.
Memory beats raw reasoning. Agents that store short, structured lessons from past successes and failures outperform agents that rely on longer chains of reasoning. Remembering what worked matters more than thinking harder.
The takeaway is blunt.
Scaling agentic AI is not about larger models or more complex prompts. It’s about systems that can detect when reality diverges from their assumptions and respond intelligently instead of pushing forward blindly.
Most “autonomous agents” today don’t adapt.
They execute.
And execution without adaptation is just automation with better marketing.
Not frequent to get this error message on half the webpages I try to visit
The internet's key dependencies include not just AWS, but also Cloudflare, clearly (we knew this, but nothing brings it home like an outage!)
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
This is insane.
New AI model from Samsung, 10,000x smaller than DeepSeek and Gemini 2.5 Pro just beat them on ARC-AGI 1 and 2
Samsung’s Tiny Recursive Model (TRM) is about 10,000x smaller than typical LLMs yet smarter because it thinks recursively instead of just predicting text. It first drafts an answer, then builds a hidden "scratchpad" for reasoning, repeatedly critiques and refines its logic (up to 16 times), and produces improved answers each cycle.
This approach shows that architecture and reasoning loops (not just size), can drive intelligence. It enables powerful, efficient models that run cheaply, validate neuro symbolic ideas, and open highest quality reasoning to far more applications.
Acceleration is everywhere
The TRM paper feels like a significant AI breakthrough.
It destroys the pareto frontier on the ARC AGI 1 and 2 benchmarks (and Sudoku and Maze solving) with an estd < $0.01 cost per task and cost < $500 to train the 7M model on 2 H100s for 2 days.
[Training and test specifics]
For ARC, it trained on 160 examples from ConceptARC. At test-time, it uses the most common answer of 1000 augmentations at test-time and embeds a fixed shape of the task in the input.
[Industry implications]
Most AI companies today use general purpose LLMs with prompting for tasks. For specific tasks, smaller models may not just be cheaper, but far higher quality! Startups could (and should) train models for < $1000 for specific "fixed length" subtasks (specific PDF extraction, time series forecasting, etc) and use it as a tool to the general model to not only push performance, but build some meaningful IP at the task they're trying to automate.
To all those hounding for a quote -
“The mainstream media at this point is nothing but a miscommunication arm of the ruling party. They are vultures who report on issues that dont matter to the people of this country. If they all shut shop from tomorrow till eternity they will be doing favour to the country, its people & their own children”
Chinese AI startups: 1/6th of US funding, bad press, sanctions, brain drain, communism, little English proficiency, and no talent influx..
But after using Manus AI, Deepseek, Trae, Kling, Vidu, & Ying, I think the US is in trouble.
At this pace, China will dominate AI.
Demos:
































![deedydas's tweet photo. The TRM paper feels like a significant AI breakthrough.
It destroys the pareto frontier on the ARC AGI 1 and 2 benchmarks (and Sudoku and Maze solving) with an estd < $0.01 cost per task and cost < $500 to train the 7M model on 2 H100s for 2 days.
[Training and test specifics]
For ARC, it trained on 160 examples from ConceptARC. At test-time, it uses the most common answer of 1000 augmentations at test-time and embeds a fixed shape of the task in the input.
[Industry implications]
Most AI companies today use general purpose LLMs with prompting for tasks. For specific tasks, smaller models may not just be cheaper, but far higher quality! Startups could (and should) train models for < $1000 for specific "fixed length" subtasks (specific PDF extraction, time series forecasting, etc) and use it as a tool to the general model to not only push performance, but build some meaningful IP at the task they're trying to automate.](https://pbs.twimg.com/media/G2yJWyPacAAuX-a.jpg)





























