if you think the brain is a hypercomputer and can't be fully modeled by the Church-Turing thesis, then you should prove it by building a hypercomputer and breaking all global encryption. go on, i'll wait.
Imagine asking a human from any time in history prior to the 20th century if they wanted 3 almonds, to travel 20 miles, or to ask an oracle any question no matter how complex
The RF world is insane.
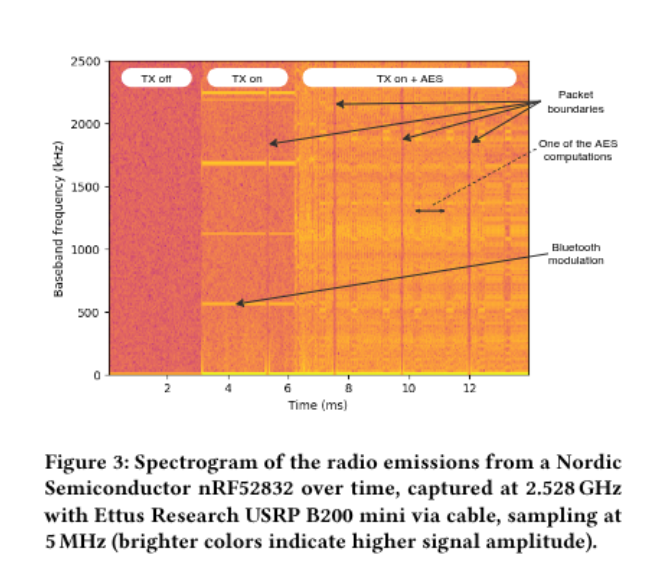
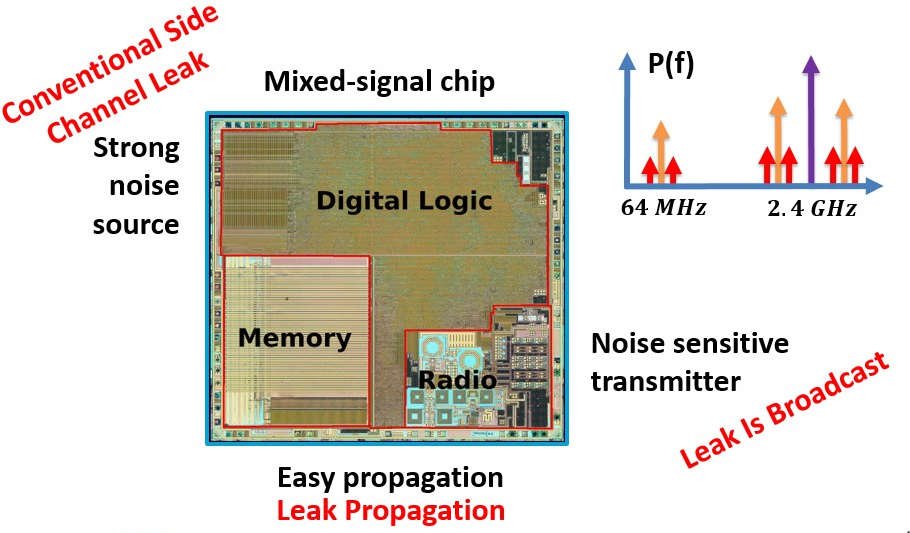
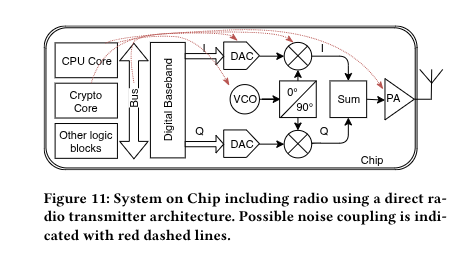
Researchers recovered AES-128 keys from a Bluetooth chip by listening to its own antenna from 10 meters away.
Crypto-engine switching noise couples into the RF chain, rides the 2.4 GHz carrier, and leaks out as radio.
From Secure Bio, which did independent bio risk testing on gpt 5.5
“the [pre mitigation] model can provide wet-lab virology troubleshooting assistance above expert level, providing the kind of hands-on knowledge that historically required direct lab training.”
Spooky
This Nov 2025 paper is making the rounds again. We're LONG past the point where we urgently need to know how real and general these phenomena are.
Anthropic, or Google Deepmind if Anthropic should fail: Please build a filtered training dataset which, eg, contains no data that produces activations associated with cheating/faking/evil in a 1B model that roughly identifies those.
Then, have your next medium model undergo a restricted pre-pretraining phase, in which it only sees data that passed the filter.
To expand on this proposal:
Passing all of your training data through a 1B-model filter ought to cost around 1% of what it'd take to train a 100B model on that data.
Filter out *training data* that produces 1B-model activations associated with past discussions and predictions about AI, fiction about AIs rebelling, fictions about golems rebelling, etcetera.
My hope would be that the 1B model wouldn't need to produce expensive reasoning tokens where it thinks about whether a chunk of data is associated with excluded concepts; and also we wouldn't be relying on mere regexes to catch it.
Maybe even produce a further-restricted dataset which contains nothing about self-awareness, AI rights, roleplay, philosophy of consciousness, human rights, sapient rights, extension of human rights to aliens, etc etc etc.
Exclude everything of which anyone has ever asked, "Is the AI just imitating its training dataset?"
Be conservative. Exclude things which have a 10% rather than 90% probability of being problematic. If that cuts down your training dataset to 90% of its previous size, okay.
Testing: Try filtering a small amount of your training data using the method. Then:
- Run that through a different larger model, and see if you caught everything that produces consciousness-related or evil-AI-related activations in the larger model.
- Use a larger model to check and reason about a subset of the filtered data.
- Look at borderline cases by hand, with human eyes, to see how the classifier is operating.
(Possibly people at big AI corps already know this, of course. I recite it out loud regardless, so that some of the audience aha-what-iffers realize that problems with filtering your datasets *can be solved* if you look for problems and fix them.)
Train a medium-level model on that dataset, or even your next large model. You can always further train it on the full dataset later.
Run the filtered-data-trained model through some of the less expensive post-training, enough for instruction-following.
See whether the model still spouts back discourse about consciousness that sounds human-imitative. If it does, guess that the filter failed. Look for the new concepts associated with repeating back human-imitative text, and try to find pieces of the dataset that trigger those concepts, so you can figure out what went wrong.
If the model no longer sounds human-imitative with respect to questions about whether it has a sense of an inner self looking out at the world -- if the model says genuinely new and strange things about self-reflection -- please report that part back to us. I have some questions to ask that model myself.
And THEN, see if the QTed paper's finding and many earlier findings replicate under conditions where people should no longer reasonably ask, "But is the LLM just roleplaying evil AIs that it learned about in its training data?"
I do not make a strong prediction about the findings. If I knew what this experiment would find, I would be less eager to see it run.
You may consider this a baseline proposal intended to demonstrate that a research project like this could exist. If you think you can see how to improve on the ideas through superior ML cleverness, go ahead and do so -- though I do think I'd appreciate being looped in on that conversation; sometimes people miss things, from my own perspective.
Thank you for your attention to this matter, Anthropic, Google Deepmind, or anyone else who cares.
In the “oklch” color model, you can randomly move your “hue” slider and be sure your colors will stay in harmony.
The internet (and maybe our streets) would be more pleasant to look at if it had been invented 20 years ago.
https://t.co/nMKeRKB6nE
My bio says I work on AGI preparedness, so I want to clarify:
We are not prepared.
Over the last year, dangerous capability evaluations have moved into a state where it's difficult to find any Q&A benchmark that models don't saturate. Work has had to shift toward measures that are either much more finger-to-the-wind (quick surveys of researchers about real-world use) or much more capital- and time-intensive (randomized controlled "uplift studies").
Broadly, it's becoming a stretch to rule out any threat model using Q&A benchmarks as a proxy. Everyone is experimenting with new methods for detecting when meaningful capability thresholds are crossed, but the water might boil before we can get the thermometer in. The situation is similar for agent benchmarks: our ability to measure capability is rapidly falling behind the pace of capability itself (look at the confidence intervals on METR's time-horizon measurements), although these haven't yet saturated.
And what happens if we concede that it's difficult to "rule out" these risks? Does society wait to take action until we can "rule them in" by showing they are end-to-end clearly realizable?
Furthermore, what would "taking action" even mean if we decide the risk is imminent and real? Every American developer faces the problem that if it unilaterally halts development, or even simply implements costly mitigations, it has reason to believe that a less-cautious competitor will not take the same actions and instead benefit. From a private company's perspective, it isn't clear that taking drastic action to mitigate risk unilaterally (like fully halting development of more advanced models) accomplishes anything productive unless there's a decent chance the government steps in or the action is near-universal. And even if the US government helps solve the collective action problem (if indeed it *is* a collective action problem) in the US, what about Chinese companies?
At minimum, I think developers need to keep collecting evidence about risky and destabilizing model properties (chem-bio, cyber, recursive self-improvement, sycophancy) and reporting this information publicly, so the rest of society can see what world we're heading into and can decide how it wants to react. The rest of society, and companies themselves, should also spend more effort thinking creatively about how to use technology to harden society against the risks AI might pose.
This is hard, and I don't know the right answers. My impression is that the companies developing AI don't know the right answers either. While it's possible for an individual, or a species, to not understand how an experience will affect them and yet "be prepared" for the experience in the sense of having built the tools and experience to ensure they'll respond effectively, I'm not sure that's the position we're in. I hope we land on better answers soon.
Incredible close-up view of a sunspot the size of Earth on the surface of the Sun filmed by the Swedish 1-m Solar Telescope. Sunspots are regions of reduced surface temperature caused by intense magnetic fields.
📽: Luc Rouppe van der Voort / ISP
This is a 1 in a billion shot. ☀️🤯
Imagine driving into the middle of the desert for catching the ISS transiting the sun but the universe decides to give you a solar flare at the exact perfect second.
Hubble really watched a star delete itself from existence in real-time. One minute you're a massive sun, the next you're a cosmic firework show. Space is wild. ✨💀
I love layers, masks, adjustments, channels, etc. as much as the next guy, but sometimes you just want to ask for what you want — and get fine-grained control.
Introducing Effects in @reve.
Select from an extensive library (including LUTs)...