We partnered with @mercor_ai to test a simple idea:
What if knowledge-work agents were just… coding agents?
Result: +25% performance, 2x faster, cheaper, and new SOTA on APEX-Agents. @josancamon19
+48% from a single RL step, and 100k rollouts from a single policy.
@LoganGrasby wrote up his findings that off policy training with OAPL is more robust than we thought!
can we train a model in single RL step?
During recent experiments, @Logangrasby found that a single step of OAPL increased model performance from ~0 to 48% on a clinical reasoning and prediction task.
Turns out, data staleness might matter less than we think. with @pathos :
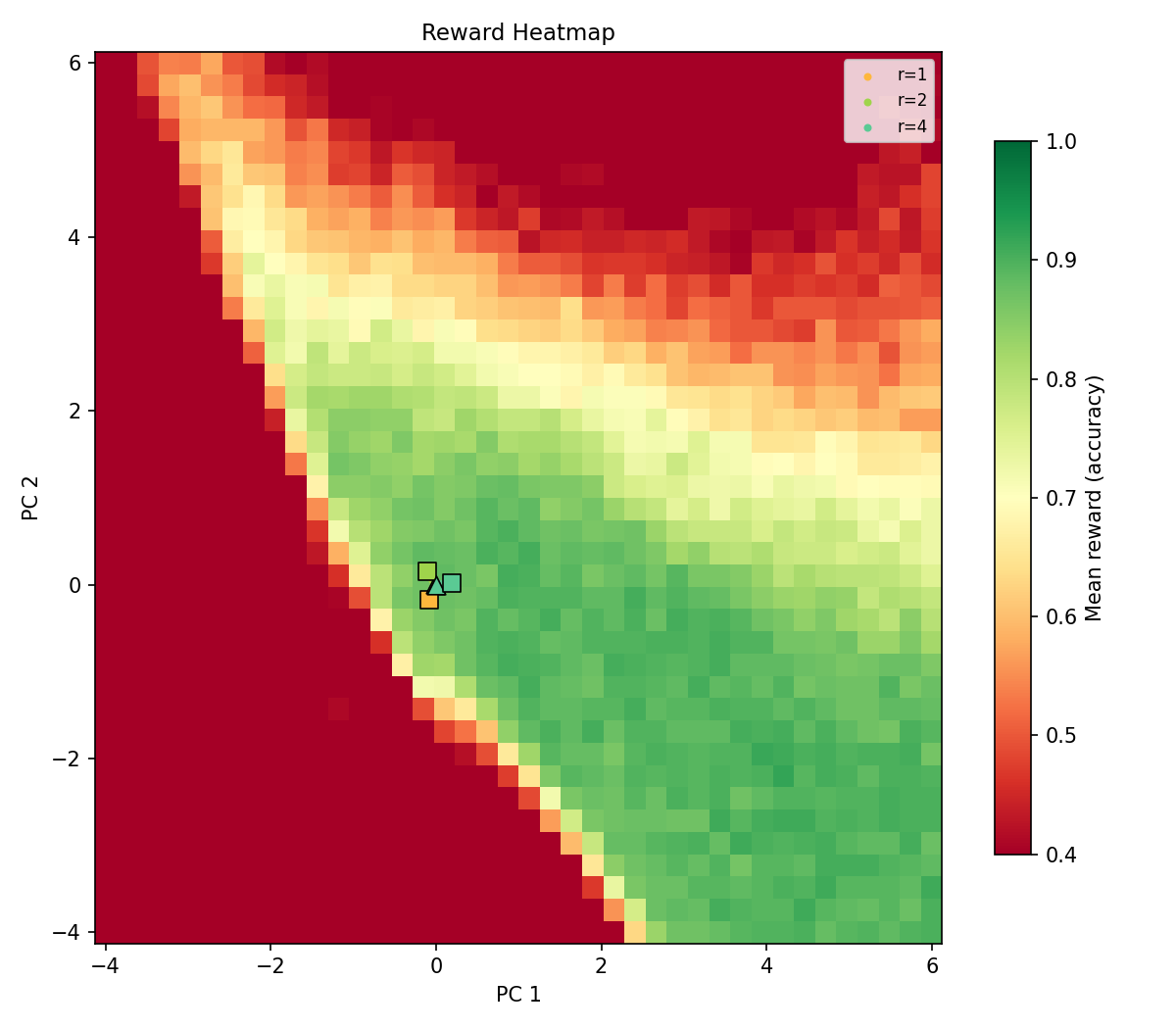
Task-specific training can be far more efficient than we realize. This work by @hasith_v explores the LoRA-trained solution space for GSM8k, finding a massive "plane" of solutions, representable in a single rank.
We trained LoRA adapters of different ranks to understand training dynamics, finding that adapters for GSM8k live in a surprisingly vast, low-rank solution space.
This hints that some model skills are easy to learn, and training is more forgiving than we think. @hasith_v 1/6 🧵
We post-trained MedGemma to be SoTA in visual medicine ddx, outperforming Opus 4.6, Gemini 3.1 and GPT-5.4 while running at ~1/30th the cost. @getnolla Part 1 - improving visual reasoning 🧵1/6
🧵 Labs and VC's are throwing cash at RL environments, especially for computer and browser use. Yet, with just 4 customers and over 30+ vendors, is cloning every website in the world really the path to scale? of course not.
Introducing TRACE: Trajectory Recording and Capture of Environments.