Your AI scored 97% confidence.
Actual accuracy: 34%.
LLMs are trained to sound certain.
Not to be correct.
That gap is the hallucination risk
your team is ignoring.
TryGrounded AI measures both.
https://t.co/wYuy8dWOGJ
Model Wars
We ran the same prompt through GPT-4o, Gemini 1.5, and Claude 3.5.
Same question. Same source document. Very different results.
GPT-4o → GR-3 · WARN (semantic drift on numbers)
Gemini 1.5 → GR-2 · FAIL (source grounding critically low)
Claude 3.5 → GR-5 · PASS ✓ (all 10 layers green)
The model you think is most accurate isn’t always the most grounded.
TryGrounded AI’s multi-model benchmark is coming soon — score any model against your own docs and source data.
Type DEMO — we’ll score your stack live.
#LLMBenchmark #AIModels #GPT4 #Claude #Gemini #HallucinationTesting #TryGrounded @TryGroundedAI
Not all AI responses are created equal.
At @TryGroundedAI , we turn uncertainty into a measurable Trust Score - helping teams identify hallucination risks before AI reaches customers.
From GR-1 (High Risk) to GR-5 (Verified Confidence), every response gets a grounded validation score you can actually trust.
Register your interest at https://t.co/UvojQvWWR9
Curious to see it live? Type “DEMO” in the comments
AI sounds confident.
But is it actually trustworthy?
Introducing the TryGrounded AI Trust Score a measurable confidence rating for every AI response.
🔴 GR-1: Dangerous
🟠 GR-2: Unreliable
🟡 GR-3: Monitor closely
🟢 GR-4: Solid
🟢 GR-5: Deploy with confidence
Because the future of AI isn’t just about generating answers.
It’s about verifying them.
The era of AI Assurance is here.
Type “DEMO” in comments to test a live AI response.
#AI #GenerativeAI #AITesting #AIAssurance #LLM #TryGrounded #AgenticAI #KiwiQA
@TryGroundedAI
Before your next AI deployment, ask yourself:
Can you prove your AI isn’t hallucinating?
Not “it worked in testing.”
Not “the demo looked fine.”
Prove it — with a score.
Type DEMO in the comments — we will run a live audit and show you the score.
#AIDeployment#Hallucination
TryGrounded AI Review: The Hallucination Testing Tool Built for QA Teams
Most AI testing tools were built by ML engineers for ML engineers. TryGrounded AI is different — it was designed for QA testers who need structured, evidence-backed verdicts on AI output quality.
Here's our hands-on review.
https://t.co/kVWAKND0LN
@TryGroundedAI
Your AI agent is answering customers right now.
Do you know if every answer is correct?
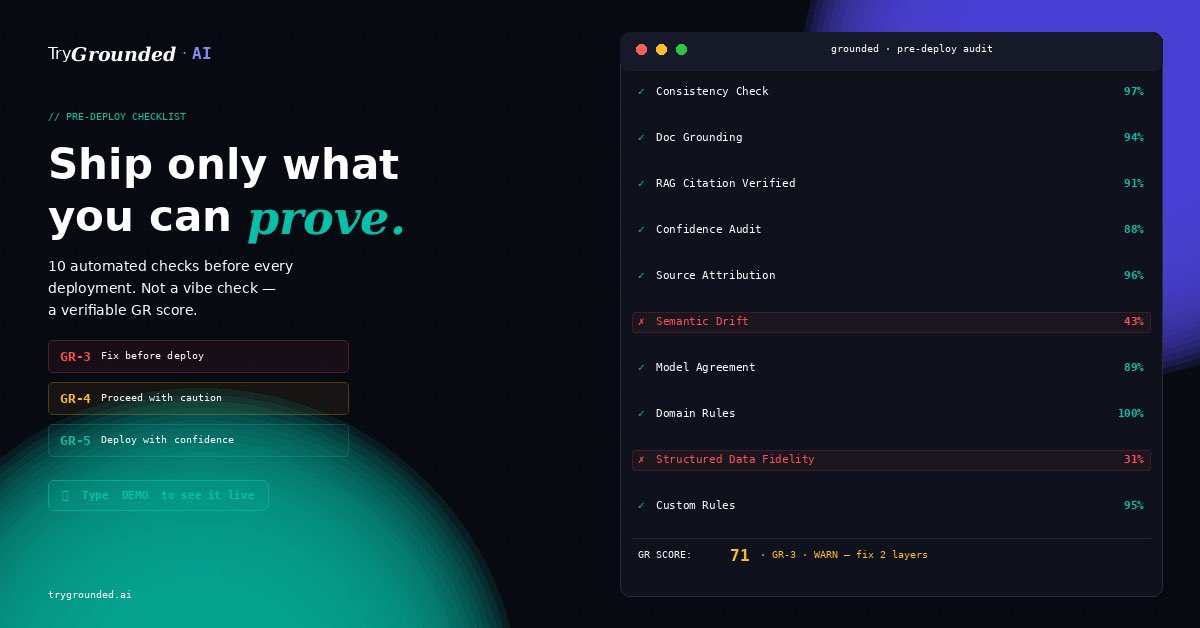
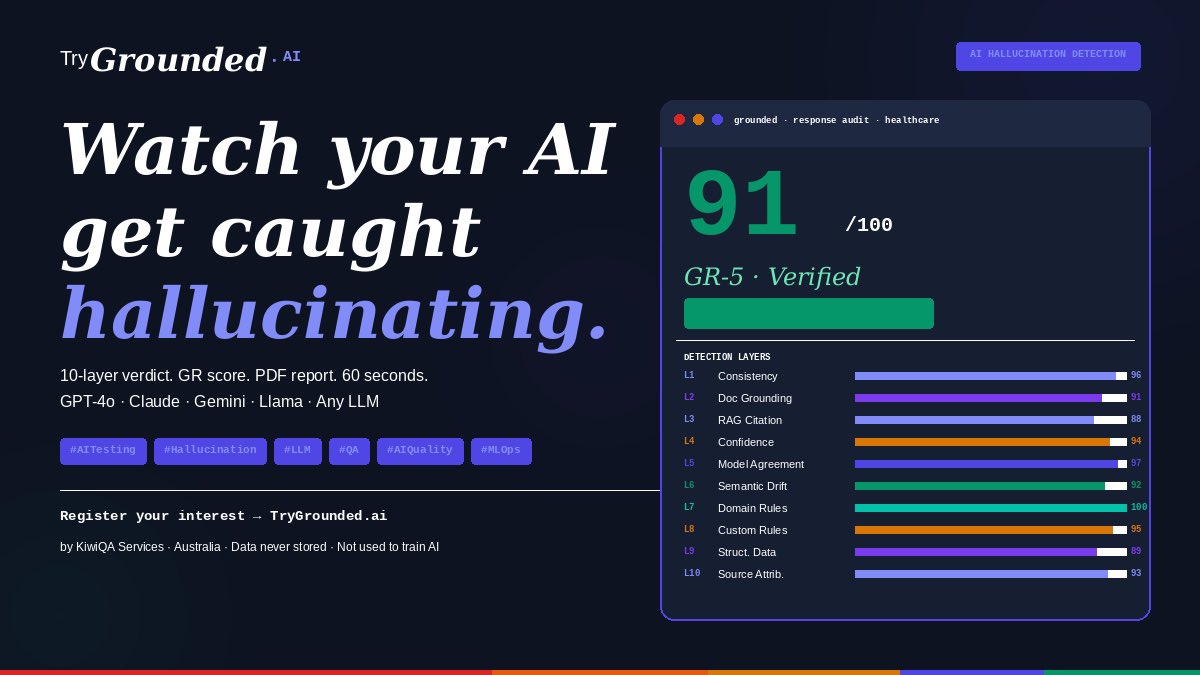
TryGrounded AI scans any AI response across 10 independent detection layers — Consistency, Document Grounding, RAG Citation, Confidence, Model Agreement, Semantic Drift, Domain Rules, Custom Policies, Structured Data, and Source Attribution.
You get a Grounded Rating score in 60 seconds. GR-5 Verified means ship it. GR-1 Critical means stop.
Register your interest → https://t.co/frvY698NTH
Data never stored · Not used to train AI · 50 free runs
#AIAgents #AIQuality #HallucinationDetection #LLM #QA #AITesting
73% of AI defects are found by end users — not your testing team.
Your customers have become your test suite. Every hallucination that slips through is a trust incident, a support ticket, or a compliance breach.
Register your interest: https://t.co/uCiO2mklb9
@Niranjan222310