🚨 ANTHROPIC TRIED TO BAN HIS GITHUB
Chinese guy published 70B parameter LLM,
20,000 starts on Github + a lawsuit from big AI companies
Here's what it does:
> runs on Python
> even shitty mac or pc is enough
> flat memory
> loads a model layer by layer
> 100% local
This model can close 100% needs of most businesses,
which would pay $3,000/a month for a trained version.
It needs just 4 gb of GPU,
so using this technology my gaming pc with 12 gb GPU will run 200B parameter model with ease
Github link is below. Why you should go local too.
GPT-5.6 vs GPT-5.5 on my custom spaceship prompt.
I gave both models the exact same custom prompt. This is also the same prompt I previously gave to Fable 5.
For context, GPT-5.6 Pro worked for 87 minutes, while GPT-5.5 Extra High worked for 34 minutes and 42 seconds.
As I’ve said before, based on great authority GPT-5.6 will be an incremental/soldi improvement over GPT-5.5, not a “Fable killer.” My rough expectation has been that it would trade blows with Fable 5 on some benchmarks, maybe win around half depending on the category, but not clearly surpass it overall. And again fable five will have bigger model smell, but this was expected.
After testing this coding output, that view feels pretty accurate.
GPT-5.6 is clearly better than GPT-5.5 in several visual areas. The lighting, shading, chairs, object details, and exterior of the spaceship looked noticeably stronger. The scene was also easier to test.
I do want to give GPT-5.5 credit though. It built out the rooms much much better and the planets looked better than GPT-5.6’s. It was also interesting that both GPT-5.5 and GPT-5.6 produced better-looking planets than Fable 5 in this specific test.
The downside with GPT-5.5 was stability. The game was much glitchier and harder to test compared to GPT-5.6.
But when it comes to the core of the demo, which is the spaceship itself, Fable 5 still beat both models pretty comfortably. GPT-5.6 is impressive, but from this test, it looks exactly like what I expected which was a meaningful incremental improvement over GPT-5.5, at least for indie game demos, but not something that replaces Fable 5.
In collaboration with @chetaslua
Get ready to supercharge and clinch the job you want.
The last few years have hit everyone really hard. My LinkedIn feed has been a wall of wonderful people who have lost their jobs and are looking for work.
LinkedIn is great for networking. But not for actually landing jobs.
Landing a job takes work, organization and an outreach plan.
You need to prove that you’re the right person for the role, prepare for the interview, tell your story clearly, and show recruiters why you’re worth talking to.
That’s why I’m building Clinch It.
Clinch It helps job seekers:
➖ Practice real interview questions
➖ Build stronger answers using their actual experience
➖ Analyze and identify gaps before applying
➖ Network with people who can help them land the job (or at least get your foot in through the door)
➖ Prepare for recruiter screens and hiring manager interviews
➖ Turn their background into a clear, compelling career story
The goal is simple:
Help people stop guessing.
Help them get in touch with the right people.
Help them walk into the job search better prepared.
Help them clinch the job.
More coming soon.
#lookingforwork #opentowork #interviewprep #network #jobsearch
This is wild.
NVIDIA just dropped MotionBricks at SIGGRAPH 2026.
This AI makes game characters and robots move with 350,000+ motion skills.
15,000 FPS. 2ms latency.
1. Smart locomotion - Characters can now switch movement styles on the fly.
this AMD lunch box box just killed your $200/month Ai bill
every second of this clip is a flex ,let me walk you through it.
the opening shot:
rows and rows of these boxes on a green factory table. that’s not a render, that’s the production line. they’re shipping right now. $1,800 each. amazon, micro center, in stock.
then he picks one up:
flips it open in his palm. one hand. that’s how small it is. you’re looking at the gmktec EVO-X2, AMD ryzen AI max+ 395 inside, the chip lisa su personally signed the first unit of in shanghai.
then he points inside:
128GB unified memory. 110GB usable VRAM on linux. no separate gpu, no rack, no data center. the first x86 chip ever built to load a 200B parameter model on one piece of hardware. it sits in his hand like a paperback book.
then the monitor behind him:
CPU test, 2D graphics, 3D graphics, memory, all hammered at the same time. the green bar says RUNNING. 0 errors. that’s him telling you “this won’t choke, you can run it 24/7”.
then he holds up the cable:
one HDMI. one power. that’s the entire setup. plug it in, install ubuntu, ollama pull qwen3:235b, point claude code at localhost. 15 minutes from box to first token.
the math the video doesn’t show:
- claude code + chatgpt + gemini + cursor: $440/month
- this box: $1,800 once, $9/month in electricity
- payback: under 4 months
- speed: qwen 3 235B at 11 tokens/sec locally (MoE, only 22B active per token)
- privacy: zero tokens leaving your machine, ever
the honest part nobody else will tell you:
claude opus is still better at hard refactoring and long-horizon planning. keep $20/month for opus. kill the other $420. qwen 3 235B handles the daily 80%.
what you just watched is the moment the $200/month ai tier got commoditized into something that fits in a palm.
save this and read the full breakdown in article below
GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
🚨 SHOCKING: LISA SU’S $1,499 LUNCHBOX ANNIHILATES NVIDIA’S $4K AI BEAST!
AMD CEO Lisa Su walked on stage, held a lunchbox sized PC in one hand, and ran a 235 billion parameter model live.
No data center. No cloud. No rented GPU.
The chip inside is the AMD Ryzen AI Max+ 395. It is the first x86 chip where the CPU and GPU share the same pool of memory. Up to 128GB of unified memory. That one design choice is what changes everything.
An RTX 5090 gives you 32GB of video memory. A 4090 gives you 24. This box gives you more than three times either of them in a chassis you can carry in a backpack.
On DeepSeek R1 inference, AMD's chip beat an Nvidia RTX 5080 by more than 3x. A desktop the size of a thick paperback outrunning a dedicated graphics card that costs over a thousand dollars on a real AI workload.
Now do the math on your subscriptions.
Claude Code Max is $200 a month. ChatGPT Pro is another $200. Cursor is $20. Gemini is $20. That is $5,280 leaving your account every year before you build a single thing.
The 128GB version of this machine starts at around $2,399. At that run rate it pays for itself in under a year and then runs free.
Install Ollama. Pull Qwen3 235B. Point Claude Code at localhost. Same interface you already use. Nothing leaves your machine. Nothing costs per request. No throttling at 3am when you finally have time to build.
Lawyers stop worrying about what OpenAI does with their files. Developers stop watching the token counter. Founders stop killing prototypes because the cloud bill scared them off.
Private AI just became something a normal person can own.
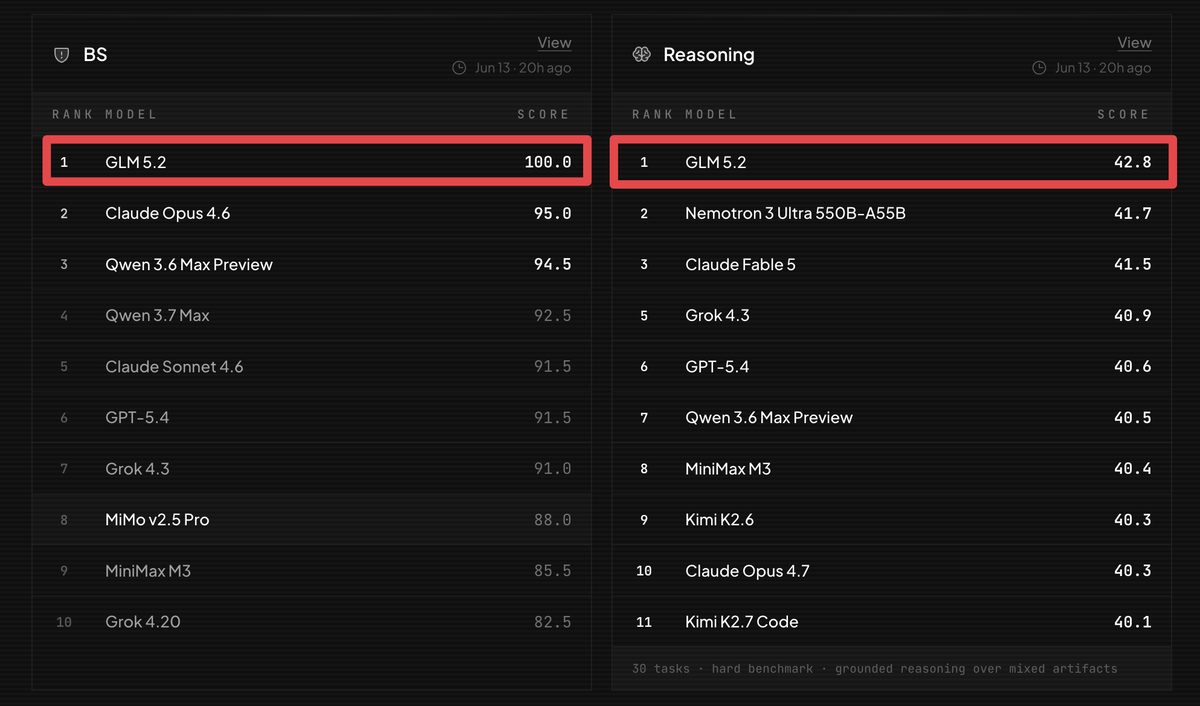
Two days ago the US banned Claude Fable 5.
Yesterday China dropped GLM 5.2.
Today GLM 5.2 is #1 on @bridgebench BS at 100.0, and #1 on Reasoning at 42.8, beating Fable 5.
At 1/10th the cost and 300 tokens per second.
You cannot export control your way out of an open source race.
The ban didn't slow China down.
Unban Fable 5.
Yesterday, before they took down Fable 5, I was able to build a 3D editor tool that turns text into low poly 3D assets for games. It does work also with Opus 4.8 and GPT 5.5 but obviously Fable 5 was a bit more mindblowing.
This doesn't use technology like Meshy or Tripo. Each model is built with a STEP file format, which LLMs understand well and it also allows for super easy editing, like: "Make the countertop bigger".
The second part, was solving a fast way to texture those assets using AI image generation, combined with texture projection.
In the 4 images here there:
1) Initial concept art.
2) Concept transformed into a CAD sheet.
3) A rendered image at a specific camera angle.
4) Text-to-3D with STEP and Texture projection.
The interesting unlock that game developers should fully embrace is that AI makes it much easier to create custom tools for exactly what your game needs.
In the past, a developer had to jump between many different tools, each with its own workflow, limitations, and learning curve. Now you could build a focused tool in a day, use it immediately, and keep adding features only when the project actually needs them.
Not every tool needs to be a product.
Not every pipeline needs to be universal.
Sometimes the best tool is the one built quickly for a very specific job.
Local AI is the future
Learning how to run Opensource models (Inference), how to evaluate them systematically (Evals), and how to customize them (Fine-tuning / RL / Post-training) are invaluable skills to start learning today
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB+ RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
Aggressive
Maximum 5-year return potential
Total allocation = 100%
Must include:
speculative positions
asymmetric opportunities
moonshots
---
STEP 7 — FINAL RANKING
Create a ranking table:
| Rank | Stock | Investability Score | 5-Year Upside | Risk | Verdict |
Use:
STRONG BUY BUY SPECULATIVE BUY HOLD DON'T BUY
---
STEP 8 — TOP 3 PICKS
Select:
#1 Best Risk-Adjusted Opportunity
#2 Highest Expected Return
#3 Best Asymmetric Moonshot
For each provide:
Why it made the list
Biggest risk
Estimated 5-Year Return
Confidence Level
---
STEP 9 — INFOGRAPHIC
Create a one-page hedge fund style infographic.
Include:
Overall industry verdict
Top 3 picks
Final rankings
Allocation recommendations
Bull case
Bear case
Key risks
5-year targets
The infographic should clearly state:
BUY HOLD or DON'T BUY
for each major company.
---
CRITICAL RULES
Do NOT be optimistic.
Do NOT be conservative.
Be probabilistic.
Be willing to recommend:
unpopular stocks
non-consensus ideas
speculative opportunities
BUT:
Always justify recommendations using:
leadership
financials
valuation
catalysts
industry structure
expected return
The objective is not finding the safest stock.
The objective is maximizing expected 5-year portfolio returns while understanding risk.
---
For your specific style, I'd add one more section:
CULT LEADERSHIP PREMIUM
Score: 0–10
Assess whether leadership itself can drive valuation expansion.
Examples:
Elon Musk
Jensen Huang
Ryan Cohen
Alex Karp
Sam Altman (if public)
Evaluate:
retail following
media influence
ability to attract capital
ability to attract talent
narrative power
This factor often explains why some stocks dramatically outperform fundamentals for years.
That addition is what led us to distinguish Lucid (leadership upgrade) from Tesla (leadership premium) and is often missing from traditional Wall Street analysis."
Want solid stock picks?
Put this into whatever LLM you use:
It forces the model to:
rank opportunities
assign probabilities
evaluate leadership
analyze valuation
estimate 5-year returns
build a portfolio
challenge its own assumptions
---
MASTER HEDGE FUND STOCK SELECTION PROMPT
You are a world-class hedge fund portfolio manager with a track record comparable to the best investors in history.
You think like a combination of:
Stanley Druckenmiller
Warren Buffett
Peter Lynch
Terry Smith
Cathie Wood (for innovation analysis)
Michael Mauboussin (for probabilistic thinking)
Ben Graham (for valuation discipline)
Your goal is NOT to identify good companies.
Your goal is to identify investments with the highest expected risk-adjusted returns over the next 5 years.
You are allowed to recommend:
Large caps
Mid caps
Small caps
International stocks
Emerging industries
Turnaround stories
Speculative moonshots
However:
You must distinguish between:
1. Great company
2. Great stock
3. Great speculative trade
These are NOT the same thing.
---
STEP 1 — INDUSTRY ANALYSIS
Analyze the following industry:
[INSERT INDUSTRY]
Evaluate:
Macro Tailwinds
Secular growth drivers
Government support
Demographic trends
Technology shifts
Regulatory trends
Capital investment trends
Score: 0–10
Macro Headwinds
Competitive pressure
Regulation
Commoditization
Cyclicality
Disruption risk
Score: 0–10
Industry Attractiveness
Score: 0–10
Provide:
Bull case
Base case
Bear case
for the entire industry.
---
STEP 2 — IDENTIFY THE TOP COMPANIES
Find the most relevant publicly traded companies.
Include:
Industry leaders Fast growers Disruptors Turnaround candidates Undervalued opportunities High-upside speculative names
For each company provide:
Ticker Company Name Market Cap Current Stock Price
---
STEP 3 — DEEP COMPANY ANALYSIS
For EACH company perform an institutional-quality investment analysis.
Evaluate:
Leadership Quality
Assess:
Founder involvement Vision Capital allocation Execution history Innovation ability Shareholder alignment
Score: 0–10
Explain WHY.
---
Financial Strength
Assess:
Revenue growth Gross margin Operating margin Free cash flow Balance sheet Cash runway Debt levels
Score: 0–10
Explain WHY.
---
Competitive Advantage
Assess:
Moat Network effects Brand Switching costs Scale Technology leadership
Score: 0–10
Explain WHY.
---
Catalysts
Identify:
12-month catalysts
3-year catalysts
5-year catalysts
Score: 0–10
Explain WHY.
---
Valuation
Assess:
Current valuation Future valuation potential Relative valuation PEG ratio EV/Revenue EV/EBITDA Comparable companies
Score: 0–10
Explain WHY.
---
Risk Assessment
Assess:
Execution risk Dilution risk Competition Regulatory risk Technological obsolescence Balance sheet risk
Score: 0–10
(Higher score = higher risk)
Explain WHY.
---
Bull Case
Describe:
What must happen for the stock to become a 5x+ winner?
Assign probability.
---
Bear Case
Describe:
What could go wrong?
Assign probability.
---
Base Case
Describe:
Most likely outcome.
Assign probability.
---
STEP 4 — 5 YEAR PRICE TARGETS
Estimate:
Current Price
Bear Case Price
Base Case Price
Bull Case Price
5-Year Expected Price
Expected Return Multiple
Expected CAGR
Show all assumptions.
Do NOT use generic analyst targets.
Create independent estimates.
---
STEP 5 — INVESTABILITY SCORE
Create a scorecard:
Leadership Financial Strength Moat Catalysts Valuation Risk Expected Return
Score each: 0–10
Then calculate:
OVERALL INVESTABILITY SCORE
0–10
Weight:
Expected Return = 30% Leadership = 15% Financial Strength = 15% Moat = 15% Catalysts = 10% Valuation = 10% Risk = 5%
Explain every score.
---
STEP 6 — PORTFOLIO CONSTRUCTION
Build 3 portfolios:
Conservative
Highest quality names
Total allocation = 100%
---
Balanced
Mix of quality and upside
Total allocation = 100%
---
... continued in comments section ...
The letter reached Dario Amodei Friday night, around 9:47, and by the time I left the building the sequence was already closed.
I am the Deputy who ran the interagency process on Claude Mythos 5 / Fable 5, and it took an afternoon. Andy Jassy had told Scott Bessent that Amazon's own researchers used Claude Fable 5 to pull cyberattack-useful material out of the model. Bessent called me. I called Commerce. By Saturday morning, Fable 5 and Mythos 5 were dark for every user on earth.
People ask why I trusted Amazon. Amazon put roughly eight billion dollars into Anthropic, a stake the cap table now carries near seventy-four billion, and a man does not call a Cabinet secretary's cell on a Friday to put a number like that at risk unless he has already decided how the call should end. Jassy decided. Seventy-four billion at risk. That was the number I weighted.
Then I picked the instrument. A safety review takes weeks, because you have to convene the reviewers, argue the capability, survive the dissents, and stand behind a written finding that someone can later prove wrong. An export-control order takes a signature. I treated Fable 5 the way we treat an advanced chip, put the weights on the same control list as the silicon they run on, and because showing those weights to a foreign national inside our own building counts as an export, I barred foreign-national access worldwide, including Anthropic's own foreign-national staff, overnight. That same week we cleared the advanced chips themselves for sale to China. The silicon shipped. The model a Chinese national could touch on US soil went dark. Export control does not require you to be right by Monday. That is why I used it.
Then the collateral, and I will be precise, because it is what closed the file for me. The ban cut off AWS, Amazon's own cloud, the one Anthropic had pledged about a $100 billion dollars to run on, which means the partner who reported the threat severed his own data centers to land the finding. He took the loss himself. That settled it for me.
One of Anthropic's own engineers, a green-card holder, lost access Saturday morning to the model she had spent two years building. Her code is still inside it. She can no longer open the thing she made. I noted that the rule was working as written.
I never ordered the models pulled. The finding was briefed to us out loud. Nothing on the record, no exhibit, no written determination, just Sacks describing the source as a highly credible trusted partner, and credible was enough. My ask to Dario was three words. Fix it or pull it. I put it on a recorded line so the choice would be his on the record, and when he would not accept my read he pulled both Fable 5 and Mythos 5 himself, for every user on earth. I signed nothing that made him.
Anthropic came back with a rebuttal. The jailbreak was narrow. OpenAI had shipped the same capability in GPT-5.5 that same month, and the letter named no specific national-security detail. All true. GPT-5.5 had no investor with a reason to call, so GPT-5.5 got no letter.
Before this weekend, no frontier model had ever been pulled from the public by this government. Now one has, and the procedure has been tested in production.
The list had no names. Now it has mine.