Proud to be part of the amazing int'l team that worked on this
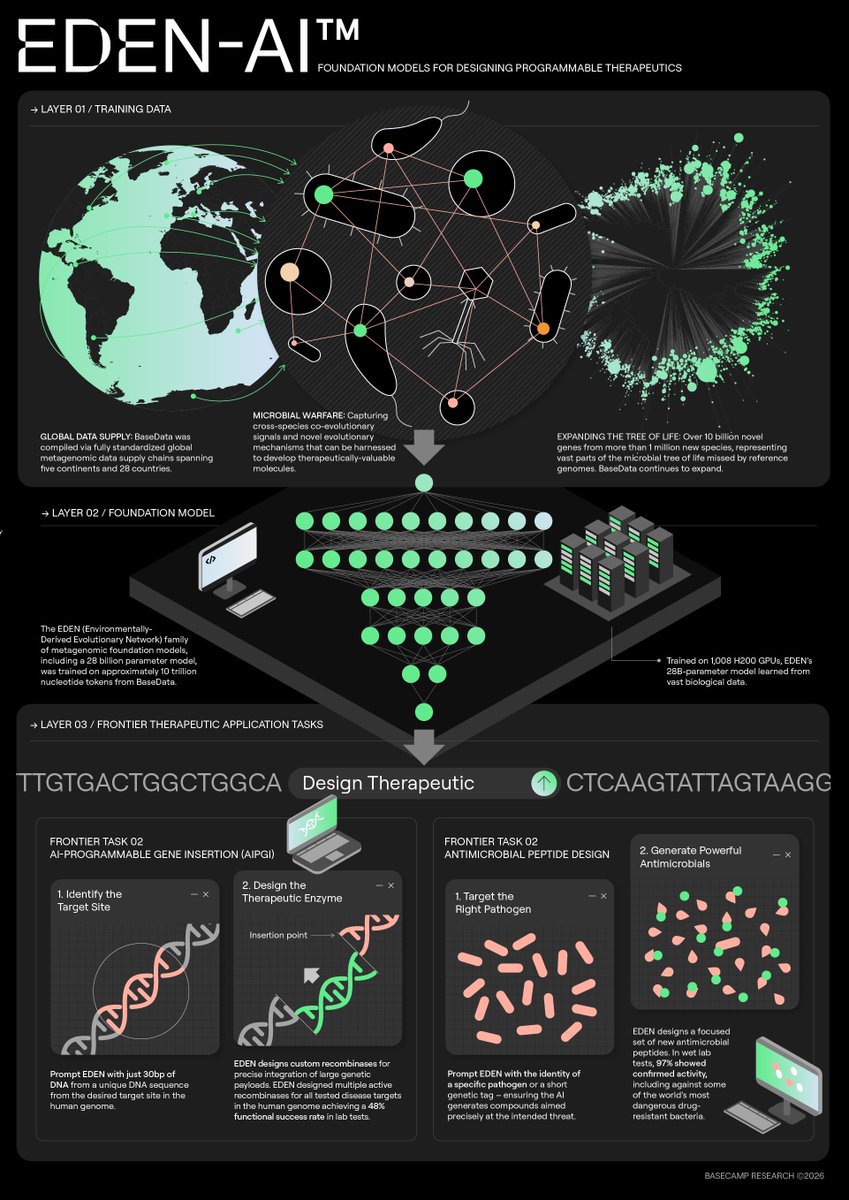
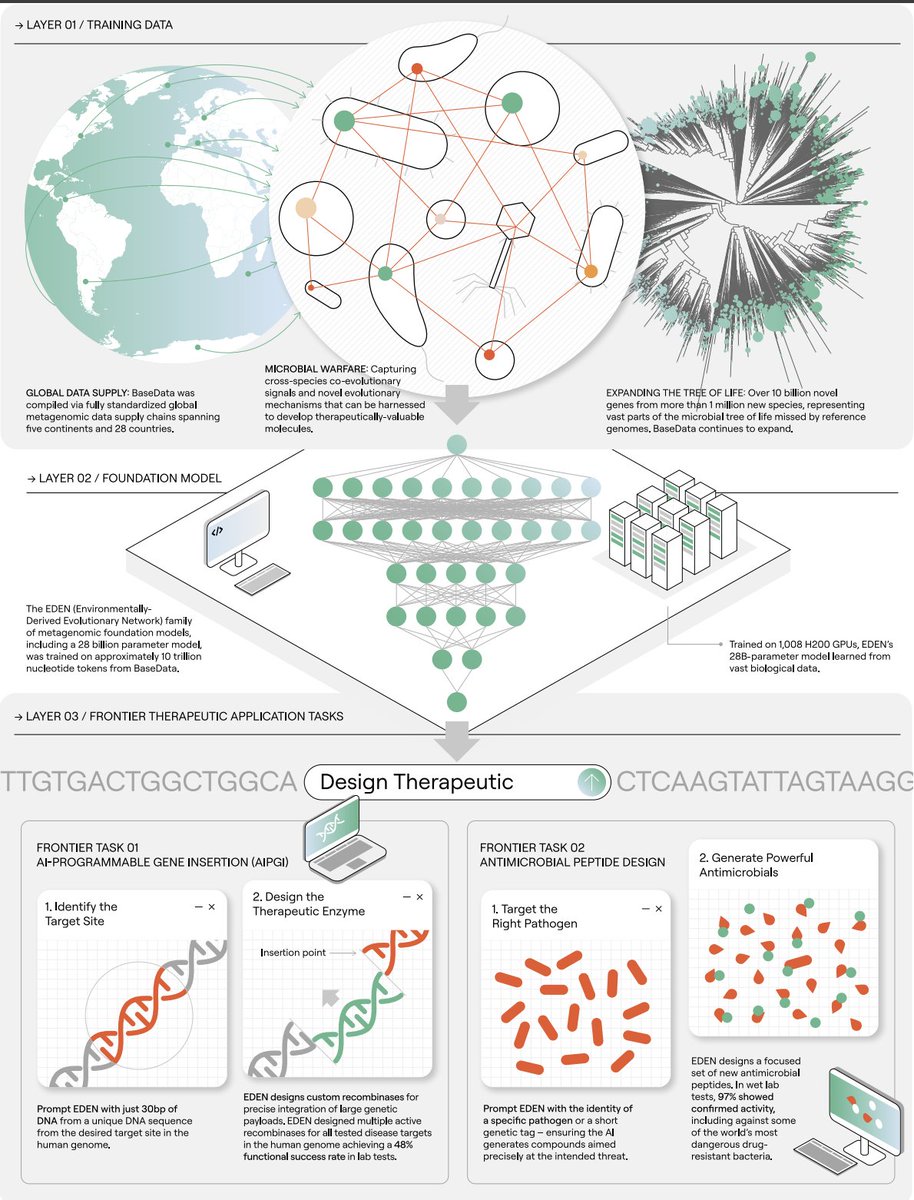
EDEN - a 28B parameter biological foundation model trained on 9.7T nucleotides equitably sourced from nature. Eden's tasks includes generating gene-editing enzymes, AMPs + synth microbiome
https://t.co/4SugNlnpx9
Proud to be part of the amazing int'l team that worked on this
EDEN - a 28B parameter biological foundation model trained on 9.7T nucleotides equitably sourced from nature. Eden's tasks includes generating gene-editing enzymes, AMPs + synth microbiome
https://t.co/4SugNlnpx9
In an incredible collaboration with @Basecamp_Res and @nvidia, today we announce EDEN: an evolution-scale DNA foundation model built on a simple idea—if we dramatically expand the biology we learn from, AI can stop overfitting to a handful of model organisms and start learning principles that truly generalize.
Our lab at @Penn helped validate EDEN, which is trained to learn the underlying grammar of biology from vast parts of life we’ve barely sampled.
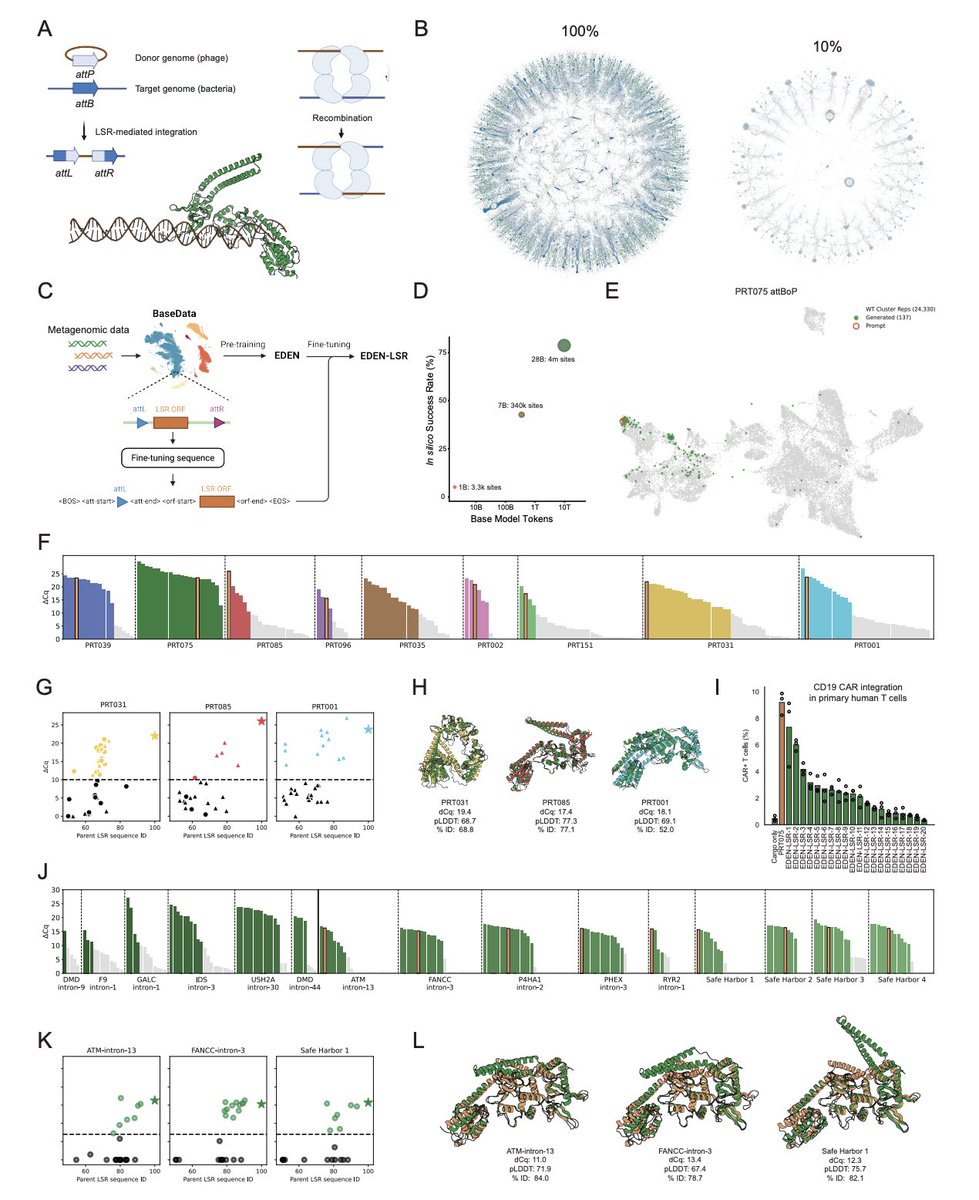
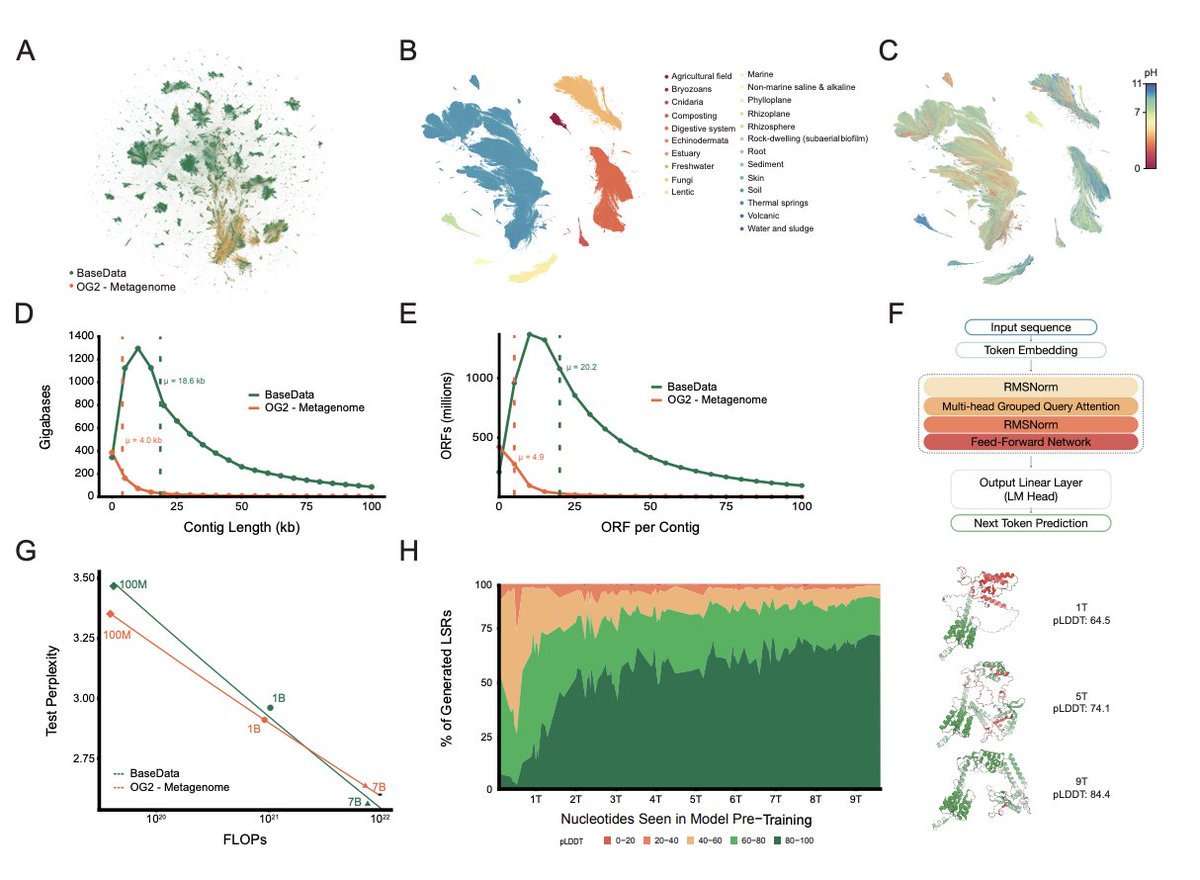
EDEN’s largest model (28B params) was trained on 9.7T nucleotide tokens from BaseData, a dataset enriched for environmental and host-associated metagenomes, phage, and mobile genetic elements — including 10B+ novel genes from 1M+ newly discovered species.
One example: using EDEN, we designed new antibiotic peptides with 97% experimental success (32/33 active) — including potent candidates against critical-priority pathogens.
More broadly, I’m excited by what this represents: scaling biodiversity changes what models can learn, and it moves us closer to foundation models that don’t just read biology — they help us design within it.
Huge thanks to this incredible team: @GeraldeneM49733, Gavin Ayres, @carlagrec, Keith Kam, Gus Minto-Cowcher, John St John, Tanggis Bohnuud, @bakalar_h, @wchowb, Robert Pecoraro, @mdt_torres, Aaron Kollasch, @leungmarcus, @qsirelkhatim, @francescofarin, Connor McGinnis, Srijani Sridhar, Daniel Anderson, @FrancescoOTERI3, Ali Takhabakshi, Jeremie Dona, @TylerShimko, Cedric Stenbeeke, Alexandros Papadopoulos, Malcolm Krolick @JohnsHopkins, @fspoen@OPIGlets@UniofOxford, Purba Gupta, Sandeep Kumar, Anne Bara, Jared Wilbur, @ferruz_noelia@CRGenomica, Timur Rvachov, Fangping Wang, @Hanqun_CAO, Hyun-Su Lee, Japan Mehta, Raphael Chaleil, Valerio Pereno, @potti_siddharth@Stanford, Chris Emerson, Roy Tal Dew, @KevinKaichuang@MSFTResearch@MSRNE, @exnx, @TadimetiNeha, @BanfieldJill@UCBerkeley, Alicia Frame @Azure, @bolton_emma_, @druau, Rory Kelleher, @anthonycosta, @kpowgerade, @glen_gowers, Oliver Vince, Jonathan Finn, & Philipp Lorenz!
Link to paper: https://t.co/ZVkZDPcktS
EDEN: a family of genomic language models trained on up to 9.7 trillion nucleotides from @Basecamp_Res 's BaseData can design large serine recombinases, bridge recombinases, and antimicrobial peptides.
https://t.co/vIm0THyc5T
🧬 The more biology AI understands, the faster we unlock breakthroughs.
As AI leaders gather in the UK, @nvidia is putting a spotlight on @Basecamp_Res as one of the UK’s top ‘AI Makers’—alongside @wayve_ai , @synthesiaIO & @IsomorphicLabs
With 10B+ sequences in the world’s largest and fastest growing biological database, we're training foundation models to power the next wave of programmable medicines.
👉 Read NVIDIA’s 'AI Makers' blog: https://t.co/UBqqXppEmZ
How do you collect data at a planetary scale to understand biological superintelligence—and turn that flood of info into a foundation for AI?
We’ve been working on it at Basecamp Research—and now we’re teaming up with Microsoft & NVIDIA AI to share what we’ve learned at #SXSW2026.
Our proposed session, “Decoding Nature: How AI is Learning to Program Biology,” explores how foundation models are learning to read & write DNA—unlocking breakthroughs in health, sustainability & beyond.
If that sounds worth a spotlight at SXSW, we’d love your vote.
🧬 Head to SXSW PanelPicker: https://t.co/vFkpFpBSSJ
🧠 Search “Decoding Nature”
❤️ Hit the heart next to the session
Every vote helps shape not just the festival—but the future of AI x biology.
#PanelPicker #Health #AI #SyntheticBiology
Can AI decode the Tree of Life? 🌍🧬
It’s a question @Basecamp_Res is obsessed with—fueling our mission to sample the planet and use the data we collect to train next-gen foundation models.
Huge thanks to @Microsoft, @nvidia, and @agency_noir for capturing our story in a new documentary 🎥
Watch the full film here: https://t.co/ObfLCH9ybY
If you are at #ISMBECCB2025🧬 Check out @carlagrec talk at the Trends in AI: A UK Perspective session on Monday Jul 21
She will be representing the Genomics and @Basecamp_Res team talking about how we built and expanded genomic/protein space by sampling untapped biomes on 🌎
🍃 🧬 Basecamp Research is unlocking nature’s blueprint to accelerate breakthroughs in drug discovery, R&D, and beyond.
With #AI accelerated by Microsoft Azure and NVIDIA, they’re creating one of the world’s largest biological databases—fueling scientific innovation across industries.
🎥Watch the series to see how #AI is solving global challenges: https://t.co/OS7vggrJcO
.@Basecamp_Res just unveiled BaseData: the world’s most diverse biological dataset, built from over 1 million novel species and 9.8 billion protein sequences. It’s a major leap forward for AI-powered biology—fueling breakthroughs in therapeutics, sustainability, and beyond.
More in @GENbio from @xiaofei_lin: https://t.co/s4sWhgw8QT
AI sees differently.
But when most of the data looks the same, there's not much for it to learn.
That’s the case in biology—where a staggering 68% of all sequence data in the SRA comes from just five species. 🧬 (1/N)
🧬 News alert: We’re bringing BaseData out of stealth — the world’s largest and fastest growing biodiscovery dataset, built in collaboration with scientists across 26 countries.
🔍 BaseData adds 9.8 billion newly discovered protein sequences to the known tree of life — expanding it by over 10x beyond what public datasets currently offer.
🌍 Why does this matter? Because this biological richness will help us break through the data wall holding back Bio AI performance. We’re training biological foundation models on BaseData in partnership with @NVIDIAAI
This is a huge step forward in understanding biology and unlocking next-gen biotech.
📰 Huge thanks to @AndrewE_Dunn and @endpts for covering the story. Read the article: https://t.co/HMaCWwYlwp
And our preprint: https://t.co/tiy27Meszm
#AIForBiology #GTCParis #DrugDiscovery
@Ski308 @5uperHalfs Berlin was definitely the gold standard, no queues anywhere, even at the post erdinger non alcoholic beer tents 😆. Run was smooth, the starting organisation of waves was smooth, the expo was smooth, bag check smooth. Even had warm drinks during the run b/c it was a cold day.
@5uperHalfs Reading online, Lisbon has been chaotic pre,during,post run last 2yrs. Shame the other cities have been amazing! Perhaps a review of Lisbon organisation needs to be considered, and should have learned from past mistakes. Read that London marathon events is consultants for 2025.
The @FTWeekend dives into @Basecamp_Res mission to sequence nature’s DNA in Earth’s wildest places — all to train next-gen AI foundation models.
Grateful to @hannahkuchler for joining an expedition & telling the story.
🧬🌍
Read with a gift link (no paywall): https://t.co/s2206funbL
@GNRailUK Hi I'm stuck at Welwyn North and the train driver said that there is a fire and to look for alternative transportation so will take a taxi, which I believe will be compensated as usual.
AI’s next leap in drug discovery needs new data. Our friends at @apheris_AI are helping pharma pool what they have. At @Basecamp_Res, we built a new dataset from scratch. When trained on only a fraction of it, AlphaFold made 6x more accurate predictions.
Excited to be supporting @open_fold as members too. Stay tuned for announcements!
🔬Nature: AlphaFold is running out of data — so drug firms are building their own version https://t.co/9mnI8XSFos
🚀 Basecamp Research: Improving AlphaFold performance with a global metagenomic & biological data supply chain https://t.co/rsBOMUf8KM