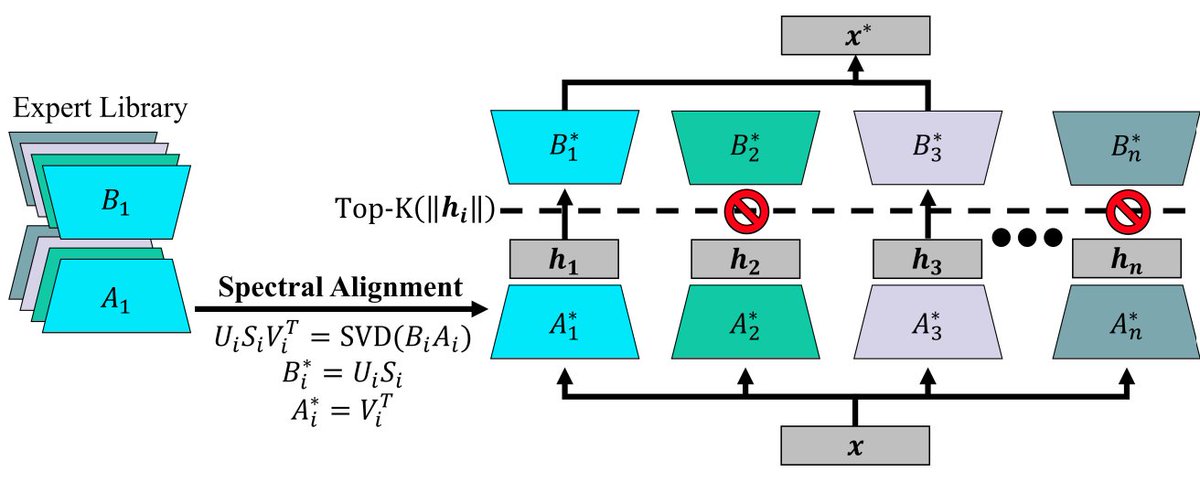
Did you know that LoRA A matrices can be frozen at init w/o degrading performance? 🤯
We leverage this trick to construct an unsupervised routing procedure that achieves identical performance to the previous best with orders of magnitude fewer FLOPs and ~50% less GPU memory. 🧵
@investingidiocy Great stuff. I've been tinkering with copulas for doing something on the spectrum of fake->real data. Real correlation structure/fake marginals or real marginals (through ECDF) and fake dependence structure (tail dependence or correlation generally). Quite a nice framework.
AI is making you stupid. Today, we're introducing the all new Oboe, designed to make you smarter.
Think about the last 10 answers you got from an LLM. How many of them do you actually remember? Probably none, because LLMs are not good teachers.
But @oboelabs helps you learn the way humans are supposed to: through guided conversations, frequent checks for understanding, real-time adjustments, and multiple formats for all learning styles.
Here's everything we're introducing today:
JHU mmBERT extended from 8k to 32k token length by vLLM Semantic Router Team. Cutting edge results on 1,800+ languages, now with longer context!
https://t.co/maN3bT1X17
@ChromeHODLs @hillery_dan That's definitely easier, just might not be optimal depending on your tax situation. Assuming you can almost capture both rates, swapping back and forth with T-bills would compound faster up to a 25% tax. Tax free accounts, if available, is the real way to go.
@ChromeHODLs @hillery_dan Opportunity cost. If you can capture the dividend by only tying up your capital for a couple of days then the rest of the month that capital can be making money elsewhere.
Summer '26 PhD research internships at Microsoft Copilot Tuning. Continual learning, complex reasoning and retrieval, nl2code, data efficient post-training.
https://t.co/HM4cKqEhgW
🚨Check out the paper with @ben_vandurme for more juicy details, like how we improve SpectR and SEQR by calibrating the adapter norms!
https://t.co/xicyvjVO0E
Did you know that LoRA A matrices can be frozen at init w/o degrading performance? 🤯
We leverage this trick to construct an unsupervised routing procedure that achieves identical performance to the previous best with orders of magnitude fewer FLOPs and ~50% less GPU memory. 🧵
SEQR provably routes to the same adapters as SpectR, yielding the same high level of task performance at a fraction of the cost 🤑. Like previous unsupervised approaches, SEQR is secure, with no risk of data leakage if LoRA B matrices are kept private!🔐
XLM-R has been SOTA for 6 years for multilingual encoders. That's an eternity in AI 🤯
Time for an upgrade. Introducing mmBERT: 2-4x faster than previous models ⚡ while even beating o3 and Gemini 2.5 Pro 🔥
+ open models & training data - try it now!
How did we do it? 🧵
@jxmnop Cool stuff, when we did RE-Adapt (https://t.co/pHUJmIDZIx) with llama we saw many of the base->instruct weight updates are approx. low rank but some layers were not. You could repeat your experiment with the llama instruct models to see how close to base you actually get.
I am growing an R&D team around Copilot Tuning, a newly announced effort that supports adaptation at a customer-specific level.
Join us! https://t.co/kVocnuTrKN
We collaborate with a crack team of eng and scientists that support the product, also growing!
https://t.co/typyUXfQ8g
SpectR was accepted at @COLM_conf!
Our follow-up work, LoRA-Augmented Generation (LAG), combines SpectR w/ a first pass filtering of adapters using Arrow routing. LAG is significantly more efficient, enabling SpectR like performance with much larger LoRA libraries!