CS Ph.D. student @Columbia & Research Scientist @NVIDIARobotic | Prev. Meta FAIR Embodied AI, Boston Dynamics AI Institute, Google X #Vision#Robotics#Learning
1/ World models are getting popular in robotics 🤖✨
But there’s a big problem: most are slow and break physical consistency over long horizons.
2/ Today we’re releasing Interactive World Simulator:
An action-conditioned world model that supports stable long-horizon interaction.
3/ Key result:
✅ 10+ minutes of interactive prediction
✅ 15 FPS
✅ on a single RTX 4090🔥
4/ Why this matters: it unlocks two critical robotics applications:
🚀 Scalable data generation for policy training
🧪 Faithful policy evaluation
5/ You can play with our world model NOW at https://t.co/SBqVDzYn86. NO git clone, NO pip install, NO python. Just click and play!
NOTE ⚠️
ALL videos here are generated purely by our model in pixel space! They are **NOT** from a real camera
More details coming 👇 (1/9)
#Robotics #AI #MachineLearning #WorldModels #RobotLearning #ImitationLearning
Wow, thank you Jack for the thread! I’m impressed by how quickly you put this together.
In the talk, I discussed how combining vision/touch and structured world models can help robots reason about physical interactions, and address some of the key bottlenecks in robot learning.
Our work on real-to-sim robot policy evaluation will be presented this week at ICRA 2026! #ICRA2026
https://t.co/QVzptkRYqC
Keywords: policy evaluation, real2sim, Gaussian Splatting, deformable objects
Check our code on GitHub and stop by our poster on Thursday!
Come chat with @shashuo0104 and me this afternoon from 15:00–16:30 at ThI2I.288!
We’ll be discussing how to construct digital twins with systematic alignment to the real world, and how this could help unlock one of the key bottlenecks in developing robot policies: evaluation.
Introducing STACK: Learning Composable Skills by Discovering Spatial and Temporal Structure with Foundation Models.
How can robots learn skills that generalize when the world change? The default answer has been more data. It works, but it's expensive and slow.
During my final year at @Stanford, our team explored a different idea: can robots discover the right abstractions from just a handful of expert demonstrations to enable strong generalization?
STACK uses foundation models to discover spatial and temporal structure from a handful of demonstrations, then learns composable skills on top of that structure.
With just 5 - 10 real-world demonstrations per domain, across three manipulation settings, and without hand-designed task decomposition.
For more details, including real-world demos: https://t.co/Rkt3VXH2Nm
(1/n)
🎉 We added 2 SOTA WAMs to the RoboLab Leaderboard 🎉
Current leaders on RoboLab-120 (specific instr.):
🥇Cosmos3-Nano-Policy (39.7%)
🥈π0.5 (28.1%)
🥉DreamZero (28.1%)
→ See full results at: https://t.co/Le8jykn5jo
→ All policy clients available at: https://t.co/wQH4Py6zJ8
Excited to share a few presentations, demos, and workshop talks from our group and collaborators at #ICRA2026!
We will present recent work on real-to-sim-to-real robot policy evaluation, model-based planning with learned dynamics, and multi-modal manipulation.
We will also have a joint live demo between @SceniXai and @ADI_News on real-to-sim-to-real cable manipulation at the ICRA exhibition. This is a small teaser of what we have been building, with more to come soon!
If you are at ICRA, please stop by the sessions or the demo booth. Happy to chat about robot learning, simulation, world models, and sim-to-real!
Super proud to be part of NVIDIA's Cosmos3 Physical-AI Omnimodal Foundation Model. Topping the image/video/sound generation benchmarks and Robot Policy Benchmarks 😀
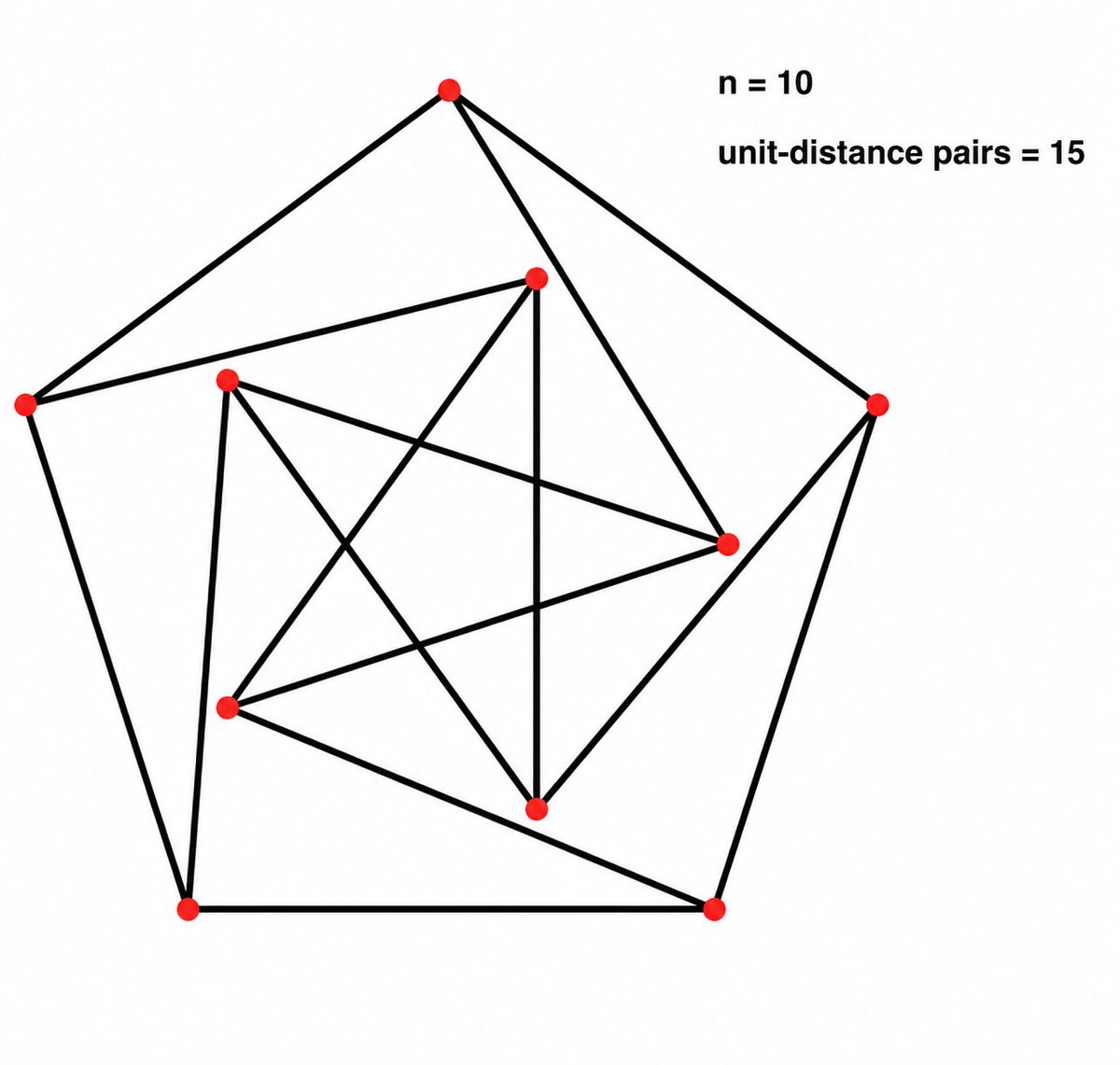
🧵(1/8) An @OpenAI internal reasoning LLM achieved an AI Math milestone: solving an open problem central to its mathematical subfield— in this case, the unit distance problem of discrete geometry.
We came across it in a side quest to truly push our model on the hardest problems.
We are organizing an RSS workshop on Tactile Sensing for Robotic Foundation Models!! Join us for talks from our all-star speakers and submit your papers for a chance to win your paper awards!!
Excited to announce our #RSS2026 workshop on Tactile Sensing for Robotic Foundation Models!
We are calling for papers. Ant Group will sponsor a $500 Best Paper Award, and RAI Institute will sponsor two $200 Runner-up Awards. We will also provide several travel supports ($300 each).
Join us in Sydney!
Website: https://t.co/5evoIiKVvT
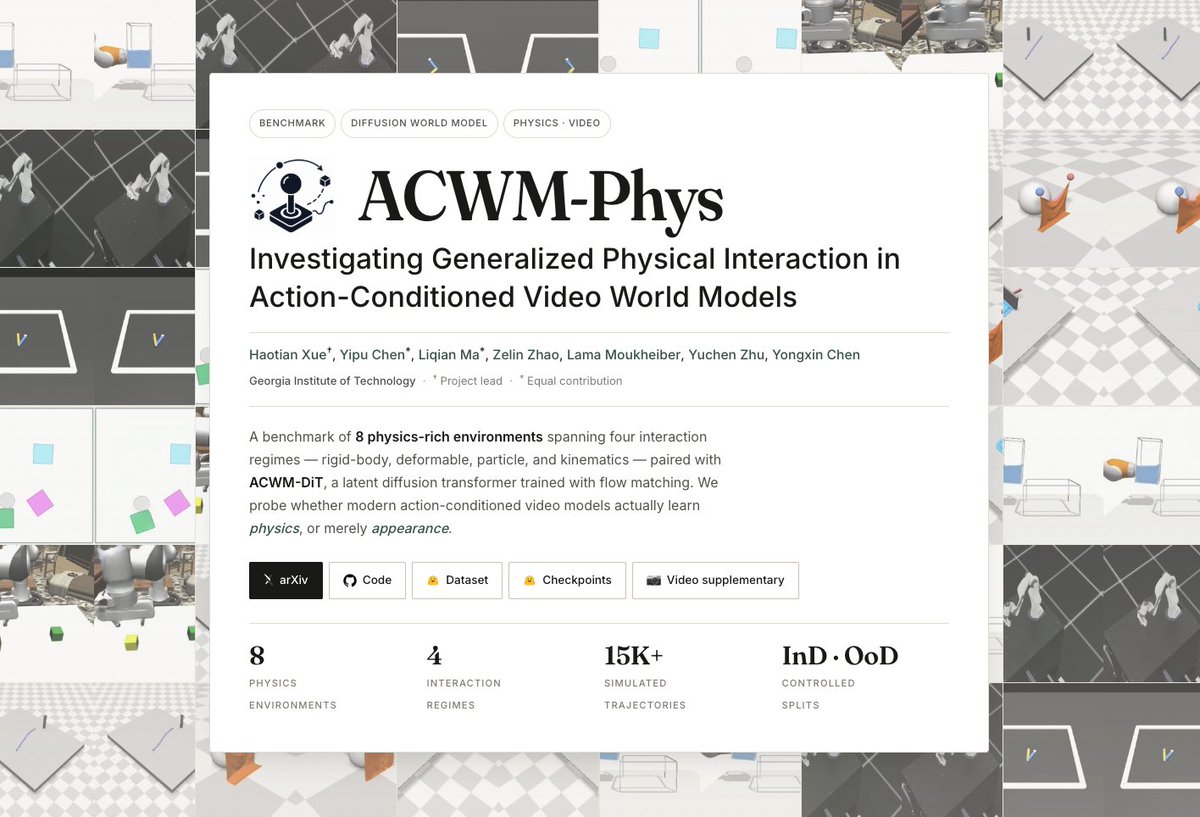
❓ How well can ACWMs learn different types of physics e.g. rigid bodies, deformables, particles, and kinematics? ❓ Can they actually generalize beyond the training distribution?
🚀 We are excited to release ACWM-Phys: a Physics-rich investigation into Action-Conditioned video World Models!
While most world-model research today focuses on ego-view game play or narrow robot-arm manipulation, we ask two questions:
We collect 15K+ simulated trajectories across 8⃣ environments spanning 4⃣ physics regimes (rigid contact🧊, particle dynamics🌊, kinematics🦾, and deformable contact🧥), each with a controlled, physically meaningful InD ↔ OoD split (unseen cube counts, larger cloth, doubled particle counts, expanded workspaces, …).
We train ACWM-DiT, a latent diffusion transformer with flow matching, and find a pattern: simple low-dimensional geometry generalizes cleanly, but contact-rich deformation, particle dynamics, and high-DoF kinematics break down current ACWMs still capture visual statistics, not physical laws. We also did some ablation to draw insights about model arch, data scaling and action complexity.
The datasets and checkpoints for all 8 environments have been publicly released:
📃Paper: https://t.co/x7ABoXMMaU
📘Page: https://t.co/3PwvKkUfuQ
🐙Code: https://t.co/vYMw6uLK24
📠Dataset: https://t.co/xskCOjYN5w
🤗Checkpoints: https://t.co/YC2SzKHXa2
Also shout out to @YongxinChen1 , Yipu, Liqian, Zelin, @lamawm7@YuchenZhu_ZYC
@nilaksh404 Interesting study! Do you think it is due to inherent disadvantages of reconstruction-based world model or design choices of VAE? In our work, we do find reconstruction-based world model can still work well. But happy to learn more about your takes!
Glad to see that people are using data from our Interactive World Simulator and building better model within months of our release!!! Definitely an exciting time for world model!
𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐚 𝐰𝐨𝐫𝐥𝐝 𝐦𝐨𝐝𝐞𝐥 𝐢𝐧 𝐚 𝐥𝐚𝐭𝐞𝐧𝐭 𝐬𝐩𝐚𝐜𝐞 𝐜𝐚𝐩𝐭𝐮𝐫𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐞 𝐞𝐯𝐨𝐥𝐮𝐭𝐢𝐨𝐧, 𝐮𝐬𝐞 𝐢𝐭 𝐟𝐨𝐫 𝐰𝐨𝐫𝐥𝐝 𝐚𝐜𝐭𝐢𝐨𝐧 𝐦𝐨𝐝𝐞𝐥 𝐚𝐧𝐝 𝐯𝐢𝐬𝐮𝐚𝐥 𝐫𝐞𝐢𝐧𝐟𝐨𝐫𝐜𝐞𝐦𝐞𝐧𝐭 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠.
🚀 Introduce RLA-WM, a simple and efficient state-of-the-art world model. ✂️ RLA-WM decouples a world action model from the video backbone, and enables the first demonstration 🎬 of visual reinforcement learning entirely inside our world model, learned only from videos (𝚆̲orld 𝙼̲odel‑based 𝚁̲𝙻̲).
⚡ Talk is cheap, open the notebook in Colab ▶️ to run RLA-WM and WMRL in a single T4 GPU!
🌐 Website 📄 Paper: https://t.co/5t6zaHaH1g
▶️ Colab: https://t.co/wTQfSXBPn6
👏 Our work, "𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗩𝗶𝘀𝘂𝗮𝗹 𝗙𝗲𝗮𝘁𝘂𝗿𝗲-𝗕𝗮𝘀𝗲𝗱 𝗪𝗼𝗿𝗹𝗱 𝗠𝗼𝗱𝗲𝗹𝘀 𝘃𝗶𝗮 𝗥𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗟𝗮𝘁𝗲𝗻𝘁 𝗔𝗰𝘁𝗶𝗼𝗻", is a collaborative effort by computer vision and robotics researchers from Rutgers University, Purdue University, and the University of Wisconsin‑Madison. Shoutout to my amazing collaborators!
@XuZhengtong , Yutian Tao, @YepingWang , @yushe_1 , @ABoularias
𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐚 𝐰𝐨𝐫𝐥𝐝 𝐦𝐨𝐝𝐞𝐥 𝐢𝐧 𝐚 𝐥𝐚𝐭𝐞𝐧𝐭 𝐬𝐩𝐚𝐜𝐞 𝐜𝐚𝐩𝐭𝐮𝐫𝐢𝐧𝐠 𝐬𝐭𝐚𝐭𝐞 𝐞𝐯𝐨𝐥𝐮𝐭𝐢𝐨𝐧, 𝐮𝐬𝐞 𝐢𝐭 𝐟𝐨𝐫 𝐰𝐨𝐫𝐥𝐝 𝐚𝐜𝐭𝐢𝐨𝐧 𝐦𝐨𝐝𝐞𝐥 𝐚𝐧𝐝 𝐯𝐢𝐬𝐮𝐚𝐥 𝐫𝐞𝐢𝐧𝐟𝐨𝐫𝐜𝐞𝐦𝐞𝐧𝐭 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠.
🚀 Introduce RLA-WM, a simple and efficient state-of-the-art world model. ✂️ RLA-WM decouples a world action model from the video backbone, and enables the first demonstration 🎬 of visual reinforcement learning entirely inside our world model, learned only from videos (𝚆̲orld 𝙼̲odel‑based 𝚁̲𝙻̲).
⚡ Talk is cheap, open the notebook in Colab ▶️ to run RLA-WM and WMRL in a single T4 GPU!
🌐 Website 📄 Paper: https://t.co/5t6zaHaH1g
▶️ Colab: https://t.co/wTQfSXBPn6
👏 Our work, "𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗩𝗶𝘀𝘂𝗮𝗹 𝗙𝗲𝗮𝘁𝘂𝗿𝗲-𝗕𝗮𝘀𝗲𝗱 𝗪𝗼𝗿𝗹𝗱 𝗠𝗼𝗱𝗲𝗹𝘀 𝘃𝗶𝗮 𝗥𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗟𝗮𝘁𝗲𝗻𝘁 𝗔𝗰𝘁𝗶𝗼𝗻", is a collaborative effort by computer vision and robotics researchers from Rutgers University, Purdue University, and the University of Wisconsin‑Madison. Shoutout to my amazing collaborators!
@XuZhengtong , Yutian Tao, @YepingWang , @yushe_1 , @ABoularias
Excited to release LeFlexiTac: https://t.co/cahgrUYXuH!
@LeRobotHF has made low-cost robot learning much more accessible. With FlexiTac tactile sensors from our lab (https://t.co/zF3yjhB14b), LeFlexiTac adds a tactile sensing layer to the platform, enabling policies to reason about contact, not just vision.
The setup is designed to be low-cost and accessible, and we hope more people will try it out and explore tactile robot learning!
Great work led by @NaianTao, in collaboration with Yifan He, @wesleymaa, and @binghao_huang! 👏
1/ 🤲 LeRobot has made low-cost robot learning widely accessible — but most policies are still blind to contact.
Today we release LeFlexiTac: a tactile extension for the LeRobot platform using FlexiTac sensors. Make tactile robot learning as easy as possible.
Project page: https://t.co/6PY8oTmAjU
Code/docs: https://t.co/11HW0Zwrtb