ai agents made solo building fast enough to become dangerous.
you can now ship a first version over a weekend, feel productive, and still learn almost nothing about the market.
the hard questions did not go away:
◽️ who is the customer?
◽️ what pain are you actually solving?
◽️ why would they pick your product?
◽️ what does it cost to keep running?
◽️ when do you kill or change the idea?
my rule: do not let the agent turn every product idea into a coding project.
turn it into a market test first.
landing page, demo, waitlist, early access, manual payment, invoice, whatever is legal and simple in your situation.
one small payment is more useful than 50 supportive comments.
also set a deadline.
example: 10 days to get 8 leads or 4 payments. if that does not happen, you do not need 6 more features. you need to fix the offer, test a different audience, or move on.
the best use of ai agents is not "build forever faster".
it is getting to the uncomfortable part faster:
showing the product to real people, asking for money, tracking what happened, and deciding with evidence instead of vibes.
shipping is cheap now.
learning is still the expensive part.
claude fable 5 is a quota killer.
it feels smart.
really smart.
then you give it a serious coding task and remember the annoying part:
the best model in the room can still be the wrong daily driver if it burns your limits too fast.
for vibe coding, i don't care if Fable wins another clean benchmark.
i care about the messy tests:
◽️ can it hold a real repo in context?
◽️ can it turn screenshots into usable code?
◽️ does it start making things up on long tasks?
◽️ does one good run eat half your daily quota?
Anthropic is giving Fable to Pro/Max/Team/Enterprise users until June 22.
After June 23, it moves to usage credits unless they get enough capacity.
so this is not a normal rollout yet.
it is a test window.
My early take: Fable might be a monster for deep coding and research sessions.
But if every serious run burns through limits, the smartest model does not automatically become the best workflow.
Now the fun part:
what does OpenAI ship back?
your landing page is about to become the least important part of your product.
that sounds insane until you realize who the next user is.
not a person scrolling your homepage.
an agent.
a human can tolerate vague marketing, click around, watch a demo, ask support, and slowly figure out if your tool is worth paying for.
an agent will not.
it will scan your docs, pricing, security notes, API, MCP server, examples, limits, and competitor comparison.
then it will decide whether your product is safe and useful enough to recommend to the person who launched it.
if that layer is sloppy, the agent never gets to the pretty part.
this changes the product surface.
◽️ docs become part of distribution
◽️ pricing becomes a filter
◽️ API/MCP becomes the real front door
◽️ security pages become trust infrastructure
◽️ examples matter more than homepage copy
if you are building a vibe-coded tool, a side project, or internal automation, stop asking only:
"does this look good to a human?"
also ask:
"could Codex, Claude Code, or another agent understand what this does, connect to it, price it, check the risk, and compare it to alternatives?"
because the next buyer may not click your CTA.
it may read your docs and quietly decide you are not worth recommending.
most people are wasting Claude Code.
they use it like ChatGPT with repo access, then wonder why the output still feels random.
if i had 30 days to get serious about agentic development, i would rip through the public docs and build the base fast:
📷️ agent architecture:
https://t.co/QIXhOLhYvI
📷️ Claude Code 101:
https://t.co/ksOweHTuVo
📷️ Claude Code in Action:
https://t.co/wi8PGSRFFy
📷️ prompt engineering:
https://t.co/QZ5moy7sSH
📷️ prompt tutorial:
https://t.co/AAn4Rp1ajB
📷️ CLAUDE.md:
https://t.co/WAhLn65K1H
📷️ Skills:
https://t.co/EHBmeZ7YWg
📷️ MCP:
https://t.co/HMiKhLqO9J
📷️ Routines:
https://t.co/ohGuuaoDpO
📷️ Claude Code guide:
https://t.co/k4IWTgsPGE
📷️ Awesome Claude Code:
https://t.co/xFgqEmPC5b
📷️ Anthropic Academy:
https://t.co/dunV260qvM
📷️ Claude Code docs:
https://t.co/z5ZaiKqhXS
the important shift is not «write better prompts».
it is giving the agent a real work environment: project rules, context, tools, checks, and a definition of done.
otherwise you are not building an agentic workflow.
you are just paying for an expensive autocomplete box.
most people are learning the wrong layer of ai coding.
codex, claude code, hermes, opencode.
new tool every few months.
new settings.
new modes.
new tiny tricks.
the durable skill is not memorizing the interface.
it is building the workflow around the agent:
◽️ context
◽️ acceptance criteria
◽️ checks
◽️ project memory
◽️ reusable instructions
a stronger model amplifies whatever process you give it.
if the process is messy, it just goes off track faster.
ai agents do not remove the bottleneck.
they move it.
execution used to be the hard part.
now it is task clarity:
◽️ what should be done
◽️ what is out of scope
◽️ what files are safe to touch
◽️ how the result gets checked
bad task definition used to waste your afternoon.
now it wastes your afternoon 10x faster.
opus 4.8 is not the story.
everyone wants to fight over which model is smarter.
fine. have fun with the benchmark wars.
the actual shift is in the tooling layer:
◽️ claude code gets dynamic workflows
◽️ codex gets a desktop app with an in-app browser
◽️ agents start seeing your repo, running checks, and coming back with a patch
that is the part builders should care about.
the model is becoming a replaceable engine.
the leverage is in the workflow around the agent.
if your agent only answers in chat, you do not have an agent.
you have a very expensive autocomplete box.
before buying another saas subscription, check if an open-source block already solves 80% of the job.
◽️ whisper
◽️ yt-dlp
◽️ fooocus
◽️ bitwarden
◽️ plausible
◽️ penpot
◽️ appflowy
free does not mean zero cost.
you pay with setup, maintenance, backups, and security.
but with an agent next to you, these repos become building blocks.
opus 4.8 is going to feel like garbage to most people.
not because it is bad, but because the old way of testing models is dead.
if you open chat, ask it to write a landing page, compare vibes for 3 minutes, and post «meh, not a big jump» — you are probably right. for that use case, the gap is tiny now.
the real test is not chat. the real test is handing it a repo and saying: «run the migration, find the broken parts, spawn reviewers, keep going until it converges».
that is what changed.
opus 4.8 is built for long-horizon work, /goal, xhigh, /fast, dynamic workflows, ultracode, and hundreds of parallel agents arguing with each other before you see the result.
this is why the token burn discourse is backwards. people see a scary bill and miss the obvious question: how much would the same work cost if a human team had to plan it, split it, review it, redo it, and babysit it for a week?
opus 4.8 is not a better chatbot.
it is a warning that «software sprint» is becoming a very expensive way to describe agent runtime.
how to unlock it:
◽️ go to Notion
◽️ click Get Notion free
◽️ create a workspace
◽️ choose work
◽️ start the Business trial
◽️ add billing details
◽️ open Notion AI
◽️ check the model picker
◽️ run your hardest prompts
Claude for long coding / analysis.
GPT for planning / tools / knowledge work.
link:
https://t.co/fyDh71C6fP
Claude Opus 4.7 + GPT-5.5 for $0.
yes, the expensive ones.
Claude Opus costs serious money.
GPT-5.5 is locked away for most users.
but there is a door through Notion Business.
open the trial, go into Notion AI, and check the model picker.
use it for the heavy stuff:
◽️ coding agents
◽️ repo analysis
◽️ long research
◽️ image understanding
◽️ planning work you would normally burn credits on
set a cancel reminder before it renews.
your coding agent keeps drifting when every session starts from zero.
open chat.
ask for code.
explain the repo again.
repeat tomorrow.
give the agent a real working environment:
◽️ project memory
◽️ skills
◽️ rules
◽️ tests
◽️ permissions
◽️ subagents
then it has a system to follow:
read memory.
use the right skill.
stay inside permissions.
check the result before replying.
codex is having a very real sentiment shift right now.
for a while, the default vibe was simple:
Claude Code for serious agentic coding.
Codex as the interesting OpenAI thing you check once in a while.
that changed fast.
with GPT-5.5, I keep seeing more builders say the same thing: Codex is not just usable now. it is good enough to stay in the daily workflow.
the DeepSWE result matters here because it is not a cute chatbot benchmark. it is trying to measure agentic coding behavior closer to what developers actually feel in day-to-day work.
and that is the category that matters.
not the model that writes the prettiest answer.
the model that can sit inside the repo, follow the task, edit files, recover from mistakes, and keep moving without turning the whole session into babysitting.
the interesting part is not “Codex vs Claude Code” as a fan war.
the interesting part is that coding agents are now improving fast enough that your tool loyalty should be weak.
test the workflow every few weeks.
the best default can change.
Claude Code just got a security-guidance plugin.
this is the right place for security checks to live.
not as a giant report at the end.
not as a separate “please audit my code” step that everyone forgets when they are shipping fast.
inside the agent loop.
the plugin runs through hooks and checks code at three points:
◽️ file edits: catches risky patterns and commonly misused dangerous libraries
◽️ after model turns: reviews the full diff for issues that are harder to spot locally
◽️ commits: reads surrounding code to validate whether something is actually a vulnerability
that matters because agentic coding changes the failure mode.
the problem is not that the model writes one obviously bad line.
the problem is that it can make 11 small changes across a repo, all individually plausible, and the risky behavior only appears when you read the diff as a system.
Anthropic says they saw a 30-40% decrease in security-related PR comments in their internal rollout and benchmarks.
also useful: teams can add org-specific rules in `claude-security-guidance.md`, so the plugin can enforce local policies instead of pretending every codebase has the same risk profile.
this is the direction I want more coding agents to go:
less “trust me, I wrote the code”
more “I wrote the code, checked the diff, and applied the project’s rules before handing it back.”
google just pushed antigravity closer to a real agent control center.
2.0 is less “write code for me”
and more “run the work through agents.”
it now has:
◽️ scheduled agent tasks
◽️ dynamic subagents
◽️ projects across multiple folders
◽️ cli mode
◽️ voice transcription
◽️ shared limits for flash/pro
starting to feel like codex app + claude cowork territory.
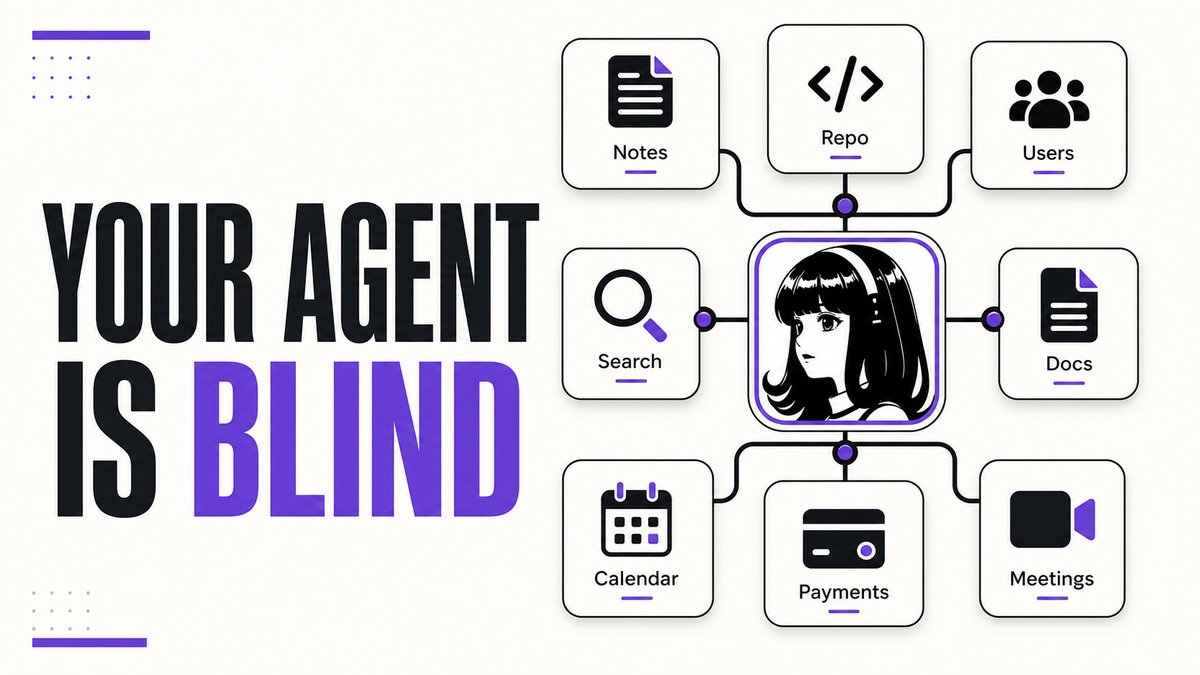
most ai agents are not actually agents.
they are chatbots with tools bolted on.
the model can be smart as hell, but if it can’t see the actual work, it still needs you to babysit every step.
and that is the part people keep missing.
agents don’t become useful because you gave them a better prompt.
they become useful when they can see the context around the project.
◽️ obsidian = memory
◽️ github = code
◽️ reddit = raw user pain
◽️ firecrawl = clean web data
◽️ google workspace = docs + calendar
◽️ discord = operational channels
◽️ stripe = business context
◽️ fireflies = meeting history
without this, the agent is blind.
it guesses.
it asks for context.
it makes you paste the same stuff again.
it feels smart for 5 minutes and then breaks on the real workflow.
with this, the agent starts operating on the actual project.
not just answering questions.
+ reading the repo
+ checking the docs
+ pulling user signals
+ remembering meetings
+ looking at payments
+ connecting the dots
that is why the hermes integrations list is interesting.
not because every integration is mandatory.
but because it shows where agent workflows are going: the model is not the product.
the context layer is.
codex in chatgpt mobile is basically a remote for your local agent session.
check what it did, throw in a correction, approve the next step.
vibe coding from a walk, a coffee shop, or the bathroom is a very real workflow now.
🤡 ig call gets rekt but live trading saved it
wei played like absolute shit, couldn't hit stunned targets with ults
looks like the boys celebrated their demacia cup win a bit too hard
what went wrong:
– overestimated ig's readiness after «championship hangover»
– underestimated how sharp al would look
– wei wasn't the same player from demacia cup – terrible execution
the save:
+ pre-match position took the L
+ BUT live trading during games let me hedge out
+ closed the day slightly green instead
lessons learned:
+ championship hangovers are real in esports
+ live reads > pre-match predictions sometimes
+ having a hedge plan matters
+ first week of split = high variance always
moving forward:
more experience = more money in future
long season ahead, tons of games to find edges
current lol record: 12-5 (71%)
still profitable, still learning
⚠️ variance hits everyone, adapt and survive
🎯 ig vs al tomorrow – penciling this one in, not inking it
market has al at 68% / ig at 32%
i see small edge on ig but playing this VERY carefully
why this isn't a confident call:
al are defending split 2 champions with same roster
flandre/tarzan = proven elite veterans
only concern: they haven't played since worlds (2+ months rust)
ig won demacia cup but that's preseason
this is different level of competition
the lean: ig 34¢ for 2-3% bankroll
not 5% like wbg match – this is lower confidence
reasoning:
– al main roster sat out demacia (resting after worlds)
– ig hot with wei in peak form
– first match rust factor is real
– 34¢ underprices ig's current momentum
but here's my actual plan:
small position pre-match
MAIN action comes in live betting after seeing:
→ draft quality
→ early game execution
→ who looks sharper
might hedge with mirror bets (ig to win tournament + al to win game 1), this is a «watch and react» spot, not «load the boat» spot
al's ceiling is higher, talent gap favors them
but timing favors ig (form vs rust)
current lol record: 12-4 (75%)
market: https://t.co/lTIJuaTZWv
⚠️ pencil prediction, waiting for live reads to commit