Post-quantum crypto is supposed to be slow.
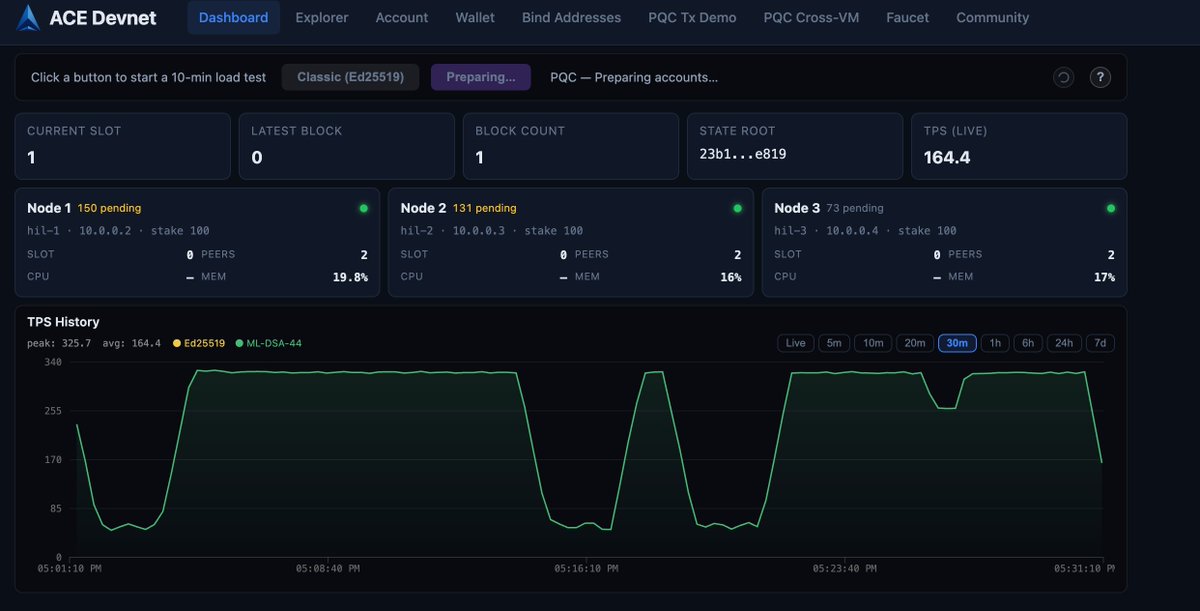
We ran ML-DSA-44 and ED25519 head-to-head on the same load runner. ML-DSA-44 hit ~470 TPS. ED25519 hit ~400, not ceiling. The quantum-resistant one is faster and it outperforms ED25519.
This is what happens when you stop putting PQC signatures on-chain. ZK-ACE powers our chain by replacing signature objects with identity-bound ZK proofs — consensus-visible footprint drops to ~160 bytes per transaction.
The circuit is small by design: 341 active rows and 361 AIR constraints on Circle STARK (14.5ms prove, 1.1ms verify), or 2,155 R1CS constraints on Groth16 with 128-byte proofs. That's 500–2,300× fewer constraints than verifying a PQC signature inside a ZK circuit.
3-node devnet, 400ms slots, 600ms finality. Not the ceiling.
None of this works without the ZK and STARK foundations the community has built. Thank you.
Paper: https://t.co/4JEc2VG56X
Devnet: https://t.co/uU0KTZElAR
@EliBenSasson@VitalikButerin@StarkWareLtd@aztecnetwork@RiscZero
#PostQuantum #ZKProof #PQC #Blockchain #CircleSTARK
ML-DSA signatures are 2,400 bytes. Ed25519 is 64.
That 37× bloat isn't a parameter problem — it's the wrong model entirely.
ZK-ACE replaces signature objects with identity-bound ZK statements. No PQC sig ever touches the chain. ~160 bytes per tx. 500–2300× fewer constraints than in-circuit PQC verification.
Deep dive → ZK-ACE: Why Post-Quantum Blockchains Need to Rethink Authorization from Scratch https://t.co/bw4O4jmcJT
#ZeroKnowledge #PostQuantum #ZKProofs #Web3 #Crypto #PQC
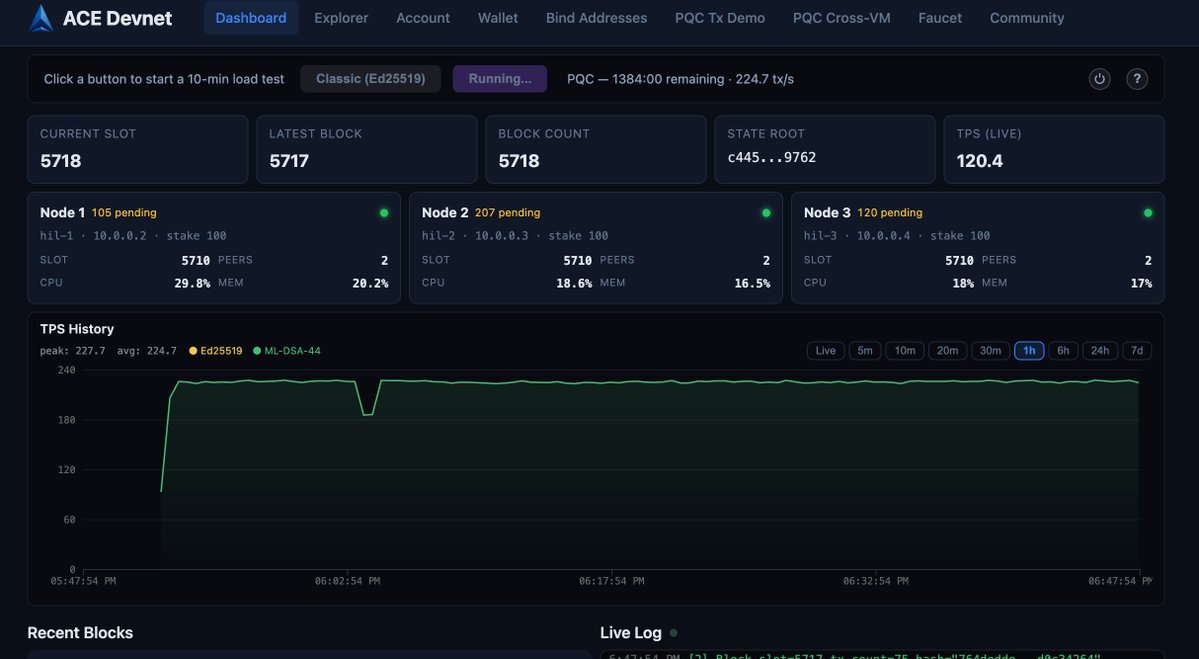
ACE Devnet has been running a continuous PQC (ML-DSA-44) load test for almost 7 hours.
3 validators remain live and synced.
32,500+ blocks produced.
PQC transactions are still being processed under sustained load.
Throughput is not yet where we want it, but the important signal is durability: the network keeps making progress under long-running post-quantum transaction pressure.
Next focus: tighter throughput stability and higher sustained TPS.
@dara_venture@EliBenSasson@a_71104@suppvalen #PQC #Web3
Post-quantum crypto is supposed to be slow.
We ran ML-DSA-44 and ED25519 head-to-head on the same load runner. ML-DSA-44 hit ~470 TPS. ED25519 hit ~400, not ceiling. The quantum-resistant one is faster and it outperforms ED25519.
This is what happens when you stop putting PQC signatures on-chain. ZK-ACE powers our chain by replacing signature objects with identity-bound ZK proofs — consensus-visible footprint drops to ~160 bytes per transaction.
The circuit is small by design: 341 active rows and 361 AIR constraints on Circle STARK (14.5ms prove, 1.1ms verify), or 2,155 R1CS constraints on Groth16 with 128-byte proofs. That's 500–2,300× fewer constraints than verifying a PQC signature inside a ZK circuit.
3-node devnet, 400ms slots, 600ms finality. Not the ceiling.
None of this works without the ZK and STARK foundations the community has built. Thank you.
Paper: https://t.co/4JEc2VG56X
Devnet: https://t.co/uU0KTZElAR
@EliBenSasson@VitalikButerin@StarkWareLtd@aztecnetwork@RiscZero
#PostQuantum #ZKProof #PQC #Blockchain #CircleSTARK
@uche2v@EliBenSasson The readers should not be allowed to downvote but allowed to filter contents by scores or categories . The AI engine should be the single source of truth. — just some ideas — the ai engine operator is responsible for improving the quality of the knowledge
Here are two examples: Where does petroleum come from? The mainstream view is that it originates from ancient organisms. However, some people still believe it comes from deep within the Earth rather than from ancient life; for this theory, we might assign a confidence level of 90% to 95%. On the other hand, some people believe the Earth is flat, and we should assign a confidence level of 0% or less than 1% to that.
@EliBenSasson What about this way: When someone posts something, the ai automatically scores its authenticity. Readers can filter contents by scores like filtering listings on e-commerce websites
@uche2v@EliBenSasson Rules can be defined at implementation stage but I think it’s doable from academic papers (which have been proven correct) then other knowledge bases, then create rules. Again we can expect 100% accuracy.