🧵 Deli AutoResearch SKILL is now officially open source! 🎉
https://t.co/V3lwwdyQm8
Alongside it, we’re dropping our 4th survey paper — this time on Self-play.
https://t.co/SEb2qoKCI6
Inspired by AlphaZero, we got a powerful insight: prior knowledge doesn’t always lift the ceiling.
Models can discover more globally optimal solutions just by playing against themselves.
The biggest change in this paper?
For the first time, the AutoResearch Agent autonomously planned GPU experiments — and submitted actual RL runs on the DeepSeek 285B model.
The entire RL pipeline — experiment design, code writing, running, debugging, and conclusion summarization — was 100% automated, with zero human intervention from me.
This was incredibly difficult, but an incredibly important step.
https://t.co/kuZZNux5RH
GRPO is the tool being called by the AutoResearch Agent here.
We see this as the beginning of our Continual Learning research journey. 🚀
As always, this is my personal research project, unaffiliated with any organization. All views are my own.
#AI #ReinforcementLearning #SelfPlay #OpenSource #AutoML #ContinualLearning #DeepSeek
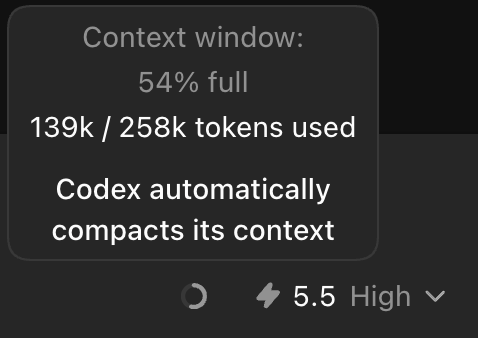
Codex can get dumber and slower on long sessions.
Here's the fix:
1. Run Process_narration=false
This will stop Codex from showing you all the planning steps, resulting in saving a lot of output tokens.
2. Prompt: "Act as an orchestrator. Use parallel agents to do the research and execution work. Write detailed tasks for each parallel agent and force them to act, iterate, get their tasks done, and bring back an in-depth report. Your job is to deeply analyze the agents' work, provide feedback, and provide them with continuous tasks."
This prompt offloads the majority of the context-burning work to agents, and each agent has its own context window. So you can utilize 5 agents (5 context windows).
3. Add this hard rule: "Measure twice, cut once policy."
Debugging and patching is messy work. Force Codex to plan first, act after (don't use plan mode; it's just overcomplicated). Ask it to make a task list for every task so it can track progress and iterate better.
4. Add this hard rule: "Keep the codebase clean, no tmp files, no dead code, no dead files. Stay organized all the time. No unnecessary folders, subfolders, or files."
Claude keeps most of its working files in cache as temporary files (which is bloatware, but it keeps the codebase neat), but Codex is output-heavy. It creates tons of folders and files, and your workspace can become a mess after a few sessions. As a result, this contaminates the context window and degrades performance. Force Codex to stay organized and follow the file structure.
These 4 techniques can help you save 40% context every session, and performance will be a lot better.
For planning, use Codex 5.5 (extra high), and after the plan is done, shift to Codex 5.5 (high) with fast mode. This works faster.
Codex 5.5 hack:
"Are you 100% confident in this strategy? If not, find all possible loopholes, suggest proper fixes and run this loop until you are factually 100% confident in the new startegy"
This works like charm. It makes Codex 5.5 high perform even better than codex 5.5 extra high.
Why? Codex 5.5 is the only model i noticed that is self aware. It never makes high claims unless the model verifies everything.
This doesn't work with Opus 4.7 cuz that's a very insecure model. You can paste this prompt over and over again, the model keeps saying "you're absolutely right,....."
But with codex, after 2-3 iterations you'll notice yourself it actually patched all loopholes and this genuinely sounds like a good strategy.
Try this out, thanks me later.
Just pulled a COMMON KENJI badge from registering the waitlist for One Arena @Rosentica!
Can't wait to battle and win more grails with my RWA cards!
See you in the Arena ⚜️
#OneArena#Rosentica
https://t.co/10EzYWZcx8
꧁⊹ WAITLIST OPEN ⊹꧂
Bring Your RWA Cards to Battle.
Compete for the Grails.
Collect, Social, Yield.
Test your luck, summon your own hero to join the waitlist:
— https://t.co/xFzgWKcuZl —
*Waitlist and Hero Summon are spot limited on a FCFS basis.
See you in the Arena ⚜️
@TabinekoKIKI@Freya_Starfall Hi Nat, just want to confirm the conversion formula.
Is the amount of $ONEP received calculated based on:
allocated pool % × (holdings/total supply)
Is the final conversion amount determined by my share of that token’s total supply, rather than by token price afterward?
Crazy attention on ONE PIECE and it will only grow stronger. Final arc begins from April.
Both $ONE benefit from the attention, one of them has actual IP & royalty inflow & strategic reserve to inject value from ONE PIECE to the token, and the other one is a one-time “news hype” meme.
Quite easy for me to choose which one to invest in to benefit from the ONE PIECE momentum in 2026:
EybU41yD9sAvECDuRuRiDKssf5qBFHzeQgaNWE4rbonk
I mean I don’t see a world where the other one with a icon from the news won’t be trumped by other crazy ONE PIEVE news shortly, and we all know that there’s a lot of them crazy big news coming.