GLM 5.2 post-training code is OPEN SOURCE (slime)
Megatron-LM trains. SGLang generates the rollouts. A single data buffer ties them into one continuous RL loop, with weights synced back every step.
My technical writeup below.
"Mathematics of Neural Networks" is an excellent set of lecture notes for anyone who wants to study modern neural networks from a mathematical perspective.
It covers supervised learning, artificial neurons and activation functions (ReLU, sigmoid, tanh, swish, softmax), shallow and deep neural networks, stochastic gradient descent, weight initialization, vanishing and exploding gradients, convolutional neural networks, automatic differentiation, backpropagation, adaptive optimization algorithms (Adagrad, RMSProp, Adam), and concludes with modern geometric concepts such as manifolds, Lie groups, equivariance, group convolutions, and rotation-translation equivariant CNNs.
I recommend keeping it in your bookmarks as a useful reference whenever you need to explore the mathematics behind neural networks.
https://t.co/78VDWxjDUa
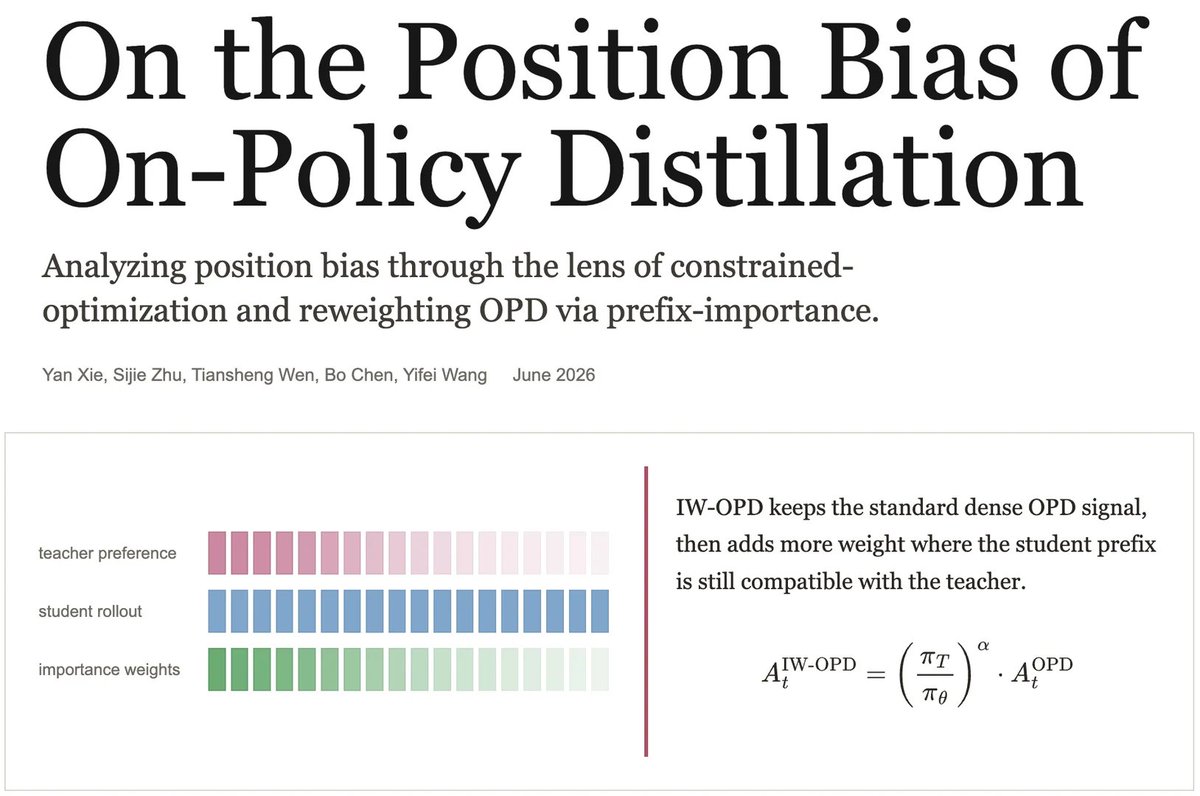
A nice theoretical revisit of OPD.
With the same supervision budget, supervising only the first 30% of tokens nearly matches standard OPD, while supervising only the last 30% barely works.
Framing OPD as a constrained optimization problem naturally leads to an importance-weighted objective, resulting in IW-OPD, which improves sample efficiency and performance with no extra inference cost.
Paper: https://t.co/ABztcquS6a
Blog: https://t.co/zuIu9sVIoH
A Stanford team just published the 16-page PDF on “How to structure an AI agent”
Structure matters more than how you prompt it, and it's backed by hard numbers.
Build → Reflect → Curate → Reuse
• Build: the agent starts with a structured context, not a clever one-off prompt.
• Reflect: it watches what actually worked during execution, no labels needed.
• Curate: it folds those wins into an evolving playbook instead of a static prompt.
• Reuse: the next run starts from that refined structure, getting stronger each time.
This is exactly why senior engineers build the structure first in Claude Code, then let the agent run.
Read the paper, then grab the setup below 👇
📑 스탠포드 대학교의 CS336: Language Modeling from Scratch
정보는 웹 어딘가에 모두 널려있어요. 이걸 아느냐 쓰느냐 마느냐는 본인의 선택이죠.
그 시작이 여깁니다. 전체강의.. 그리고 과제 자료.
https://t.co/PQ21GbY6oX
https://t.co/r5XrCHCcnN
데이터 수집부터 토크나이저 구현, 모델 아키텍처 설계, 대규모 분산 학습, 정렬까지 모든 과정을 학생들도 직접 구현하도록 설계된 매우 인텐시브한 강의입니다.
인공지능, 거대 언어 모델의 핵심을 밑바닥부터 파고들 수 있도록 설계된 프로젝트!!
그 수준이 정말 뛰어나다는데에 동의합니다.
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD
LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
tensor algebra is not abstract math.
it is the grammar of modern intelligence.
a scalar is one number.
a vector is a line of numbers.
a matrix is a grid of numbers.
a tensor is the general form: numbers arranged across multiple dimensions.
images are tensors.
videos are tensors.
robot sensor streams are tensors.
neural network weights are tensors.
physics simulations are tensors.
deep learning is basically tensor algebra + optimization + compute.
once you understand tensors, AI stops looking like magic.
it becomes structure.
reality → numbers → geometry → transformations → intelligence.
IN 1986 MIT FILMED A LECTURE THAT OPENS BY TELLING YOU COMPUTER SCIENCE IS NOT A SCIENCE AND HAS ALMOST NOTHING TO DO WITH COMPUTERS
72 minutes from Hal Abelson and Gerald Sussman, the lecture an entire generation of engineers calls the one that rewired how they think.
-> The line that lands: computer science is about computers the way astronomy is about telescopes. The tool was never the point.
The real subject was always one thing -- controlling complexity. Everything else is detail.
Forty years later it reads like a prophecy. AI writes the syntax now. What's left is exactly what they taught: taming complexity nobody can hold in their head.
The language was never the skill -> the thinking was. This is where you learn it.
Most people chase the newest framework. The ones who watched this think on a level frameworks can't touch.
Bookmark & Watch today it, this one's a legend ↓