🚨 SCOOP:
As previously reported, OpenAI plan to launch GPT-5.6 once back in office next week, with a target window of July 7-9, but want it out as early as possible within that window (so July 7th is the most likely date). This is also perfect timing to catch customers coming from Claude who have just lost their access to Fable 5 in plans, and I'm told the 5.6 plan limits will be significantly more generous. More aggressive safeguards are already being rolled out in preparation for the launch too, although they probably won't be as aggressive as Fable's.
DeepMind have also tentatively set a new launch date for Gemini 3.5 Pro of July 17th. Apparently, this extra time has been spent on a new pretrain (they were planning to keep using the ancient 2.5 Pro base, lol), but it remains to be seen whether it's any good. I'm not hopeful. In other news, work is well underway on a new Nano Banana Pro model based on the new 3.5 Pro base, which I expect to be better received and compete well with GPT-Image 1.
Africa's largest crypto exchange will power their core perps offering directly using Hyperliquid's onchain liquidity. This is a major milestone that will redefine how the next generation of financial applications are built.
The breakthrough of cloud computing was that any startup could quickly test their idea, with the comfort that the infrastructure would scale with their business. As the most liquid global venue for assets such as BTC, Hyperliquid will play the same role in the global economy. By tapping into the deepest onchain liquidity, builders can instead focus on their product and users.
Huge congratulations to the VALR team. We are honored that they chose to build on Hyperliquid. Excited to scale together!
Most projects should have equity or tokens, not both.
It's not that equity and tokens *can't* work. In theory, both can accrue value in the same system provided each conveys real ownership over valuable property.
But in practice, equity and tokens usually *don't* work, for a number of reasons that make single asset models better in most cases:
(1) Misaligned incentives. Companies with shareholders have a fiduciary duty to drive value to equity, not tokens. Holding tokens on a balance sheet doesn't solve this problem on its own, because there will always be some difference between the best interests of shareholders versus tokenholders. For example, a profit-generating business will nearly always return more value to shareholders by retaining that profit rather than socializing it across all tokenholders. There may be ways to wiggle out of the legal obligation here, but no way to avoid the misalignment itself. Over time, its impact typically grows rather than shrinks.
(2) Ambiguous value accrual. Companies with dual assets have to figure out what value should accrue to each one. Historically, most companies have struggled to design tokens that capture real value onchain, instead relying on theory (e.g., demand for utility tokens) or hand-waving to assert an investment thesis that rarely plays out well. Meanwhile, companies that generate value *offchain* have largely been blocked by legal from returning it to tokenholders, and so instead they return it to shareholders. The solution is to build fully onchain products where tokenholders have true ownership over infrastructure and revenue, but few projects have achieved that goal so far.
(3) Legal and governance issues. Beyond their affect on value, misalignment and ambiguity impose high operational costs. They are a potent combination for destroying any project, let alone one trying to build in an environment of regulatory uncertainty like we still face in crypto. Even if a well-designed dual asset model can work, the distraction and inefficiency required by the balancing act tend to make it *worse* than a single asset model, all else being equal.
So, can equity and tokens work together? Yes, if it's absolutely clear that offchain value accrues to equity, onchain value accrues to tokens, there's enough value to make both assets attractive, and neither one siphons or undermines the value of the other. There's a place for this, such as when a company's offchain business is positive sum (e.g., increasing token value by driving more activity to a protocol), or where the token performs a necessary function (e.g., incentivizing permissionless coordination).
Those cases are few and far between. Real enough to take seriously, but rare enough to treat with skepticism. Tl;dr, for almost everyone: tokens or equity, pick one.
When Robinhood launches perps for all these 0 day options traders in the US it’s going to be like showing that uncontacted tribe in the Amazon that they can watch porn on their phone now
This guy is a scammer who took over a hacked account & dms ppl with investment deals
It's an old scam, just block @pdxeth
Unfortunately have bunch of mutuals still following them
The President of the United States personally extracted $1.1B across WLFI and his memecoins (not including what his friends and family made) while delivering nothing and giving people false expectations.
He never cared one bit about crypto. Everything he promised and did was solely to enrich himself, and it worked.
This is the reason we’re where we are today. Crypto has become a place where you can milk the shit out of people and get away with it, no matter how much crime you commit.
Longpost about the biggest misconception I see people having by FAR on LLMs right now.
Know the difference between the harness, the model, and serving inference.
Vast majority of problems I see people having right now are due to the harness. Each provider has it's own unique thing that's wrong with it. Claude is unique like the state of California in that it taxes/is bad at everything.
Harness: This is the traditional software that calls the model api from the provider. This is what you install on your computer or the website you visit to access the LLM.
Common harnesses:
- Claude Code
- Codex
- Droid
- Pi
- OpenCode
- OMP ❤️
- Antigravity
- Copilot
- https://t.co/CfYrRYJlyx, https://t.co/P87Pigjt4m, or https://t.co/opgE1H0qlh in a web browser could technically be considered a harness
Harnesses are most people's bottleneck because things like tool calls, system prompts, mcp servers, skills, subagents, change the way the api is called and its actually used for gathering information and your day to day work dramatically. Claude code or codex can use 8x the tokens in certain contexts when programming compared to pi or omp purely due to hashline editing and tool calls in the system prompt. Planning and subagent management also makes work significantly faster for larger tasks. Compaction in codex is so good the model needs 1/4 the context that claude or gemini does to achieve better results which allows them to serve more users simultaneously with available vram.
Model: This is the actual LLM. The weight values which were trained and deployed somewhere which you access from the harness on your machine via an api. This is what people are benchmarking and typically talking about when they post evals.
Common Models:
- Claude Opus 4.8
- GPT 5.5
- Gemini 3.5 Flash
- Deepseek V4 Pro
- Qwen 3.7 Max
- Kimi K2.6
- Composer 2.5
People run evals to determine model quality for different tasks. Most engineers are using them for agentic coding, where terminalbench is king, and swebench to a lesser extent currently. For academic research and "white collar work" (i've written about this gimmick previously) there are other evals people target.
Serving and Inference: This is the actual computer and infrastructure network the model is running and being served on remotely. This can vary wildly depending on the provider.
- Google and XAI are the only ones that own their full stack vertically right now. Google has vertically integrated all of their models to use in house TPUs rather than GPUs to run on their cloud network (GCP, which they also own) extremely reliably and quickly.
- OpenAI has secured deals with Microsoft and now AWS and others to have guaranteed compute capacity until 2030 or so and preplanned most of their capacity already. They have deals with nvidia and cerebras directly now for datacenter buildouts.
- Anthropic didn't buy nearly enough compute the last few years. Now they are desperately selling off equity and turning into corporate frankenstein to meet demand. They are currently splitting the inference they give you between: GPUs, TPUs, AWS, GCP, SpaceX, bunch of other random crap. This is completely unmanageable in any reasonable period of time given the current growth of the space.
Chinese models are open source. Most of the chinese infrastructure is completely jank and slow, but great news! There's places hosting it for you like firworks, GMI, and others on the latest blackwell gpus to run it at 5x the speed you get through the official chinese apis. Or you can host them yourself! The chinese models are also a fraction of the price because power and the older hardware they have is so cheap. DSV4 flash performs the same as sonnet for actual pennies, or you can pay the same prices as the western providers on fireworks or gmi to get something that absolutely flies like gemini does. Kimi charges PER TURN rather than per token so you get 14x the tokens weekly on their chinese sub that you would get on gpt pro for something at gpt 5.4 xhigh's intelligence level.
There are different techniques people use to serve the models more effectively as well to more customers:
- Quantization truncates the weight values in memory to use less vram at the expense of the model getting "dumber" which claude does during peak hours in some locations and local hosters often use to take advantage of weaker gpus for personal use
- Smaller models can perform better than larger ones on actual task evals in some cases or be trained or fine tuned to be more token efficient to use less compute while performing similarly from a user's perspective
- Things like MOE allow models like deepseek or qwen to get split across lots of smaller/cheaper gpus at once and split off smaller more specialized models for research and specialized use cases
- Specialized silicon like Google's TPUs, Trainium, Cerebras, Groq, allow the models to be hosted at much much higher speeds at higher cost due to the specialized silicon and software stack
- Newer generation gpus or gpus with higher memory bandwidth or blackwell hardware are the single largest determinant in how fast a model will run that you are hosting followed by custom kernels, serving configuration, parallelism etc. However everything revolves around the silicon. Nvidia is still king because of Cuda and blackwell gpus have minimum 2x the memory bandwidth of any other gpus on the market. TPUS are faster still but far more specialized and difficult to get/set up. AMD/Apple chips are significantly slower albeit cheaper in some cases.
Why all of this is important:
Many of the issues people experience with claude for example, or reasons you see wildly different experiences from two people using the same model are ACTUALLY because of issues with the harness or serving. Some examples
- Opus 4.8 works okay on bedrock in opencode at 2am BUT Opus 4.8 on a $20/mo sub during peak business hours served at fp8 quant god knows where on medium thinking in claude code Is completely useless.
- Gemini 3.5 Flash or 3.1 Pro feels completely useless in gemini cli and gets stuck in loops constantly BUT in OMP it's as good as 5.5 is at 10 times the speed
- Qwen 3.6 27b locally feels awful in opencode on a macbook or dgx but absolutely flies at 10x the speed with no tool calls or thinking in pi with nvfp4 and MTP on a 5090 using raw bash and web search.
Why gpt is so uniquely good at the above:
Even if it's slow during the day from the massive userbase, it's the only one that just fucking works 24/7. It's not the fastest or the prettiest, but it's the most reliable and consistent out of the box with the least setup by far.
Why claude is so uniquely bad at the above:
The default harness is bad, the user experience is flashy, but it's the most expensive by far, you get wildly different quantizations, speeds, and answer quality depending where it's being hosted, and they have one nine of uptime https://t.co/WaiXeAQreA. This is largely due to organizational issues at the company which will *never* be resolved due to the cap table being so split now and internal politics.
Be extremely wary when someone says "I'm using claude" "I'm using deepseek" "I'm using gemini" two different people could be having wildly different results depending on what harness they're using, what model, thinking, and where it's being served at what time of day.
To summarize:
GPT - Slow Harness - Great model - Great Infra
Google - Shit Harness - Great model - UNMATCHED infra
Anthropic - Shit Harness - Okay model - Shit Infra - Great marketing and sales team
(hence California Income/Property/Sales tax analogy)
Chinese models - It's like linux, here's the parts, build it yourself! or use the hosts in china for dirt cheap or expensive western hosts for extremely fast infra
You can use ANY harness you want with ANY provider if you're willing to set it up
Saylor smashed equity ATM hard last week ($1.15bn raised).
Enterprise mNAV down to <1x.
Vocally committed to dividend warchest (again), but now further pushing premise of selling BTC to bid STRC/MSTR.
Only BTC left to sell for now - MSTR equity ATM fully tapped out.
Built my custom futures liq tape for us to use to monitor some liq tapes. Past older ones don’t seem to be maintained and lag. Also none that do it based on the sizes/venues that I want
Current setup for alerts:
• BTC/ETH liquidation threshold ≥ 200k
• SOL/HYPE liq threshold ≥ 100k
• REST OF ALTS liquidation threshold ≥ 50k
• Binance, Bybit, Hyperliquid futures
https://t.co/lGEakid45U
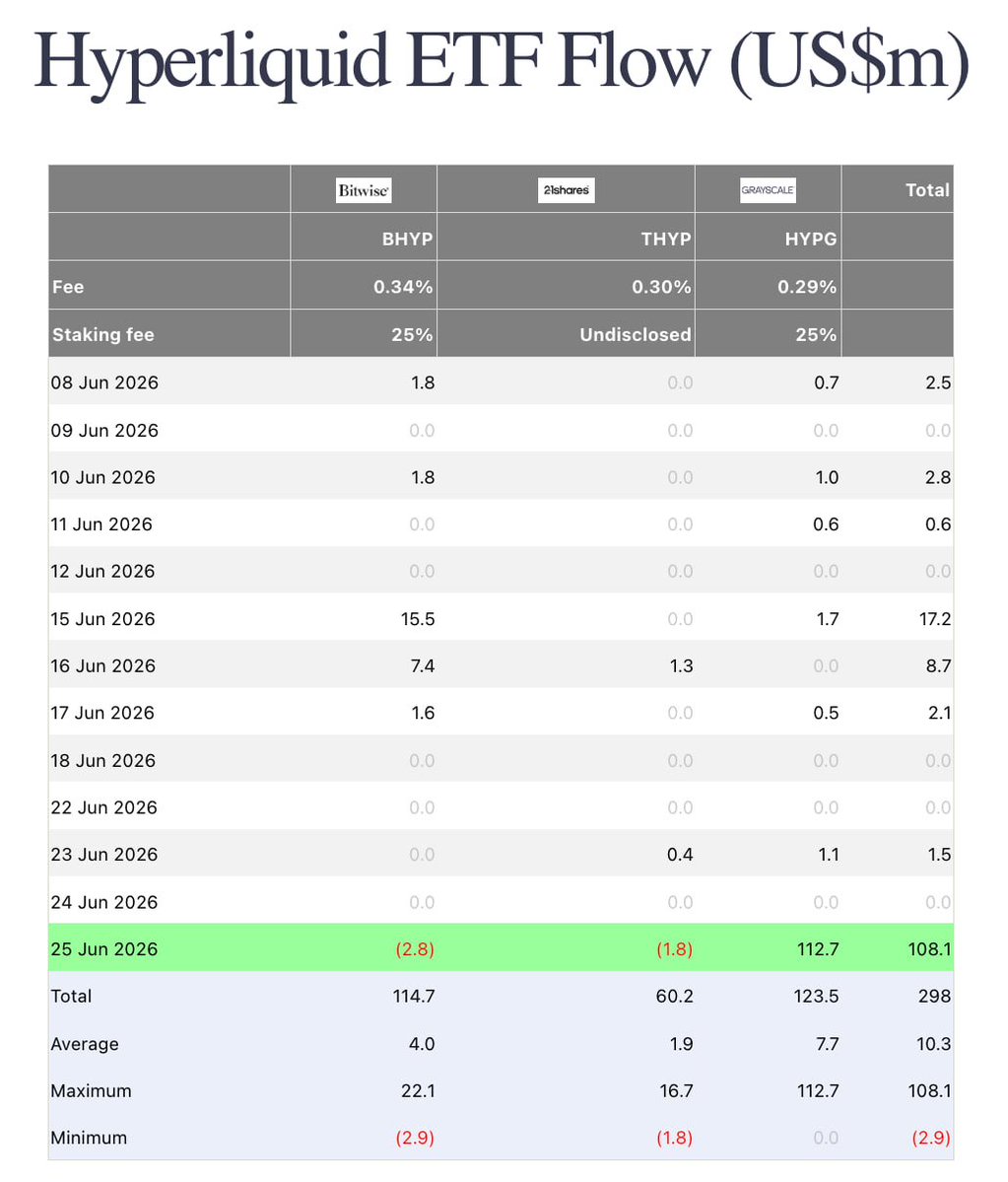
I am proud to publicly announce Hyper Holdings Global @HyperHoldings today. We are a consortium of investors, institutions and entrepreneurs with a mission to bridge the gap between legacy finance and the Hyperliquid ecosystem.
The first step towards this is in our strategic alignment with @Grayscale as they launch their Grayscale Hyperliquid Staking ETF $HYPG. For over a decade, Grayscale has been a pioneer of digital assets within the traditional financial system and has some of the deepest ties with US regulators and policymakers. They established the first publicly-quoted Bitcoin fund and secured the legal precedent that opened the door to spot crypto ETPs.
They have consistently used their positioning to protect and promote crypto, and now are helping shape policy and educate investors that will directly impact Hyperliquid's future.
$HYPG serves as an on ramp to bring serious, long term capital into the Hyperliquid ecosystem. This represents a historical moment in HYPE’s history and we are proud to be a part of this launch with Grayscale.
I want to thank every investor of this initiative and appreciate their patience and coordination as we worked to make this a success over the last several weeks. I am pleased to be joined by @multicoin, @hypurrdash, @MotusAk and other strategic individuals from around the world as we kick things off.
This is just the beginning. More to come soon.
Hyperliquid
5.5 is smart enough to cram everything into a single agents.md file with all your repos in a single workspace.
Containerize and break everything into microservices with TDD for everything with its own repo and pipeline. Put docs in html in their own repo and enforce it in HTML with hyperlinks so you can read them as well easily.
By splitting out the services more you can have agents recursively spawning subagents by devloop and splitting out work as effectively as needed on worktrees or patches in each repo. I use apfs/git worktrees are setup by default in omp for subagents. 5.5 is smart enough to know exactly how many subagents it needs and what depth the agent tree should go with recursion turned on.
You can refactor, rewrite, test, deploy your entire codebase with a single prompt. I'm currently managing a ~6m line codebase this way and self hosting everything. All infra code has its own repo for helm/csps. Metrics and tests on all services and grafana dashboards for tracking everything. Every stat I can possibly think of or ever will need gets shoved into postgres.
Any heavy data work or code that needs to be written gets metrics assigned to it in prom or pg and then gets targeted for /goal or for /autoresearch for optimization. I typically explore everything with gemini and have it write the prompts to hand off to 5.5.
People are simply not pushing the models hard enough. 5.4 and 5.5 (maybe even kimi and ds) ARE ASI. The bottleneck is yourself, compute, and devloop times.
Introducing a new, dedicated Image API, including typed dynamic capabilities.
Unified access to 30+ image gen models from 8 providers: Google, OpenAI, Black Forest Labs, Recraft, ByteDance, Sourceful, Microsoft, and xAI
Plus, a new solution to image API heterogeneity👇
One LangChain model object gives you access the whole @OpenRouter catalog for Deep Agents.
Route by throughput, latency, or price. Filter providers. Enforce ZDR/no data collection. Select fallback models.
When OpenRouter adds a provider or model, just pass the new slug.
https://t.co/PHPNDpP3xH