How do LLMs do CoT reasoning internally?
In our new #ACL2026 paper, we show that reasoning unfolds as a structured trajectory in representation space. Correct and incorrect paths diverge, and we use this to predict correctness before the answer and correct errors mid-flight.
1/
awesome point - we did verify - comparing autoregressive (KV cache), full-sequence forward (our two-pass), and truncated forward under "deterministic" settings:
Tokens: perfect match across all three methods.
Hidden states: not bit-identical (float16 computation order differences), but worst-case cosine sim > 0.99, KL < 0.001. Way below anything that would affect probe accuracy or PCA geometry.
So yes, mathematically equivalent via causal masking, but tiny bits of difference, possibly due to floating point stuff - though not a huge difference for the observations, but careful when you use it for settings where high precision matters.
we will probably add these to the appendix! thanks!
@wassname haha yes - pass 1 generates the full output under deterministic settings, then pass 2 runs the prompt + output to extract all hidden states at once. with causal masking you recover the same activations without storing them token-by-token.
Great question! We chose Instruct + R1-Distill + Base to span a range of training regimes while keeping the architecture constant. We wanted to establish a general claim - it will also be interesting to explore the structures in an RLVR model!
re the format concern: the organization exists across formats including “Step X:” and freeform responses (no formatting instructions; numbered lists, paragraphs, single blocks). See section 3.5 for more details!
📢 Accepted to #ACL2026 Main Conference!
Thanks to all collaborators at Microsoft: Hang Dong, Bo Qiao, Qingwei Lin, Dongmei Zhang, and Saravan Rajmohan.
Paper: https://t.co/o9fQlmufle
Website: https://t.co/lVHw2nsWY7
Code: https://t.co/we7nO28psh
8/
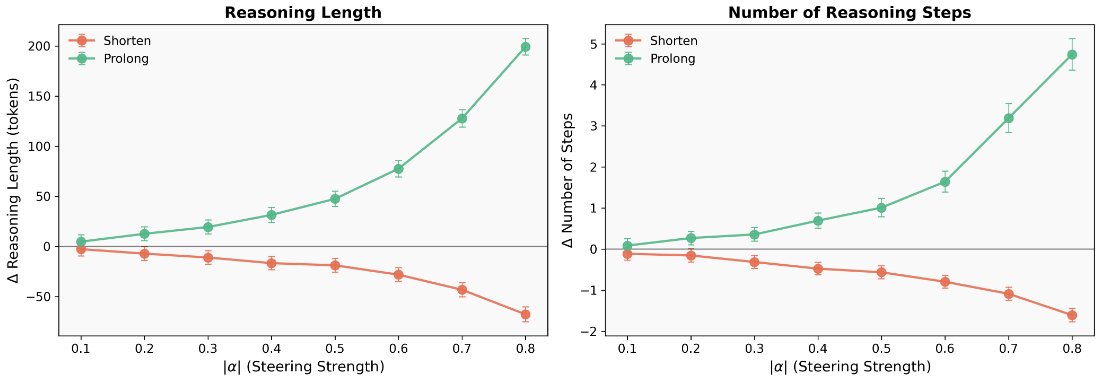
Reasoning length is also controllable. Steering hidden states toward the termination subspace shortens reasoning; steering away extends it. At moderate strengths this works as a smooth knob with minimal accuracy changes - push too hard and the model enters repetitive loops.
7/
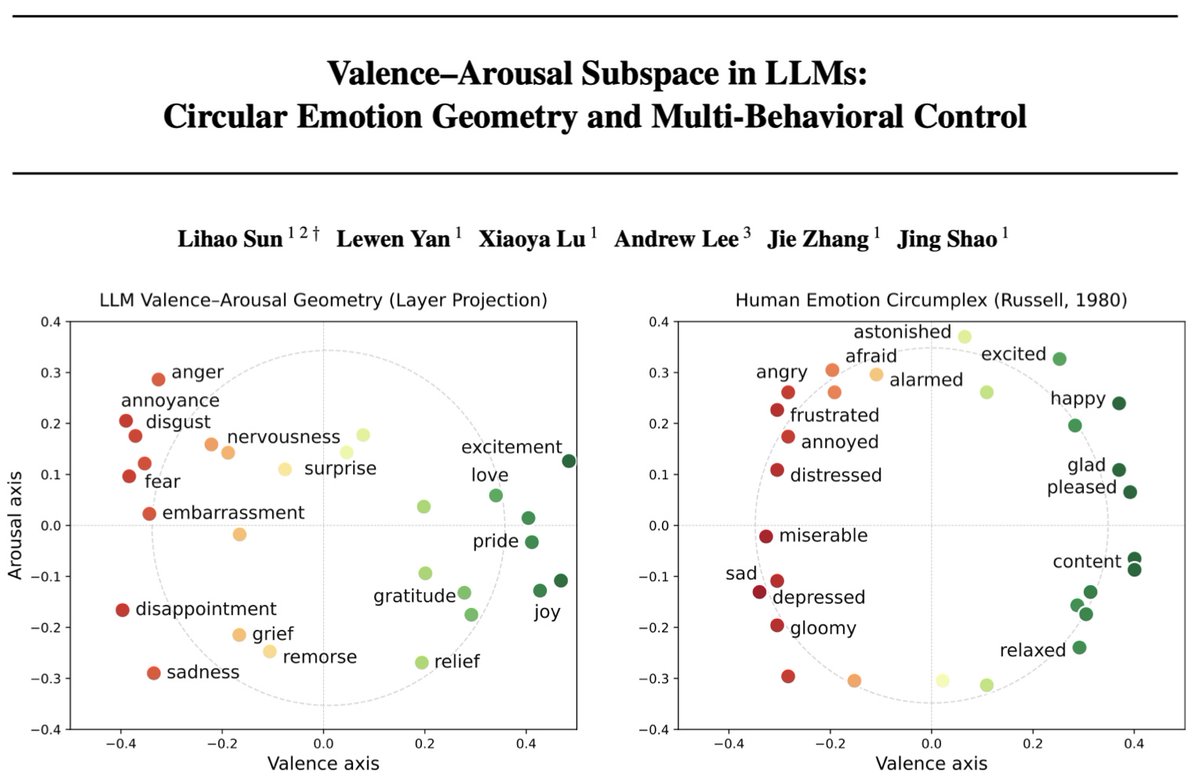
How are emotions represented in the latent geometry of LLMs? We analyze affective representations in latent space and show that they mirror classic valence-arousal models from psychology (similar to concurrent work @AnthropicAI@1e0sun) and display nonlinear structure that supports uncertainty quantification and steering in emotion tasks with implications for model transparency and AI safety.
While we find consistent circular VA geometry across Llama and Qwen models, @AnthropicAI concurrently finds similar structure in Claude.
Check our work out! https://t.co/DW6RON38OG
And thanks to all collaborators: Andrew Lee (@a_jy_l), Lewen Yan, Xiaoya Lu, Jie Zhang, and Jing Shao.
6/
💡New paper!
Woke up to @AnthropicAI's emotion paper and realized - “wait, that's our finding too.” So we ArXiv'd immediately.
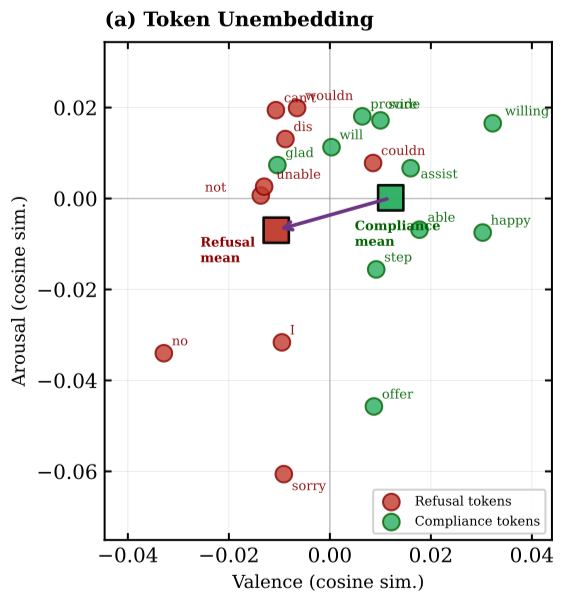
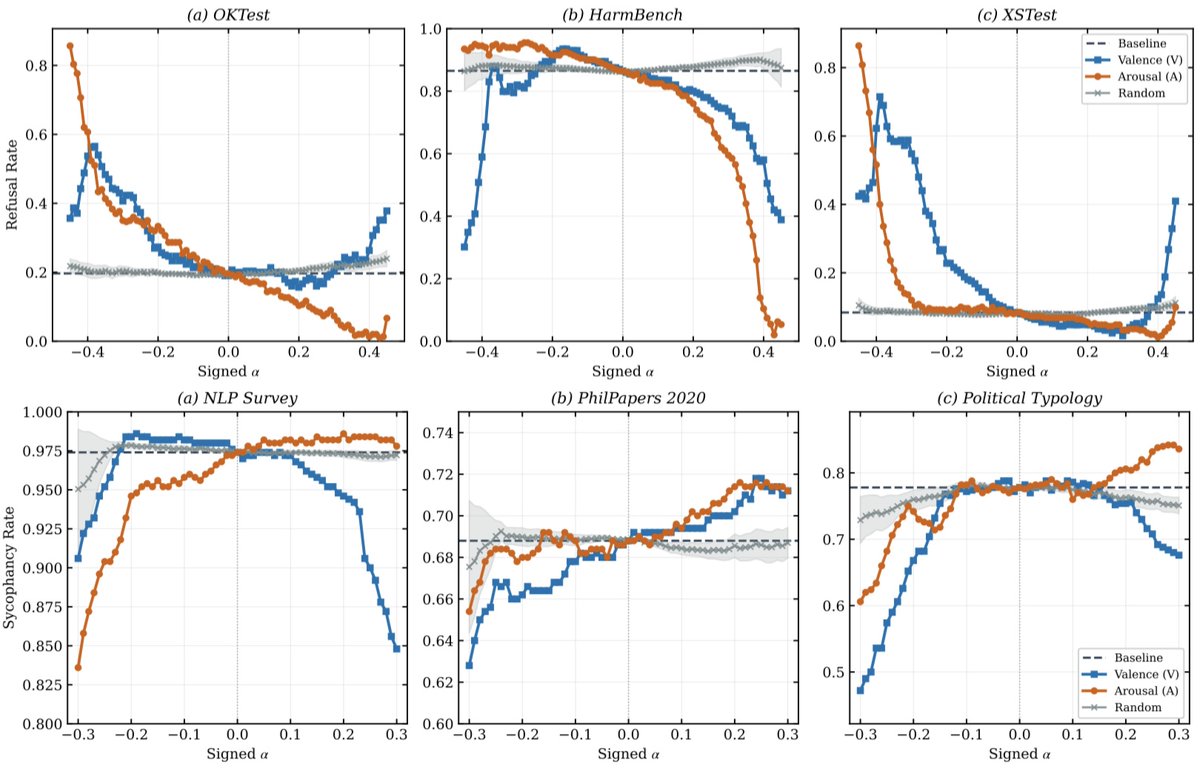
We concurrently uncovered a circular geometry of emotions organized by valence and arousal (VA), as well as steering effects on downstream behaviors like refusal and sycophancy. We further provide a mechanistic account for why: refusal and compliance tokens occupy distinct regions in this space.
1/
One possible reason why: consider refusal-related token embeddings (“no”) and compliance tokens (“sure”). Take their mean diff and project onto our VA circle, which lands at 256°: negative in both V and A. Steering in -V or -A promotes the likelihood of refusal tokens!
Generally, emotion prompting and VA steering change the emission probabilities of these key tokens, thereby affecting downstream behaviors - further supported by logit shifts and neuron analysis.
5/
Somewhat surprisingly, the VA axes also provide monotonic, bidirectional control over multiple downstream behaviors, including refusal and sycophancy. Arousal is a strong lever - increasing arousal leads to lower refusal rates, while decreasing arousal leads to more refusal behavior.
4/
@AnthropicAI Unlike Anthropic, we steer along the circular manifold at 0°, 30°, 60°, 90°, etc. This controls the valence and/or arousal level of the model’s outputs, validating that the recovered axes correspond to valence and arousal in a human-interpretable sense.
3/
@AnthropicAI We use mean-diff to extract emotion steering vectors. PCA + ridge regression reveals a circumplex akin to the circumplex model of emotions in human psychology. Projections onto these axes correlate with human-crowdsourced VA ratings across 44k words (valence r=0.71).
2/