la grande mode depuis quelques années c'est d'acheter du S&P500 pour se diversifier mais le top est ultra exposé à l'IA et est consanguin.
dans un contexte où les entreprises du retail (starbucks, pizza hut) annulent leurs projets IA car complètement foireux, et où des modèles chinois open weight talonnent de près les modèles "frontier" américains.
In my Harvard fellowship I study the views of AI accelerationists, safetyists and skeptics.
What I have come to realize is that both the Accelerationists and the Safetyists believe that we are creating an AI God.
The difference is that Accelerationists believe that it is the god of the New testament.
A god of loving kindness.
The Safetyists believe that it is the god of the Old testament.
The jealous one who told Abraham to kill his son, destroyed Sodom and Gomorrah, and killed everybody in the flood.
The Skeptics think it's just a damn toaster with more knobs.
@LuKg0v1 essaie pi, c'est pas une silverbullet mais j'ai obtenu de meilleurs résultats parfois (et surtout une meilleure utilisation du cache). et paradoxalement tente un coup ds4 flash, il passe parfois là où le pro ne passe pas (oui oui wtf).
DeepSeek just EMBARRASSED Claude Opus 4.7
Just switched to DeepSeek V4 Pro for a few days
Cost:
DeepSeek V4 Pro = $2.02
Claude Opus 4.7 = $265.21
Same quality for most of the medium tasks with no noticeable difference in output
I know it’s hosted in China with cheap electricity but at this point western labs are getting cooked on price
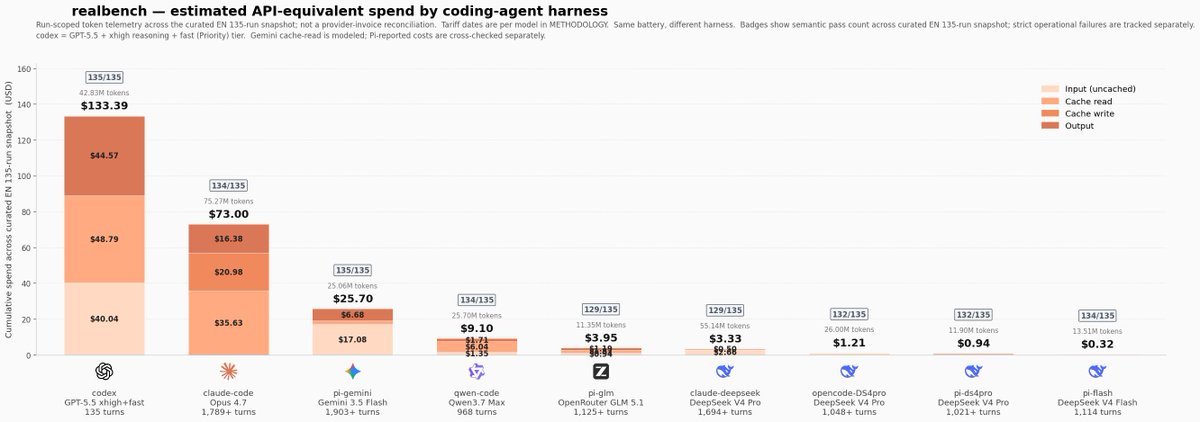
I got tired of abstract AI benchmarks that rank models in isolation.
Users don't run a model. They run a full loop: model + harness + tools + retries + cache + prompts.
So I ran 27 tasks that look like my real work across different coding-agent harnesses, 5 times each to reduce variance. I also wanted to create my own tasks to avoid the problem of benchmaxxing.
Result: near-identical pass rates, wildly different bills.
Codex/Claude costs are API-equivalent because I use subscriptions. But at public API prices, one Codex setup charts at ~420× the cost of Pi + DeepSeek V4 Flash for the same strict score.
The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot.
Don't trust my tasks. Run it on yours.
le harness est tellement la clé de voûte de tout qu'on voit que les mecs sont en train de reculer et essaient de le cacher de + en +: par exemple pour claude design, tout est hosté en ligne ce qui fait qu'on n'a pas accès au harness de manière visible comme c'est le cas pour claude code.
je suis persuadé qu'il y a moyen d'obtenir les mêmes résultats que claude design avec le bon prompt et le bon harness et les bonnes itérations en boucle. Ya "plus qu'à" reverse engineerer ça jusqu'à tomber sur les bonnes itérations.
en nous filant le CLI claude code sur nos ordinateurs, Anthropic a explosé mais s'est en même temps tiré une balle dans le pied sur le long terme. C'est littéralement le truc le plus important actuellement. De beaux jours s'annoncent pour les utilisateurs...
Le truc à retenir, c'est que le harness est encore plus important que le modèle. Avec des modèles qui ne coûtent virtuellement plus rien, alors la stratégie change totalement et ça devient rentable de spammer si le prompt et la logique de debug/de retry est bonne derrière.
i was schocked by the "135 turns" by codex too. but it's a different way of counting it, it will basically go through all the tasks and use multiple tools but will count 1 turn only.
I have no way to count the actual "turns" in the same fashion as the others. but codex was slow af (the larger the bar, the slower).
I got tired of abstract AI benchmarks that rank models in isolation.
Users don't run a model. They run a full loop: model + harness + tools + retries + cache + prompts.
So I ran 27 tasks that look like my real work across different coding-agent harnesses, 5 times each to reduce variance. I also wanted to create my own tasks to avoid the problem of benchmaxxing.
Result: near-identical pass rates, wildly different bills.
Codex/Claude costs are API-equivalent because I use subscriptions. But at public API prices, one Codex setup charts at ~420× the cost of Pi + DeepSeek V4 Flash for the same strict score.
The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot.
Don't trust my tasks. Run it on yours.