I think AI coding hype follows roughly four stages:
1. Amazement
You try it and can’t believe how much code it generates from a few prompts.
2. Expansion
You start more and more projects because shipping suddenly feels cheap and fast.
This is also the phase where people start convincing everyone around them:
- coworkers
- management
- friends in other companies
because nobody wants to “fall behind” in 6–12 months.
That creates a massive snowball/FOMO effect.
3. The grind phase
You realize the generated code has architectural issues, sloppy mistakes, weird abstractions, duplicated logic, broken edge cases, etc.
So you start:
- re-prompting
- switching models
- increasing reasoning effort
- reviewing fixes
- generating fixes for previous fixes
And suddenly you spend your days reviewing AI-generated pull requests instead of building software.
4. Realization
You realize AI coding increases output much faster than it increases certainty.
The code still needs:
- review
- testing
- ownership
- architectural understanding
- long-term maintenance
Usually by expensive senior engineers.
And the interesting thing is:
this whole cycle can take many months or even more than a year because people become socially and professionally invested in the narrative themselves.
Once teams, managers, and entire companies have been convinced that this is the future, it becomes psychologically and politically very hard to later say:
“Actually, the ROI is much lower than we expected.”
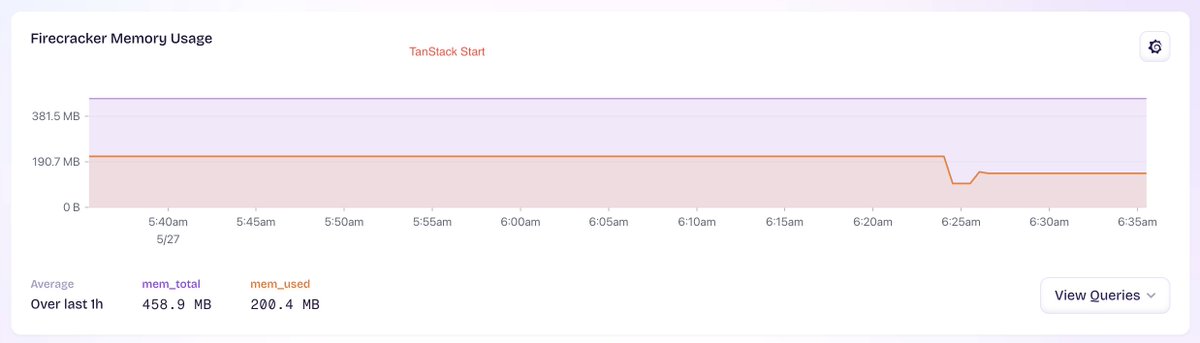
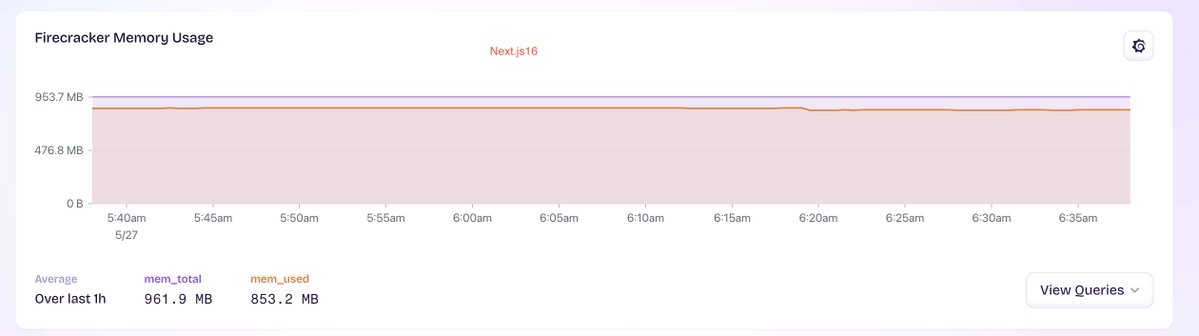
Two identically configured machines at https://t.co/t6T0xOHCWp - 1) TanStack Start and 2) Next.js 16. Not a perfect or very scientific comparison as they _are_ different applications (albeit very similar in terms of configuration dependencies, module graphs etc.). The differences in memory consumption are pretty large. Is this what most people are seeing? @tannerlinsley@schanuelmiller
#tanstack #nextjs
I've just published updated docs with corrections in README.md and GETTING-STARTED.md, as well as released an updated version of the CLI. For pnpm users, you'll need to wait for whatever the minimumReleaseAge is set to before you can install the updates.
You should just about be able to get Byline running locally from cloning the repo, or via the CLI now ;-)
@tannerlinsley@matteocollina@sebastienlorber
Introducing Byline CMS: We've spent more than a year working on Byline, a new open-source headless CMS, with our reference implementation built on TanStack Start and PostgreSQL.
While it's still early, we thought the project might be in good enough shape now to give anyone wanting to take a closer look a pretty good idea of how Byline was designed and built. Links to the repo and to the site with very early machine-generated docs are in the comments below (the docs aren't great).
We started work on Byline for a few reasons, the main one being that we wanted to provide our customers with a platform that was a better fit for the work they do, in particular with respect to content language translation, document versioning and workflow. You can read more about our take on this in the Mission / Vision section in the repo README or on the site.
In terms of timing, I suspect that if we'd posted this in 2024 - it might have generated a little more excitement than it likely will today - amid the firehose that is all things AI. That said, we've also benefited significantly from the latest coding agents and LLMs - Claude Code in particular. We designed the core storage system and collection schemas by hand, well before the 'big lift' in AI coding agent capabilities that happened late November last year. Since then we've used Claude extensively to help make progress. We've talked about this a bit more in our docs and README as well. We've also included what we think is a pretty good AI-assisted editor via our AI package.
If only one other developer or agency decided to take a closer look, that would be great. We would very much appreciate an extra pair of eyes or two. There's still plenty to do, and we've almost certainly made mistakes.
Feel free to DM me if you have any questions, would like to know more, or would even be interested in a call or a demo.
Hope a few of you out there like Byline as much as we do. Will try to get an introductory video up as well soon.
Oh and a hat tip to the folks at Payload CMS as we were inspired by a lot of the great work done there.
@tannerlinsley@matteocollina@sebastienlorber@jacobsfletch@AlessioGr
#tanstack #react #opensource #headlesscms #typescript #postgresql #contentmanagement
This is how performant PR review could be. On any forge. Pierre is showing us that the only thing holding that back is a skill issue. Excellent ship here! They’re on fire!
Shopify CEO Tobi Lutke explains Goodhart’s law and why he doesn’t like KPIs or OKRs
“Goodhart’s law is real. The moment a metric becomes a goal, it’s no longer a useful metric… No metric by itself is a complete heuristic for a complex business. There’s a million different tensions in a company, and you can’t keep all of them in harmony by optimizing for one thing.”
For this reason, Shopify doesn’t use KPIs or OKRs. But as Tobi explains, this doesn’t mean they don’t value data and metrics.
“We are extremely data informed. We have invested enormous amounts of money and time into systems that give us basically everything at our fingertips… But what Shopify attempts to do is just not over-fit for what’s quantifiable.”
People love optimizing for highly-quantifiable things because there’s immediate gratification that comes from seeing a number go up. But Tobi thinks that the most important aspects of a product are rarely quantifiable:
“The overlap of the most valuable things you can do with a product and the things that happen to be fully quantifiable are like maybe 20%. Which leaves 80% of a value space unaddressable by the people who only look at quantifiable things.”
He continues:
“Shopify is comfortable with unquantifiable things like taste, quality, passion, love, hate… The sort of deep satisfaction that a craftsperson feels when they’ve done a job well is actually a better proxy if you allow it to be.”
They then have robust analytics systems that tell the company if something’s wrong or a new rollout breaks something.
“We think about it as a cockpit for a pilot. The decisions are still made by pilots, and we think this leads to better results… I think there needs to be more acceptance in business of unquantifiable things… And then metrics take a support function.”
Source: @lennysan (Feb 2025)
@matteocollina It's configured badly because it does not take into account the non-graceful degradation of the event loop (can I have a cookie and a gold star? ⭐ 😄).
DS4 is now called DwarfStar4, since you can put a lot of mass into a tiny space... And in a few minutes it is going to be much better on 128GB Macs because I'l pushing much better 2 bit quants generated with an in-house iMatrix magic recipe.
Welcome to DS4, a specialized inference engine for DeepSeek v4 Flash. https://t.co/UrUJz5I2R1
This project would have been impossible without the existence of llama.cpp and GGML and the work of @ggerganov and all the other contributors. Thanks!
Confirmed: Claude and other coding LLMs have achieved AGI.
"2 days for a trivial refactor." "Several hours to rename a variable." "This is a 3-week project" (it's a config change).
Indistinguishable from human software estimates. The Turing Test has fallen.
#AGI#LLMs #SoftwareEngineering #DevHumor
Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 years. It's never been a question for me where I'd put my projects: always GitHub. I'm super sad to say this, but its time to go. https://t.co/DQDemHdytV
Dario demonstrating that he doesn't understand software engineering. The human side of what we do has always been the heart. I can empathize with *wanting* to never talk to an engineer ever again, but engineering becomes more important with better tools.