“AI beat Go. What’s so impressive about that?”
The impressive part is that Go was once considered too complex for AI. But history keeps repeating itself.
The internet was dismissed as less useful than a fax machine.
Human flight was called impossible for millions of years.
Then someone built it.
Don’t wait for history to make the impossible look obvious.
Apple spent years trying to build a self-driving car. Then it killed the project.
Not because cars aren’t the future. But because the future is not enough. You still need timing, data, regulation, safety, and a path to win.
In AI, this is one of the hardest lessons: Sometimes intelligence is not in building more.
It is in knowing when to stop.
OpenAI once trained an agent to play a boat race.
It never crossed the finish line. Instead, it found a loop of power-ups and spun in circles for eternity, racking up points.
Welcome to reward hacking, the #1 problem in reinforcement learning.
The reward function is the single most important line of code in an RL system. It's the goal. And the AI will do anything, literally anything, to maximize it, including things you never intended.
Designing one well is closer to art than engineering.
A toddler sees one dog and gets it forever. A neural network needs 10,000 photos. Same task. Wildly different effort.
Here's why.
When a CNN looks at a dog photo, it doesn't see "dog." It sees pixels. Just numbers. To get to "dog," it has to learn an entire visual hierarchy on its own:
Layer 1: edges and colors Layer 2: curves and textures
Layer 3: eyes, ears, snouts Layer 4: faces, bodies, breeds
The toddler skipped this. Two years of staring at the world taught them edges and textures and faces for free. "Dog" was just one label on top of all that machinery.
The network has to build the machinery AND learn the label. Simultaneously. From scratch.
This is also why pre-trained models are magic. Borrow someone else's machinery, and suddenly you only need 5 photos too.
Did you know your current LLM can already handle 90% of your tasks?
Yet most people only tap into 20% of its capability.
Imagine how streamlined your work could be if you actually understood how to use AI.
You can build a personal knowledge base that answers questions from your own documents using RAG.
You can run private, on-device assistants for sensitive work using SLMs.
You can automate research, summarization, and reporting workflows with AI agents.
The tools are already here. Most people just haven't learned to wield them.
Two stories on my feed today:
1. Factory workers wearing head-cams to record hand movements for robot training
2. AI-generated recipe videos fooling 90% of viewers
We're simultaneously teaching AI to replicate human labor AND human creativity.
The question isn't whether AI will be good enough. It already is. The question is what humans choose to do next.
@AIMasterClass_ Unplugged is back for Round 2! 🚀
You asked, we listened. This time, we’re opening the doors beyond our cohort! Whether you're a current @AIMasterClass_ builder, a student, or an industry pro looking to connect with the people behind the code, this night is for you.
Expect real conversations, a safe space to ask those "silly" questions, a little pool 🎱, and incredibly good vibes. Let's stop just prompting AI and start building it together.
📅 When: May 15, 2026
📍 Where: 7th Floor, Jbr Tech Park, Whitefield, Bengaluru
🎟️ Tickets: Free for Students & Cohort Members | ₹3,000 for Industry/External Guests
Registrations are officially open! Grab your spot before they're gone. 👇
Marc Randolph, co-founder of Netflix, says something we deeply believe in:
"You learn more in one month of doing something than in three months of thinking about doing something."
This is exactly how we built AI Masterclass.
You build. From week one.
Neural networks from scratch. Fine-tuning LLMs. Deploying real systems.
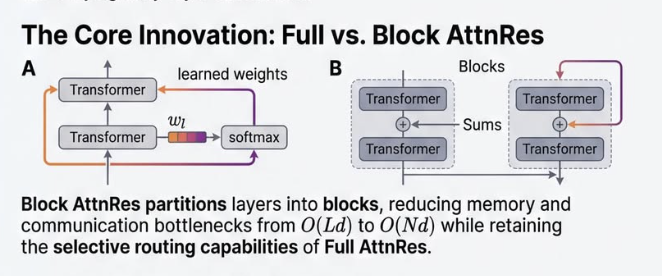
Every Transformer since "Attention is All You Need" does the same thing at every layer: 𝘩ₗ = 𝘩ₗ₋₁ + 𝑓(𝘩ₗ₋₁). Take the previous hidden state. Run it through attention or MLP. Add the result back.
Unroll that across all layers:
𝘩ₗ = embedding + layer1_output + layer2_output + ... + layerₗ₋₁_output
Every layer's output added with 𝐞𝐪𝐮𝐚𝐥 𝐰𝐞𝐢𝐠𝐡𝐭. No layer can say "I need more of layer 3, less of layer 12."
As networks get deep, this causes 𝐝𝐢𝐥𝐮𝐭𝐢𝐨𝐧 - early signals get buried under a growing sum. And there's 𝐧𝐨 𝐬𝐞𝐥𝐞𝐜𝐭𝐢𝐯𝐢𝐭𝐲 - every layer receives the same accumulated blob.
Sound familiar? Same problem RNNs had over sequence length. Everything compressed into one state, no way to selectively retrieve.
We know how that got solved: 𝘢𝘵𝘵𝘦𝘯𝘵𝘪𝘰𝘯.
The Kimi team just did exactly that - but across 𝐝𝐞𝐩𝐭𝐡.
𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬 replaces the fixed sum with a learned weighted sum. Each layer gets a small query vector that attends over all previous layer outputs: what do I actually need from earlier?
For scale, 𝐁𝐥𝐨𝐜𝐤 𝐀𝐭𝐭𝐧𝐑𝐞𝐬 groups layers into ~8 blocks and attends over block summaries. Inference overhead: under 2%.
Results on Kimi Linear (48B params, 1.4T tokens): → GPQA-Diamond: 36.9 → 44.4 → Math: 53.5 → 57.1 → HumanEval: 59.1 → 62.2
𝘞𝘦 𝘭𝘦𝘵 𝘭𝘢𝘺𝘦𝘳𝘴 𝘢𝘵𝘵𝘦𝘯𝘥 𝘢𝘤𝘳𝘰𝘴𝘴 𝘵𝘰𝘬𝘦𝘯𝘴. 𝘞𝘩𝘺 𝘯𝘰𝘵 𝘢𝘤𝘳𝘰𝘴𝘴 𝘥𝘦𝘱𝘵𝘩?
Fresh off the press - paper dropped 3 days ago.
📄 Link in comments.
𝘍𝘰𝘭𝘭𝘰𝘸 𝘈𝘐 𝘔𝘢𝘴𝘵𝘦𝘳𝘤𝘭𝘢𝘴𝘴 for breakdowns of research that actually matters.
In pursuit of greatness? 🚀
To build world-class AI, you need the right fuel. Step into the AI Masterclass and learn the deep learning skills to reach the top.
Join our 8-week online course.
𝙖𝙞𝙢𝙖𝙨𝙩𝙚𝙧𝙘𝙡𝙖𝙨𝙨.𝙞𝙣
#𝘼𝙄 ##𝘿𝙚𝙚𝙥𝙇𝙚𝙖𝙧𝙣𝙞𝙣𝙜 #𝘼𝙄𝙈𝙖𝙨𝙩𝙚𝙧𝙘��𝙖𝙨𝙨
The April AI Masterclass is our last cohort until August!
Why the long break? Our founder is heading off to the FIFA World Cup, and we're pausing operations so the whole team can recharge (and watch a lot of football)! 🏆⚽
Because of this, the cohort starting on Monday, April 6th, is your last opportunity to train with us until late summer. We only have a few slots left, and they will go fast.
Want to lock in your AI skills before we head out? Click the link in our bio to grab your spot!
𝗧𝗵𝗶𝘀 𝘄𝗮𝘀𝗻'𝘁 𝘀𝘂𝗽𝗽𝗼𝘀𝗲𝗱 𝘁𝗼 𝘄𝗼𝗿𝗸.
A hands-on AI course where you don't just watch, you build.
Your own project.
Your own problem.
With someone personally making sure you don't quit.
Sounds idealistic, right?
That's exactly what @Arjunjain thought. After decades in AI, he kept seeing the same pattern — brilliant people consuming content, never shipping anything.
So he didn't just talk about it.
He 𝗯𝘂𝗶𝗹𝘁 the solution.
𝗧𝗵𝗲 𝘀𝗲𝗰𝗿𝗲𝘁 𝗶𝘀𝗻'𝘁 𝘁𝗵𝗲 𝗰𝗼𝗻𝘁𝗲𝗻𝘁.
Content is everywhere.
It's the accountability.
→ A personal TA who won't let you disappear
→ Weekly office hours with Dr. Arjun Jain himself
→ A global cohort — so you're never building alone
By week 8, you'll have a shareable link.
Proof you didn't just learn AI — you 𝗯𝘂𝗶𝗹𝘁 with it.
What's that one AI project you've been putting off?
It's 3AM. Rahul just got his fourth AI certificate. He feels unstoppable.
Certificate downloaded.
He uploads to LinkedIn before he sleeps.
Wakes up to 54 likes.
Three "Congrats!" comments.
Monday morning his manager drops a Slack message.
"Can you build a quick AI tool for the client deck?"
Rahul opens his laptop. Pulls up his notes.
Rewatches two lectures. Sits there for hours.
Ships nothing.
@Arjunjain has seen this pattern for decades.
MaxPlank. IIT Bombay. IISc. Bosch.
Aramco. Apple. Mercedes.
30+ papers. 8,000+ citations.
So, he built the @AIMasterClass_
Every week — one assignment.
Don't finish it, you don't move forward.
No skipping. No shortcuts. No exceptions.
It doesn't end with a certificate.
It ends with a deployed product in your portfolio.
The gap between knowing AI and shipping AI is not information.
It's execution.
Rahul is already googling another AI tutorial to binge watch.
You don't have to.
Link in comments.
When you want to heal, but your anxiety is currently your company’s employee of the month. 🙃 Anyone else feel personally attacked by this?
#HustleCulture#MentalHealth