A robot dataset isn’t just a collection of trajectories.
It’s a collection of tasks.
Different tasks create different motion patterns, skill compositions, and behaviors.
That task structure is where much of the learning value comes from.
Axis doesn’t sell the same thing to every customer.
For model companies, it may be a task-grounded training dataset.
For hardware companies, it may be a full data → model → deployment workflow.
Different deliverables.
Same data engine.
NIh aku sharing buat yang penasaran gimana sih cara kontribusi atau grinding di project web3 yang fokus ke robotika atau Physical AI ✨👌
Disini aku kasi liat visual saat ngelakuin teleoperasi pake 3 project yang lagi aku serius jalanin :
🤖 @axisrobotics
🤖 @BitRobotNetwork
🤖 @ZenO4AI
Pada masing-masing project ini kita nnti akan diberi tugas yang harus diselesaikan, contohnya kyk taruh wortel dipiring, nyusun balok supaya sejajar, angkat balok dan sebagainya dari yang gampang smpe sulit 😭
Intinya kita cuma perlu nyelesaiin tugas sesuai perintahnya aja, awalnya pasti sulit aku juga ngerasain gitu 😭 tapi kalo kalian udh paham mekanismenya pasti bisa kok 👌
Tapi yang perlu kalian ketahui masing-masing project punya mekanisme dan kontrol yang berbeda jadi kalian harus bisa beradaptasi 😉
Semangat grindingnya ya kawan ✨🔥
Why does layout randomization matter?
Because robots shouldn’t memorize where objects are.
They should understand the task regardless of scene arrangement.
@axisrobotics is showing measurable gains from that approach.
The biggest AXIS gain wasn’t from a bigger model.
It came from better data diversity.
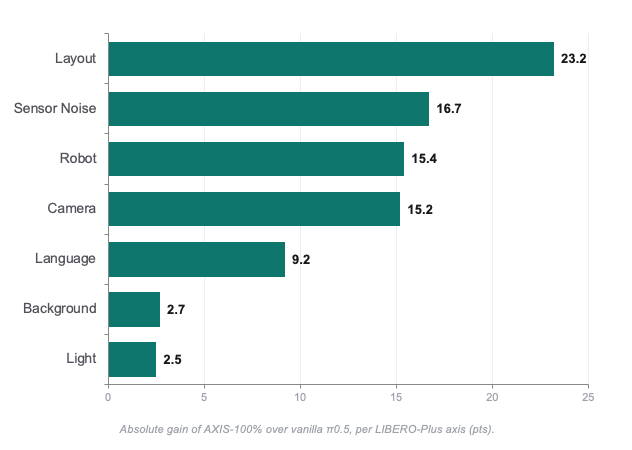
A +23.2 point improvement on Layout robustness suggests that structured scene variation can be just as important as model scaling.
The largest gain comes from Layout, the axis where structured scene diversity matters most.
LIBERO-Plus evaluates robustness across seven perturbation axes: Camera, Light, Sensor Noise, Background, Layout, Language, and Robot.
The largest absolute gain from AXIS-100% appears on Layout: +23.2 points over vanilla π0.5.
This directly validates one of the core AXIS data augmentation methods of layout randomization.
AXIS also improves more than visual robustness.
Beyond Layout, AXIS-100% also improves several other LIBERO-Plus axes. These axes measure different kinds of distribution shift.
The result shows that AXIS also improves robustness to viewpoint shifts, degraded visual observations, robot initial-state changes, and task wording variation.
Shoutout to all the amazing projects and communities we've collaborated with so far!
Take a look at our growing collab wall: https://t.co/SinJOGNSJf
Thank you for being part of the ZeroKids journey.
A useful reminder:
Robot intelligence isn't only about model size.
How you generate and randomize data matters.
AXIS-100% delivered its largest gain on Layout robustness, highlighting the value of structured scene diversity.
The largest gain comes from Layout, the axis where structured scene diversity matters most.
LIBERO-Plus evaluates robustness across seven perturbation axes: Camera, Light, Sensor Noise, Background, Layout, Language, and Robot.
The largest absolute gain from AXIS-100% appears on Layout: +23.2 points over vanilla π0.5.
This directly validates one of the core AXIS data augmentation methods of layout randomization.
AXIS also improves more than visual robustness.
Beyond Layout, AXIS-100% also improves several other LIBERO-Plus axes. These axes measure different kinds of distribution shift.
The result shows that AXIS also improves robustness to viewpoint shifts, degraded visual observations, robot initial-state changes, and task wording variation.
One of the strongest AXIS results:
The biggest improvement came from Layout robustness.
On LIBERO-Plus, AXIS-100% achieved a +23.2 point gain over vanilla π0.5 on the Layout axis.
More scene diversity.
Better generalization.
The largest gain comes from Layout, the axis where structured scene diversity matters most.
LIBERO-Plus evaluates robustness across seven perturbation axes: Camera, Light, Sensor Noise, Background, Layout, Language, and Robot.
The largest absolute gain from AXIS-100% appears on Layout: +23.2 points over vanilla π0.5.
This directly validates one of the core AXIS data augmentation methods of layout randomization.
AXIS also improves more than visual robustness.
Beyond Layout, AXIS-100% also improves several other LIBERO-Plus axes. These axes measure different kinds of distribution shift.
The result shows that AXIS also improves robustness to viewpoint shifts, degraded visual observations, robot initial-state changes, and task wording variation.
Physical AI is powered by people.
Axis and BitRobot are opening access to SN/04, giving contributors a chance to generate robotics training data and earn rewards across both ecosystems.
Train. Contribute. Climb the leaderboard. 🤖
@axisrobotics
Axis is turning robotics training into a repeatable service.
Task ID → train model → evaluate → generate heatmaps → deploy.
Less manual work.
More scalable experimentation.
@axisrobotics
One interesting result from Axis:
Recovery-driven training improved performance by ~10% over baseline.
The next question:
How much comes from more data vs better data?
That’s what the new failure-task experiments aim to answer.
Axis Weekly
This week was about making the AXIS loop more scalable end to end: automating data-to-model workflows, testing recovery-driven training, expanding TaskGen coverage, and preparing the dataset and model stack for release.
Key updates:
- Data-to-model automation: We used scripts to speed up and standardize several repetitive but critical workflows.
- Continuous-growth training: We completed multi-data-scale training and success-rate comparisons across several failure tasks.
- Failure task expansion: A new batch of failure tasks has been pushed to test, expanding the evaluation range for ablations across data scale, data quality, and randomization.
- TaskGen: Articulated-object generation is now merged into the automatic generation pipeline.
- Model and release prep: We finished the first round of fine-tuning, evaluation, and benchmarking, completed the dataset’s conference submission, and are now improving experimental results for release.
Details below 🧵