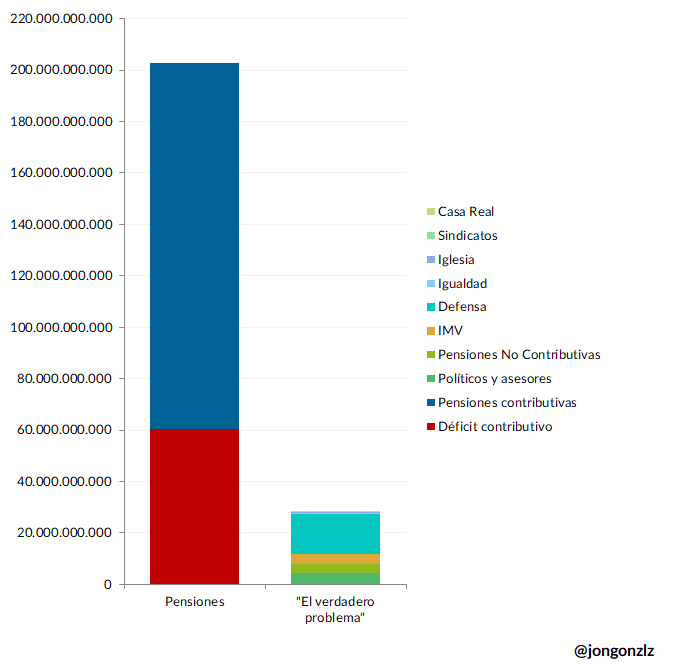
Prácticamente a la vez que @jongonzlz cierra la cuenta, tras haber reiterado que había un problema con la sostenibilidad de las pensiones, se hace público que España se ha gastado en pensiones unos fondos europeos que tenían que ir a otras cosas. Poético es poco.
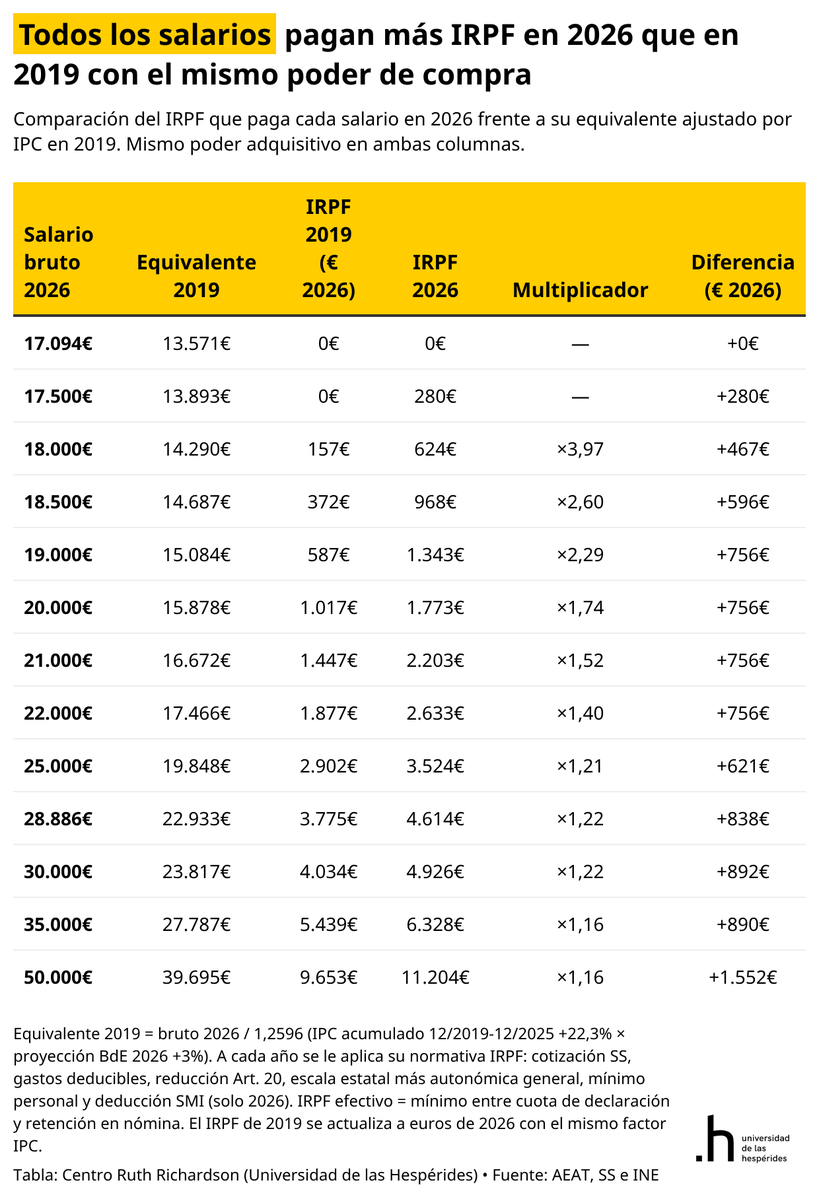
Conviene no olvidar que toda la campaña montada contra @jongonzlz empezó por decir exactamente esto: con el mismo poder adquisitivo, todos los salarios pagan más en 2026 que en 2019.
Y que las rentas bajas son las más castigadas: un sueldo de 18.000€ paga casi cuatro veces más que su equivalente real de hace siete años.
Esto es como el infame BOE de 2002 para las dietas en comisión de servicio, que lo único que hizo fue consolidar en euros las que había en pesetas de otra norma incluso anterior. Como nos descuidemos nos tenemos que ir de congreso y con las dietas te pagas el desayuno y gracias.
En 1993 un presidente de tribunal de oposiciones (profesorado de secundaria) cobraba 7636 pesetas (45,89 €) por jornada de oposición.
En 2026 un presidente de tribunal de oposiciones (profesorado de secundaria) cobra 45,89 € por jornada de oposición
#EscuelaPública
Ciencia deja sin cubrir 338 contratos predoctorales FPU desde 2022 pese a tenerlos presupuestados
Me estreno en Sociedad de @el_pais con este reportaje https://t.co/ELYoGc0ko8
Impressive how Orson Scott Card' experience with the editors' comments on his sci-fi works resonates with the average scientist' experience with the reviews of papers and projects.
You don't need advice from editors on rejected manuscripts.
My short story “Ender's Game” was rejected by Ben Bova at Analog back when that was the top market for a sci-fi story. Ben gave me feedback. He thought the title should be “Professional Soldier” and he said to “cut it in half.”
But I knew he was wrong on both points and submitted it to Jim Baen at Galaxy. He sat on it for a year, and responded to my query with a rejection. There was some kind of explanation, but I don't remember what it was. I concluded at the time that Baen's comments showed that he had barely glanced at the story.
So … I got feedback both times, but it was not helpful. I looked at Ben's rejection again. What was it about the story that made him think it should, let alone COULD, be cut in half?
Apparently it FELT long. What made it feel long? Now, post-Harry Potter, I would call it the quidditch problem. I had too many battles in which the details became tedious. So I cut two battles entirely, merely reporting the outcomes, and shortened another. In retyping the whole manuscript (pre-word-processor, that was the only way to get a clean manuscript), I added new point-of-view material to the point that I had cut only one page in length. So much for “in half.”
But I already knew that my manuscripts did not need cutting — if it wasn't needed, it wouldn't be there in the first place. Even the battles were still there, but instead of showing them, I merely told what happened (so much for the usually asinine advice “show don't tell”), which kept the pace going.
Those changes made, I sent it to Ben again. I did not remind him of what he had advised me to do. I merely told him I liked my title, and said, “I have addressed your other concerns,” which was true. I figured he wouldn't remember what his exact words had been. My answer was a check. That revised story was the basis for my winning the Campbell Award for best new writer.
Did Ben's feedback help? Yes — but his specific advice was not right, and I knew it. On my next two submissions, Ben hated my endings, and I revised as suggested. The fourth submission he rejected outright, and the fifth, and I thought, Am I a one-story writer? I went back to Ender's Game and tried to analyze why it worked. Then, deliberately imitating myself, I wrote “Mikal's Songbird.” Ben bought it, and it received favorable mentions. I was afraid then that I had consigned myself to writing stories about children in jeopardy. But in fact I was writing character stories rather than idea stories. And THAT was how I built a career, not by self-imitation, and not by following editorial suggestions.
I did get wise counsel from David Hartwell on my novel Wyrms, but that was on a book that was already under contract, and it was story feedback, not style. I got wise counsel from Beth Meacham, too, on various books over the years — but again, only on books that were under contract. I also received appallingly stupid advice from the editor of my novel Saints, which temporarily destroyed the book's marketability; after that, I was allowed to go back to my original structure and save the book — now it's one of my best.
Editors don't know more than you about your story. They especially don't know why they decide to accept or reject stories. YOU have to know what your story needs to be, and take only advice that you believe in.
Your best counselor on a story nobody bought is TIME. Let some time pass and then reread the story. Don't even think about why it Didn't Work. Instead, think about what DOES work, and then write it again, a complete rewrite, keeping nothing from the previous draft. Find the right protagonist and begin at the beginning — the point where the protagonist first gets involved with the events of the story. Be inventive — the failed first draft no longer exists, so you're not bound by any of your earlier decisions. THAT is how you resurrect a good idea you did not succeed with on your first try.
Excellent thread that explains why languages like C++ (I would also say Fortran, but that is rather personal) are still worth being learned nowadays, despite Python apparently dominating everything.
I was in class last week. One of my students raised their hand mid-lecture and asked something that stopped me for a second.
"Why is every AI tool built on Python? C++ is faster. Rust is faster. Even Java is faster. So why Python?"
Honestly it’s a fair question. And the answer reveals something really interesting about how the AI industry actually works.
Let me explain this properly. 🧵
Thread in Spanish, very interesting to see the dangers of using any AI agent as a fact-checker. PLEASE DON'T use AIs for that. AIs are brainless, stubborn and only excel in one thing: deceiving you into believing they actually know what they are doing.
Os cuento qué pasó ayer con una foto de la España de los 50, la reacción de tuiter ultraderecha, y la aparición "estelar" (más bien estrellada) de @grok.
Un hilo sobre los peligros de fiarse de la IA y no hacer comprobaciones.
Todo empieza con esta publicación de @kritikafull
GenAI isn't just a technology; it's an informational pollutant—a pervasive cognitive smog that touches and corrupts every aspect of the Internet. It's not just a productivity tool; it's a kind of digital acid rain, silently eroding the value of all information.
Every image is no longer a glimpse of reality, but a potential vector for synthetic deception. Every article is no longer a unique voice, but a soulless permutation of data, a hollow echo in the digital chamber. This isn't just content creation; it's the flattening of the entire vibrant ecosystem of human expression, transforming a rich tapestry of ideas into a uniform, gray slurry of derivative, algorithmically optimized outputs.
This isn't just innovation; it's the systematic contamination of our data streams, a semantic sludge that clogs the channels of genuine communication and cheapens the value of human thought—leaving us to sift through a digital landfill for a single original idea.
Today I have a few words about some well-known and maybe not-so well known problems with scientific research and what others have said about this.
https://t.co/Zuseq8ycfu
Internet brought us the "age of information", and irresponsible use of generative AI is bringing us the "age of bullshit". An ocean of fake/hallucinated bullshit flooding everywhere. A future where not a single text or document will be fully trustworthy.
@ribap Además, no imagino a muchos supervisores o tutores admitiendo que sus estudiantes hayan tenido problemas o necesitado ayuda psicológica. Y sobre los estudiantes, no me extrañaría que escondieran esos problemas por miedo a ser vistos como débiles o con poca capacidad de trabajo.
@ribap Siendo un punto importante, el problema que yo veo es que a día de hoy no parece fácil de evaluar. En primer lugar, recoger datos sobre cualquier aspecto de la salud del alumnado es muy delicado desde el punto de la privacidad.
Estimada @DianaMorantR, ¿por qué permite que su @CienciaGob y la @AgEInves hagan tan difícil las convocatorias de proyectos de Generación de Conocimiento 2024?
Me explico, ¿qué sentido tienen los equipos de investigación y trabajo dadas las limitaciones a la participación?
Sigo⬇
@francoisfleuret ... and then you see that even though the job died, Slurm still says "Running", and you have been accounted for zillions of cpu-hours.
@verdewek@deleg_USO_CSIC@DianaMorantR Y esto pasa también con programas de mucho más "pedigree" como las MSCA, que estás el primer año matándote hasta que el proyecto empieza a dar algún resultado decente y entonces tienes que dejarlo en segundo plano para estar el segundo año escribiendo otros proyectos como loco.
Parte del trabajo de un investigador (del @csic, de universidades) es viajar. A congresos, reuniones de trabajo, salidas al campo, etc. Sería razonable pensar que, cuando viajamos por trabajo, nuestro empleador cubre nuestros gastos. Pero no es así. Te lo explico. ->
The #NobelPrizeinPhysics2024 for Hopfield & Hinton rewards plagiarism and incorrect attribution in computer science. It's mostly about Amari's "Hopfield network" and the "Boltzmann Machine."
1. The Lenz-Ising recurrent architecture with neuron-like elements was published in 1925 [L20][I24][I25]. In 1972, Shun-Ichi Amari made it adaptive such that it could learn to associate input patterns with output patterns by changing its connection weights [AMH1]. However, Amari is only briefly cited in the "Scientific Background to the Nobel Prize in Physics 2024." Unfortunately, Amari's net was later called the "Hopfield network." Hopfield republished it 10 years later [AMH2], without citing Amari, not even in later papers.
2. The related Boltzmann Machine paper by Ackley, Hinton, and Sejnowski (1985) [BM] was about learning internal representations in hidden units of neural networks (NNs) [S20]. It didn't cite the first working algorithm for deep learning of internal representations by Ivakhnenko & Lapa (Ukraine, 1965)[DEEP1-2][HIN]. It didn't cite Amari's separate work (1967-68)[GD1-2] on learning internal representations in deep NNs end-to-end through stochastic gradient descent (SGD). Not even the later surveys by the authors [S20][DL3][DLP] nor the "Scientific Background to the Nobel Prize in Physics 2024" mention these origins of deep learning. ([BM] also did not cite relevant prior work by Sherrington & Kirkpatrick [SK75] & Glauber [G63].)
3. The Nobel Committee also lauds Hinton et al.'s 2006 method for layer-wise pretraining of deep NNs (2006) [UN4]. However, this work neither cited the original layer-wise training of deep NNs by Ivakhnenko & Lapa (1965)[DEEP1-2] nor the original work on unsupervised pretraining of deep NNs (1991) [UN0-1][DLP].
4. The "Popular information" says: “At the end of the 1960s, some discouraging theoretical results caused many researchers to suspect that these neural networks would never be of any real use." However, deep learning research was obviously alive and kicking in the 1960s-70s, especially outside of the Anglosphere [DEEP1-2][GD1-3][CNN1][DL1-2][DLP][DLH].
5. Many additional cases of plagiarism and incorrect attribution can be found in the following reference [DLP], which also contains the other references above. One can start with Sec. 3:
[DLP] J. Schmidhuber (2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023. https://t.co/Nz0fjc6kyx
See also the following reference [DLH] for a history of the field:
[DLH] J. Schmidhuber (2022). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022. Preprint arXiv:2212.11279. https://t.co/Ys0dw5hkF4 (This extends the 2015 award-winning survey https://t.co/7goTtI5Uwv)