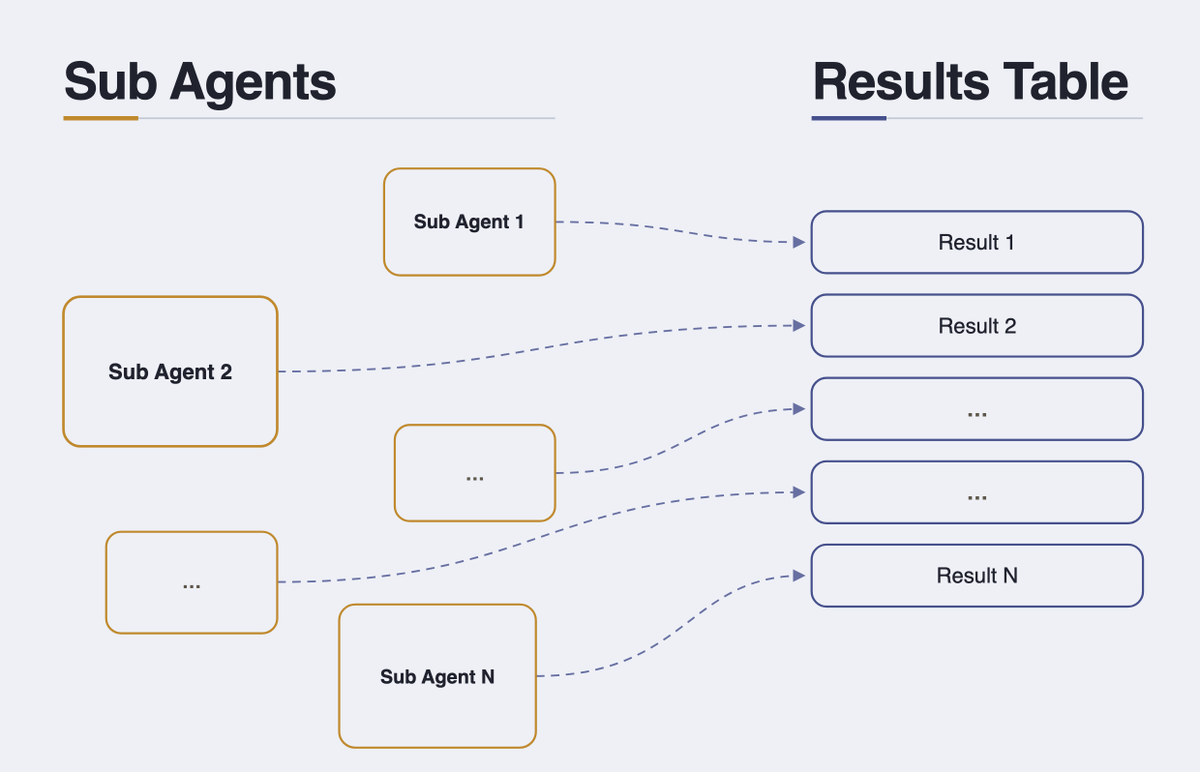
I'm bullish on agent swarms (aka workflows). Agents are increasingly being used to analyze and collate massive amounts of unstructured data in repetitive ways (e.g. document extraction, reading emails, parsing logs), but as these tasks and data inputs scale we've seen reliable execution decrease, even from the most capable models. Specifically, the consistency of sub agent dispatches from filesystem-based agents drops dramatically when attempting to deploy more than 30+ sub agents in parallel.
So… how can you harness the best of an agent's intelligent decision making with reliable sub agent task execution at scale? Here's how 👇 1/5
Finally, the output can be navigated and ingested by the orchestrating agent for any downstream follow up!
From testing and implementation, we've seen these techniques begin to deliver incredibly reliable sub agent execution at scale, where relying on a single LLM's function calling ability and logic would fail. It will be critical to watch how this evolves as more agent harnesses begin to rely on both code execution and recursive agent runs behind the scenes! 5/5
Once each individual sub agent completes its run, the results can either be joined back to the main table or acknowledged as completed. We can use structured outputs to do this join automatically via the same dispatch script as results stream in. 4/5
One personal gripe I have with current ai product advertising is that many displays/billboards seem strangely… verbose? Like lots of shoehorned text awkwardly worldbuilding niche scenarios to get their use case across
Am I just not the target audience? does this not seem counterintuitive to traditional brand/product marketing?
Trace data is literally worth its weight in gold these days, if you know what to do with it! As has been established, creating effective agents requires shipping early, observing behavior, and iterating quickly. At the core of this are your agent traces capturing exact inputs, outputs, steps, and metadata along the way.
Analyzing traces helps surface inefficiencies and areas for improvement, but they can also be used in more sophisticated ways to set up robust evaluations.
Here's two of the ways we use traces to build evals for production agents 👇
@novasarc01 Ah ok so this is testing whether the proposed eval actually catches the failure mode that it’s supposed to. Nice! Need to look deeper into user session coding traces- agreed with the earlier point that standard benchmarks rarely reflect actual user experience
@novasarc01 Interesting! So you also generate what could be called, for lack of better terms, a "synthetic ground truth" based on what should be expected/have happened/ideal state with the eval. What does rerunning the eval on that tell you? Or do you use as more a target/reference