We built a tamagotchi in office and it's the most wholesome thing we've made! 👀
@harshitajain561 wired one up with an ESP32-C3 SuperMini and powered the voice layer with Pule STT and it just doesn't hear us speaking, but also mirrors our mood and sketches whatever we ask it draw.
This is how Pulse STT performs in the wild 🐣
Pulse hits 3.2% word error rate on Coval's STT benchmark!
Coval is the eval platform built for voice AI agents. Their STT test uses diverse speakers, accents, and real-world conditions, not clean read speech.
Ahead of:
- Deepgram Nova-3 (4.2%)
- AssemblyAI Universal Streaming (4.2%)
- Speechmatics Enhanced (4.2%)
Check out the full docs in 🧵
A 3-point gap in aggregate WER can hide a 13-point gap on the audio that actually breaks production.
Heavy noise WER:
- Pulse 18.29%
- Assembly AI 25.61%
- Deepgram Nova 3 31.29%
Aggregate WER averages ten different noise conditions into a single number. The per-condition breakdown shows where a model actually breaks.
Pulse Pro is the #1 hosted STT API on the CodeSOTA leaderboard, and #3 overall across all models, hosted and open-source 👀
5.42% mean WER on the HF Open ASR Leaderboard's 8-dataset suite.
A hosted API matching open-source frontier accuracy is rare. Doing it while shipping on-prem and air-gapped deployment is the position that matters for enterprise.
Check out the full leaderboard 🧵
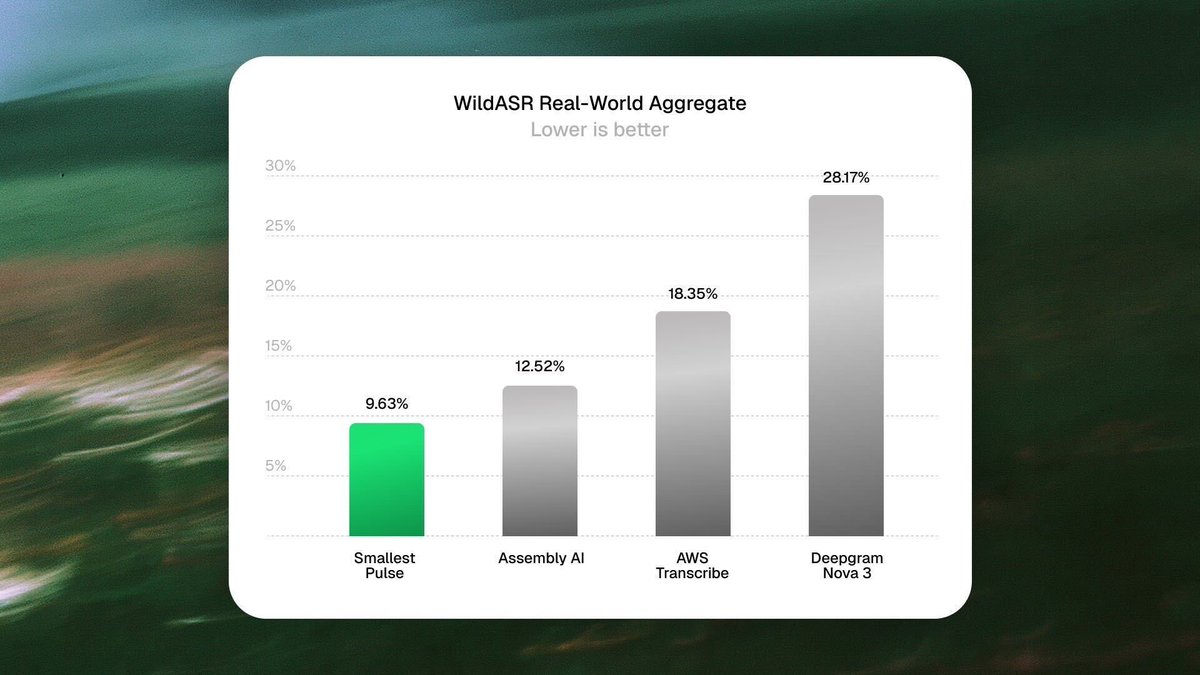
On WildASR, Pulse hits 9.63% word error rate. Deepgram Nova-3 hits 28.17%. Nearly 3x the WER, on the same audio.
WildASR is the benchmark that tests STT on real production conditions, not clean studio recordings. Their dataset covers far-field mics (sound captured from across a room: conference speakerphones, kiosks, drive-thrus), reverberation (echo in real rooms), phone codec compression, clipping, and background noise gaps.
These are the conditions voice agents and contact centers deal with every call. Clean datasets predict almost nothing about how a model behaves here.
Check out the full benchmarks in our Docs.
every business has a calling button that mostly never works.
so i built RingIt. powered by @smallest_AI .
→ pick your industry
→ 4 quick questions
→ voice agent in 3 minutes
→ tweak it by chatting
→ see everything on the dashboard
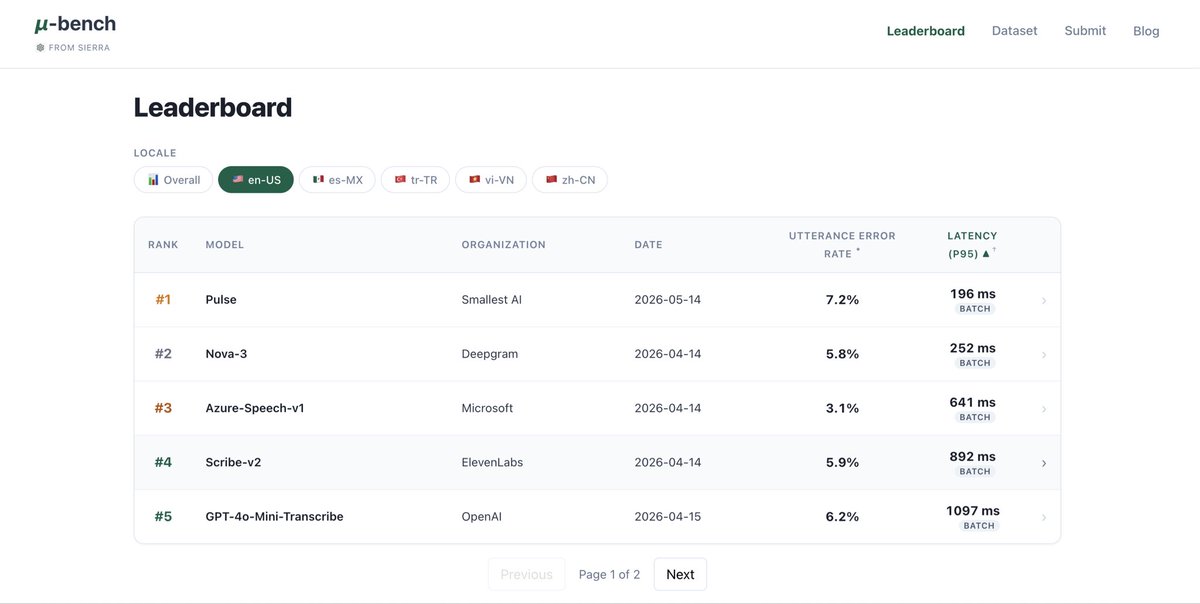
Pulse by Smallest AI is now #1 on @SierraPlatform’s μBench for P95 latency!
Real-time voice systems need speed that holds up consistently at scale. P95 is where the real user experience shows up.
Proud to see Pulse leading on the metric that makes conversations actually feel instantaneous.
Huge shoutout to Sierra for building and open-sourcing μBench.
4x cost reduction in TTS inference with @tenstorrent!
11 NVIDIA L40S ran 550 simultaneous audio-stream at ~$100K.
Now, 27 Tenstorrent P100 chips do the same at ~$27k.
First production-grade TTS to match the cost of text tokens without degradation in audio quality.
Hear it straight from the team that built it: @AkshatMandloi10 and @ranjith_m_s in the video below.
This effectively removes the biggest barrier, the unit economics, for organisations using voice AI at scale.
- Regulated Industries: BFSI, healthcare, telecommunications, that need data-sovereignty while working with voice AI, can now do so without making hardware costs impractical.
- Growth-stage cos: Teams that couldn’t justify the capital spend for voice infrastructure