Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
We’ve added a CLI for Claude Platform to make every API endpoint runnable from your terminal.
Call the Messages API, stand up Claude Managed Agents, pipe results straight into your shell.
The ant CLI is well understood by coding agents (Claude Code) using the claude-api skill.
RAG was never the end goal.
Memory in AI agents is where everything is heading. Let me break down this evolution.
RAG (2020 to 2023):
- Retrieve info once, generate response
- No decision making, just fetch and answer
- Problem: often retrieves irrelevant context
Agentic RAG:
- Agent decides if retrieval is needed
- Agent picks which source to query
- Agent validates if results are useful
- Problem: still read only, can’t learn from interactions
AI Memory:
- Read AND write to external knowledge
- Learns from past conversations
- Remembers user preferences, past context
- Enables true personalization
The mental model is simple:
↳ RAG: read only, one shot
↳ Agentic RAG: read only via tool calls
↳ Agent Memory: read write via tool calls
With memory, the agent can now remember things like user preferences, past conversations, and important dates. And all of it is stored and retrievable for future interactions.
This gives the agent a layer for continual learning, where instead of being frozen at all times, agent can accumulate knowledge from every interaction and improve over time without retraining.
This isn't simple because in practice, production systems need to think about memory corruption, decide what to forget, and manage multiple memory types like procedural, episodic, and semantic.
Graphiti (open source with 26k+ stars) already implements all of that if you want to build real time, temporally aware knowledge graphs that power self evolving AI memory.
Instead of recomputing the whole graph on every update, Graphiti ingests new info incrementally and tracks when each fact was true.
And when that info changes, the old facts are invalidated rather than deleted, so an agent can query what is true now and reconstruct what was true at any earlier point.
The core loop is two calls, one to write an episode into the graph and one to search across it:
𝗮𝘄𝗮𝗶𝘁 𝗴𝗿𝗮𝗽𝗵𝗶𝘁𝗶[.]𝗮𝗱𝗱_𝗲𝗽𝗶𝘀𝗼𝗱𝗲(…,)
𝗿𝗲𝘀𝘂𝗹𝘁 = 𝗮𝘄𝗮𝗶𝘁 𝗴𝗿𝗮𝗽𝗵𝗶𝘁𝗶[.]𝘀𝗲𝗮𝗿𝗰𝗵(“𝗬𝗼𝘂𝗿 𝗾𝘂𝗲𝗿𝘆 𝗵𝗲𝗿𝗲”)
After this, Graphiti handles entity extraction, relationship building, and temporal updates underneath.
Here's the GitHub Repo: https://t.co/aFsgR0kYb2
(don't forget to star it ⭐)
Note that there's one practical detail that decides whether this graph will be actually useful.
By default, the extraction model picks the entity types and relationship labels on its own.
This returns generic results, where everything collapses into a Topic or Object node connected by RELATES_TO edges that cannot be queried meaningfully.
Defining the schema yourself as Pydantic models makes the layer resilient.
My co-founder wrote a full breakdown on this, walking through why agent memory is only as good as its schema and how to define a custom ontology with code.
Read it below.
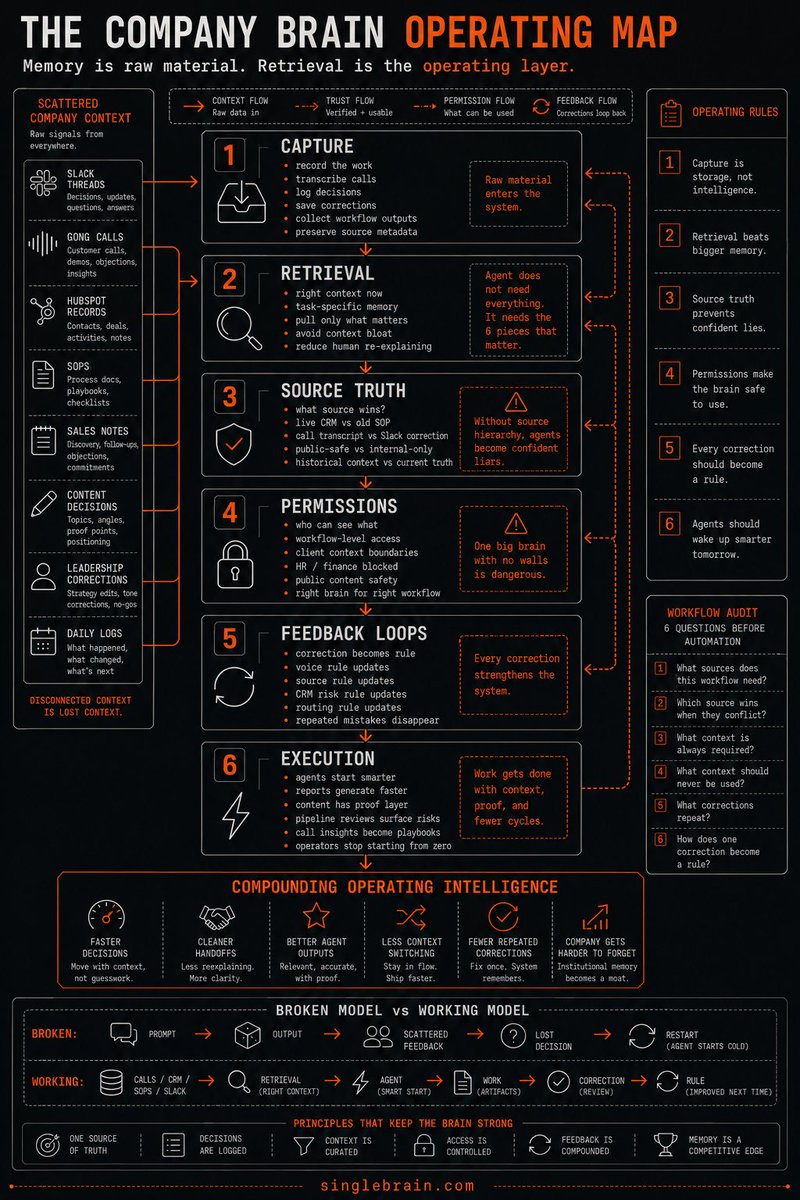
Every company is missing the same layer:
A company brain.
Right now, the memory of the business is scattered across calls, docs, Slack threads, dashboards, SOPs, and people's heads.
That's the part people miss when they talk about a company brain.
The value isn't a giant folder of company knowledge. Every company already has that.
The real advantage is the intelligence layer that sits between all that context and the work your team needs done.
This is the layer every AI-native company will need:
ANTHROPIC JUST DROPPED A ZERO TRUST PLAYBOOK FOR AI AGENTS
and it's not theory it's architecture
frontier AI compresses vulnerability-to-exploit timelines from months to hours
your agents face threats traditional access controls were never built to handle:
▫️ prompt injection through external data sources
▫️ tool poisoning via MCP server metadata
▫️ memory-based privilege retention across sessions
▫️ multi-agent pivot attacks
the framework breaks it into 3 tiers: Foundation, Enterprise, Advanced
https://t.co/uDuO9cq25H