Thrilled to share that I will be presenting at Talking Robotics next Wednesday, June 17! I will be presenting work on quantitative temporal logic and how richer robustness measures can be used to guide planning, learning, and control in autonomous systems. Please join if intrstd.
🤖Join us for Talking Robotics #90 with Ahmad Ahmad (WPI) to hear about Quantitative Temporal Logic for Safe and Robust Planning, Learning, and Control.
📅Schedule: June 17, 2026 | 09:00 PDT | 18:00 CEST
💻Zoom: https://t.co/CKITVElNHk
🔗Details: https://t.co/WIiDNuz64c
(8/8) Happy to discuss:
How TWTL bridges temporal gaps in rewards?
Our hybrid architecture's theoretical guarantees.
Extensions to more complex temporal specifications.
https://t.co/Gagcifwx3Q
📍Posters 2: June 5, 4:45-5:45, Michigan Union
#RL#PPO#TemporalLogic#L4DC2025#AI
(1/8) 🧵Presenting our work at #L4DC2025 on a fundamental RL challenge: learning in environments with delayed rewards (think soccer tactics that only pay off after many moves). We enhance PPO with hybrid policies and temporal logic.📍Posters 2: June 5, 4:45-5:45, Michigan Union
(7/8) Applications:
- Complex games with strategic depth
- Robotics tasks with delayed outcomes
- Industrial processes with long-term objectives
- Relevant for any domain where rewards are temporally separated from actions.
Please come come through if you’re around BU this Friday :)
I’ll be presenting our latest, submitted, work on “Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Environments with Delayed Rewards”
Preprint: https://t.co/Uc8131GKmx
In Cancun for the #CDC22@CSSIEEE
😀.
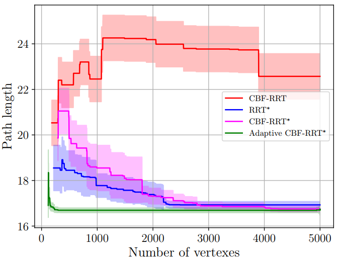
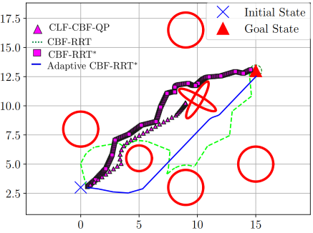
I will be presenting our work on adaptive sampling-based motion planning with safety-based local exploration and planning.
Please feel free to attend my talk on Thursday (10.40am) @ Acapulco. (1/4)
To improve the sampling performance, following some works in the literature, we represent the problem as a simulation of rare events problem, for which the Cross-Entropy method has been used to estimate the probability of such events. We exploit the Cross-Entropy method to (3/4)