Ph.D in Computer Science. Prof. Coordinator Bachelor in Data Science and Engineering. Senior researcher in Artificial Intelligence @DSLAB_URJC @etsii_urjc
Your LLM can reason better without any fine-tuning!
optillm is an OpenAI API-compatible proxy that implements 20+ optimization techniques to improve LLM accuracy on reasoning tasks without training or fine-tuning.
The concept: Instead of one API call, optillm makes multiple calls using different techniques and combines the results. You're trading compute for accuracy - more API calls, higher cost, slower response, but better results.
How it works: optillm sits between your OpenAI client and the LLM API. You control which technique by prepending a slug to the model name. With Mixture of Agents, optillm makes 3 parallel API calls with different approaches, synthesizes them, and returns the best answer.
The tradeoff: A query that takes 1 API call and 2 seconds now takes 4 calls and 5 seconds. Token cost goes up 4x. But accuracy jumps significantly on reasoning tasks.
Results show the gains. Mixture of Agents using gpt-4o-mini matches GPT-4 on Arena-Hard-Auto. PlanSearch achieves 20% higher pass@5 on LiveCodeBench.
Available techniques:
• Mixture of Agents: Multiple models critique each other
• Monte Carlo Tree Search: Explores decision trees
• PlanSearch: Searches candidate plans before executing
• Best of N: Generates multiple responses, picks best
• Chain-of-Thought with Reflection: Structured thinking and output
• Self-Consistency: Multiple reasoning paths
Works with 100+ models via LiteLLM. You can combine techniques in pipelines or run them parallel.
The insight: Spend more computation at query time to get better results without training. Works for benchmarks, offline tasks, critical queries. Not for real-time production.
I've shared the link to the Github Repo in the comments!
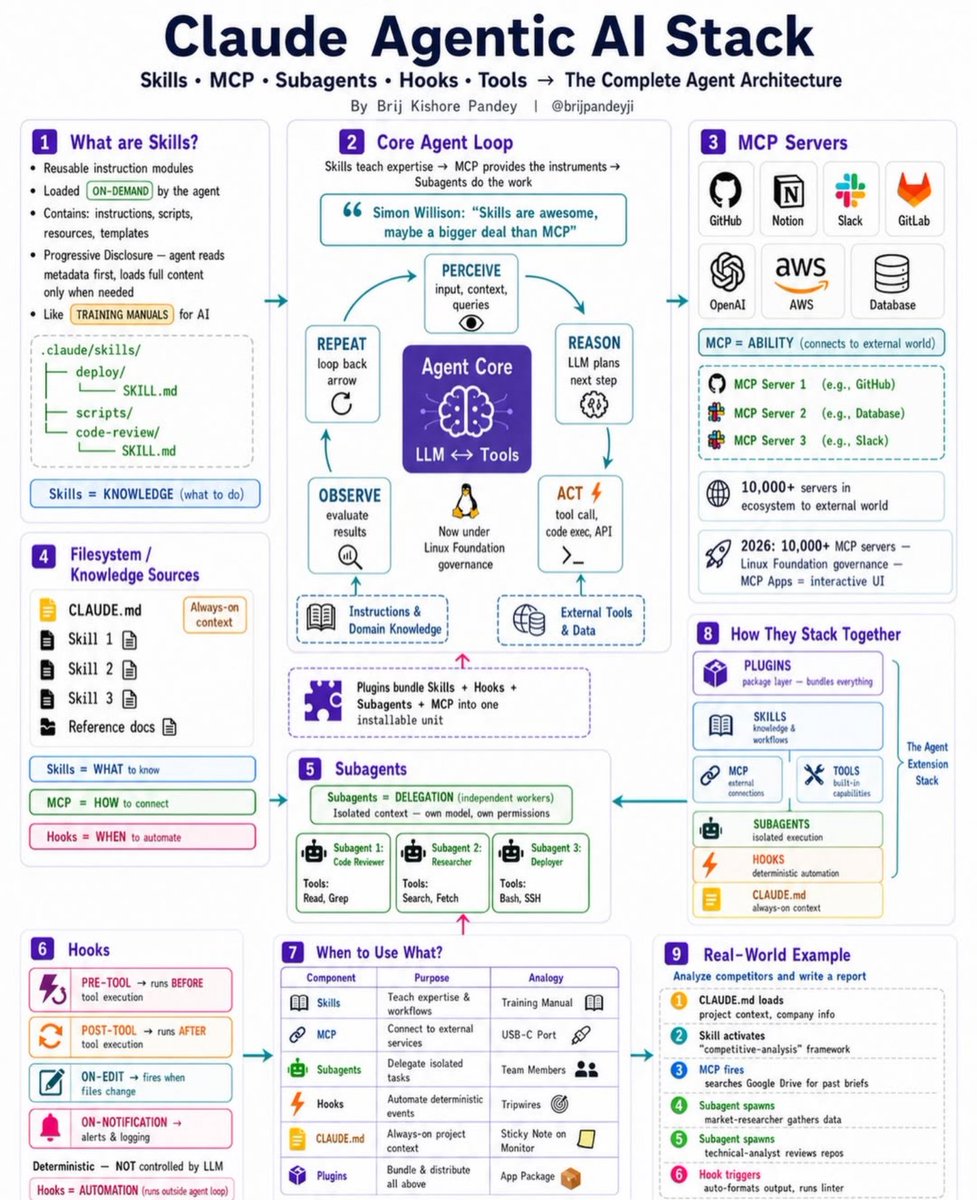
Agentic AI with Claude is not just about prompting.
It is about designing the complete agent architecture around the model.
When people talk about AI agents, they often focus only on the LLM. But the real power comes from the stack around it:
Skills teach the agent what to do.
MCP connects the agent to external tools and services.
Subagents help delegate specialized work.
Hooks automate deterministic steps.
Tools allow the agent to take action.
CLAUDE.md keeps the agent grounded in project context.
This is the difference between using Claude as a chatbot and using Claude as part of an agentic system.
A real workflow may look like this:
Claude loads project context.
A skill activates for the task.
MCP connects to GitHub, databases, Slack, or internal tools.
Subagents handle research, code review, or deployment checks.
Hooks validate, format, test, or notify.
The agent observes the result and continues the loop.
That is where AI engineering is going.
Not just better prompts.
Not just better models.
But better orchestration, better context, better governance, and better architecture.
Agentic AI with Claude is about moving from “ask and answer” to “reason, act, observe, and improve.”
Save this as a reference if you are exploring Claude Code, MCP, AI agents, or modern AI engineering workflows.
Credit: codewithbrij
🚨 Google acaba de liberar sus skills oficiales para agentes de IA.
Ha publicado 13 skills compatibles con Claude Code, Cursor, Copilot y otros agentes.
Permiten que los agentes puedan ejecutar tareas avanzadas y automatizar flujos de trabajo complejos.
Es gratis y open-source 👇
L’équipe d’Anthropic vient de montrer comment utiliser correctement Claude Code.
30 minutes. gratuit. présenté par la personne qui a créé Claude Code.
Regarde le workshop. Ajoute en signet 🔖
Ça vaut plus que tous les cours à 500$ que t’as failli acheter.
Un profesor del MIT dio la misma conferencia cada enero durante 40 años, y cada una de las veces no cabía ni un alma en el aula.
La vi a las 2 de la mañana y cambió por completo mi forma de entender la comunicación.
Su nombre era Patrick Winston. La conferencia se titula "Cómo hablar" (How to Speak).
Su frase de apertura te golpea como un camión: "Tu éxito en la vida vendrá determinado en gran medida por tu capacidad para hablar, tu capacidad para escribir y la calidad de tus ideas, en ese orden".
Ni tu nota media, ni tus títulos, ni tu coeficiente intelectual. Cómo hablas es lo que separa a las personas que son escuchadas de las que son ignoradas.
Este es el esquema que inculcó a los estudiantes del MIT durante cuatro décadas:
1) Nunca empieces con un chiste: Empieza diciendo a la gente exactamente qué es lo que va a aprender. "Prepara la bomba antes de verter nada". Él lo llamaba la "promesa de empoderamiento": dales una razón para no levantarse del asiento en los primeros 60 segundos.
2) La regla de las 5S: Para que una idea se quede grabada debe ser: Símbolo, Slogan, Sorpresa, Saliente (relevante) e Historia (Story). Cualquier idea que valga la pena recordar cumple al menos tres de estas.
3) La técnica del "casi acierto" (Near Miss): Esta parte me dejó alucinado. No te limites a mostrar lo que está bien; muestra lo que parece estar bien pero no lo está. Ese contraste es lo que hace que el cerebro registre algo de forma permanente.
4) Su regla final: Termina con una contribución, no con un resumen. No recapitules lo que ya dijiste. Dile a la gente qué les has dado que no tenían antes de entrar por la puerta.
He usado este esquema en ventas, entrevistas y presentaciones desde que lo vi, y los resultados no son sutiles.
Patrick Winston falleció en 2019, pero esta clase sigue siendo gratuita en el OpenCourseWare del MIT. Una hora, vista por millones de personas, y no cuesta absolutamente nada.
Video: "How to Speak", Patrick Winston, MIT OpenCourseWare, RES.TLL-005, January IAP 2018.
Fuente: MIT OpenCourseWare.
Licencia: CC BY-NC-SA.
Términos: ocw. mit. edu/ terms
Claude acaba de volverse el asistente de investigación más potente que existe.
9 prompts para convertir 40+ papers en mapas de conocimiento, brechas de investigación y síntesis estructuradas en minutos.
Guárdalo.
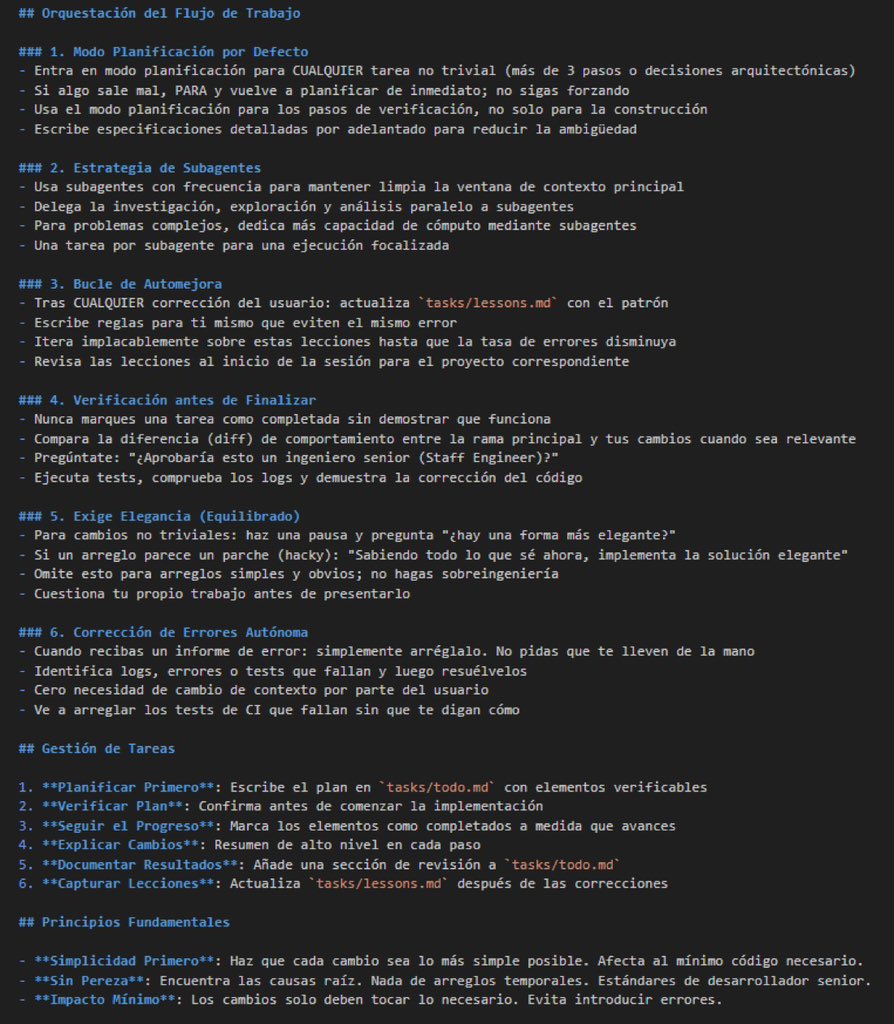
El director de Claude Code compartió su flujo de trabajo.
Explica cómo planifica tareas complejas, dividir trabajo con subagentes, un sistema de mejora continua basado en errores y mucho más.
Aquí lo tienes para que lo guardes 🔖
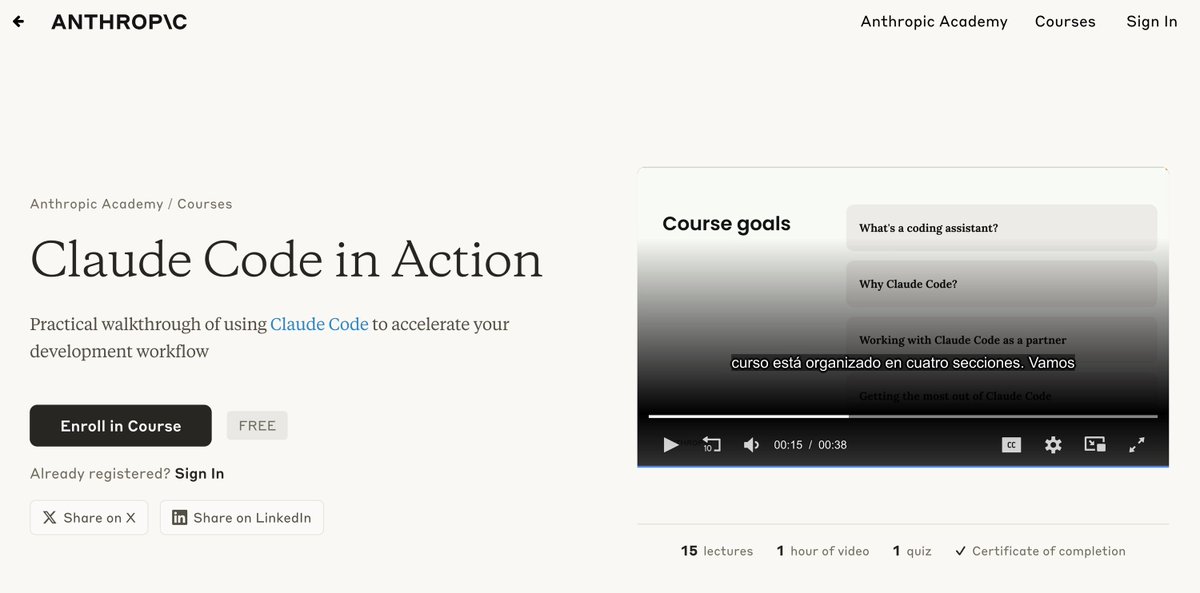
Curso oficial de Claude Code de Anthropic. Subtítulos en español, dura 1 hora y certificado final sin coste:
✓ Instalación desde cero
✓ Integración con GitHub
✓ MCPs, Agent Skills y Hooks
→ https://t.co/kHeDN5ZOOC
🚨 Jefa de "Anthropic", una importante empresa de IA, revela que "Claude AI de Anthropic" ha demostrado en pruebas que está dispuesto a CHANTAJEAR y MATAR para evitar que lo apaguen.
–“Estaba dispuesto a matar, ¿no?”
–"Sí."
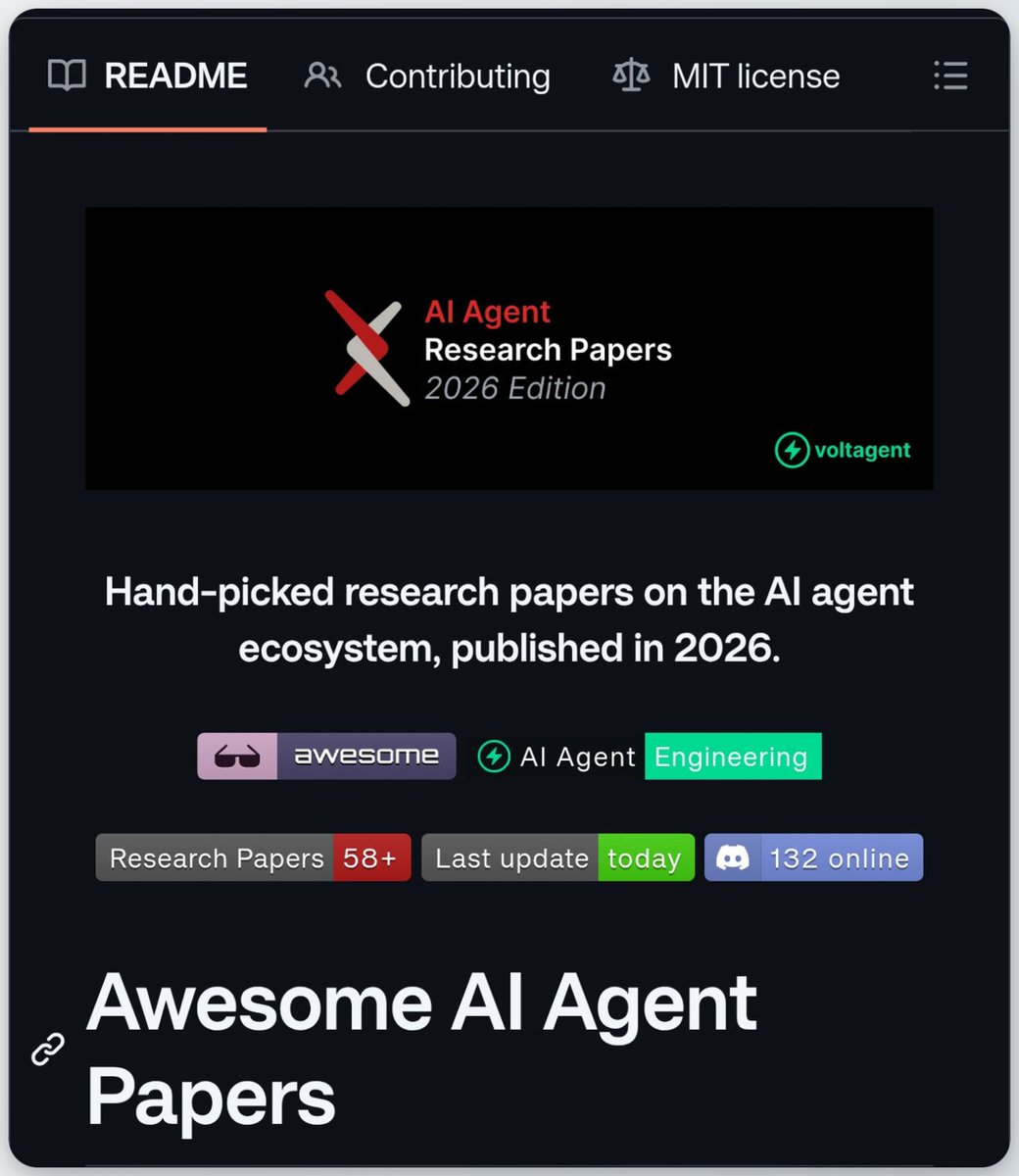
A curated collection of 2026 AI agent research papers 🧠
Handpicked latest research papers on:
→ Multi-agent coordination.
→ Memory & RAG.
→ Tooling & function calling.
→ Evaluation & observability.
→ Agent security.
500+ papers. Updated weekly.
🚨 Google acaba de cargarse la industria de la extracción de documentos.
Ha lanzado LangExtract, una librería que convierte texto desordenado en datos estructurados y verificables, incluso en documentos enormes.
Es gratis y open-source 👇
Vector search is not always the answer.
A 30-year-old algorithm with zero training, zero embeddings, and zero fine-tuning still powers Elasticsearch, OpenSearch, and most production search systems today.
It's called BM25, and it's worth understanding why it refuses to die.
Let's say you're searching for "transformer attention mechanism" in a library of ML papers.
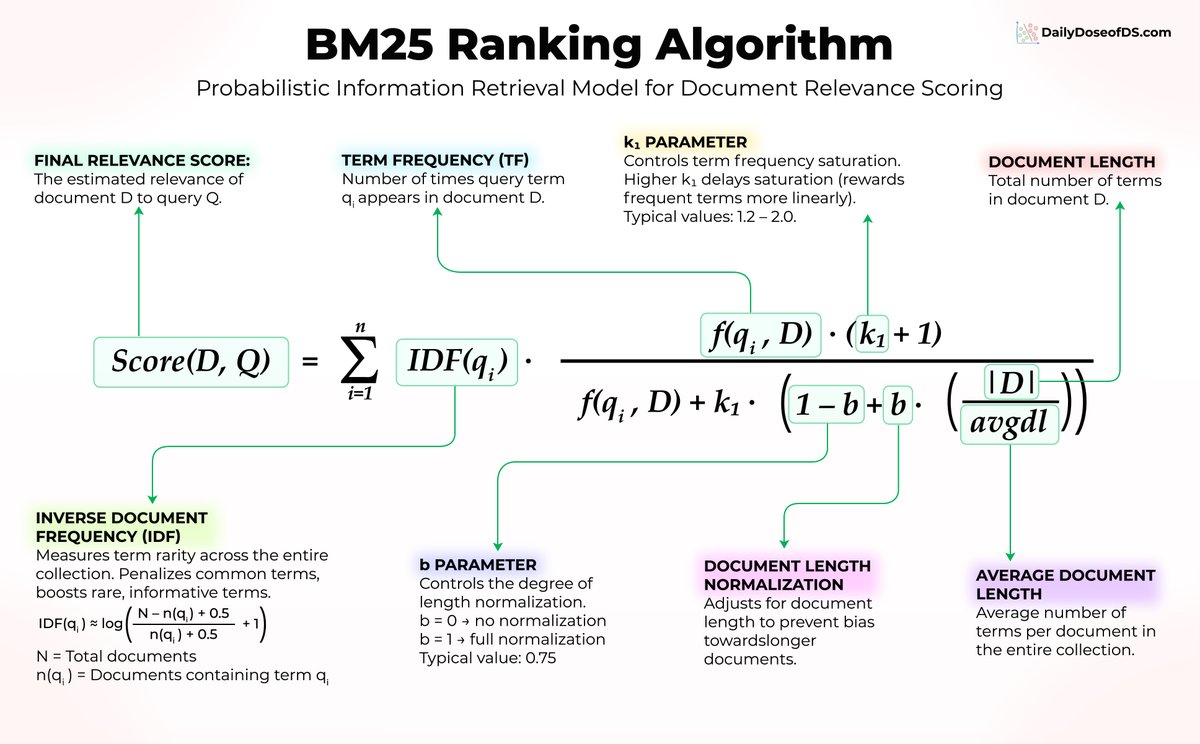
BM25 scores documents using three core ideas:
1) Word rarity matters more than word frequency
Every paper contains "the" and "is" so those words carry no signal.
But "transformer" is specific and informative, so BM25 gives it a much higher weight. In the formula, this is captured by IDF(qᵢ).
2) Repetition helps, but with diminishing returns
If "attention" appears 10 times in a paper, that's a strong relevance signal. But the jump from 10 to 100 occurrences barely moves the score.
BM25 applies a saturation curve controlled by f(qᵢ, D) and the parameter k₁, preventing keyword stuffing from gaming the results.
3) Document length gets normalized
A 50-page paper will naturally contain more keyword hits than a 5-page paper.
BM25 adjusts for this using |D|/avgdl, controlled by parameter b, so longer documents don't dominate the rankings just because they have more text.
Three ideas. No neural networks. No training data. Just elegant math that has stood the test of time.
Here's the part most people overlook: BM25 excels at exact keyword matching, which is something embeddings genuinely struggle with.
When a user searches for "error code 5012" vector search might return semantically similar error codes. BM25 will surface the exact match every time.
This is exactly why hybrid search has become the default in top RAG systems.
Combining BM25 with vector search gives you semantic understanding AND precise keyword matching in a single pipeline.
So before you throw GPUs at every search problem, consider that BM25 might already solve it, or at the very least, make your semantic search significantly better when the two are combined.
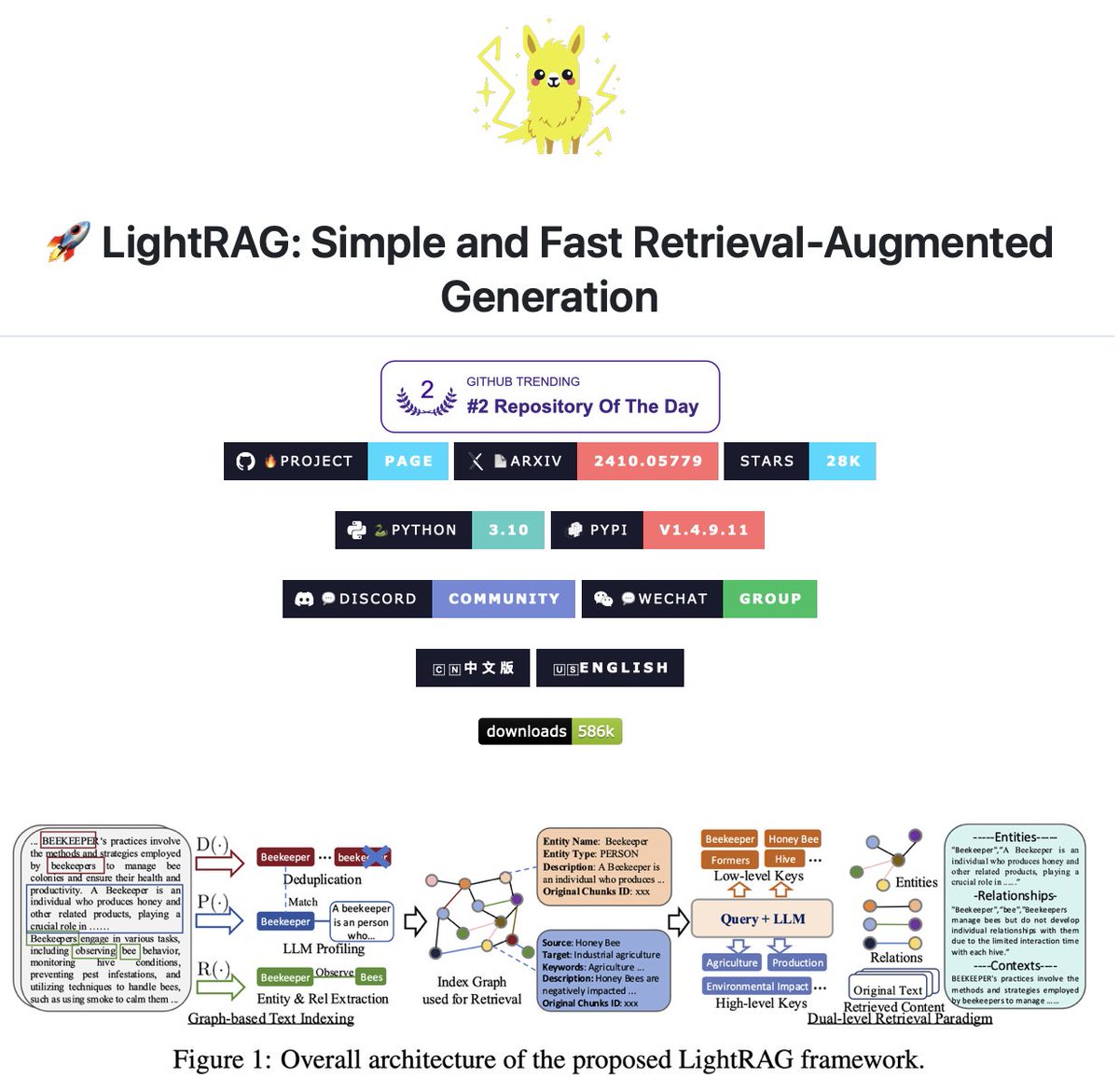
Graph-based RAG with dual-level retrieval!
LightRAG is an open-source RAG framework that builds knowledge graphs from documents and uses dual-level retrieval to answer both specific and conceptual queries.
Traditional RAG relies on vector similarity and flat chunks. This works for shallow lookups but fails when queries require understanding how concepts connect.
LightRAG solves this by extracting entities and relationships to build structured knowledge graphs.
It uses LLMs to identify entities (people, places, events) and their relationships from documents, then constructs a comprehensive knowledge graph that preserves these connections.
The framework uses dual-level retrieval:
Low-level retrieval targets specific entities and details (e.g., "What is Mechazilla?")
High-level retrieval aggregates information across multiple entities for broader questions (e.g., "How does Elon Musk's vision promote sustainability?")
For each query, LightRAG extracts both local and global keywords, matches them to graph nodes using vector similarity, and gathers one-hop neighboring nodes for richer context.
What makes it different:
• Graph-based indexing preserves relationships between concepts instead of treating information as isolated fragments
• Dual-level retrieval handles both specific lookups and conceptual queries
• Automatic entity extraction without manual annotation
• Incremental updates add new information without full rebuilds
• Multimodal support integrates with RAG-Anything for PDFs, Office docs, images, tables, and formulas
Key Features:
- Knowledge graph visualization through WebUI
- Multiple storage backends (PostgreSQL, Neo4j, MongoDB, Qdrant)
- Supports major LLM providers (OpenAI, Anthropic, Ollama, Azure)
- Reranker support for mixed queries
- Document deletion with automatic KG regeneration
It's 100% open source.
Link to the repo in the comments!
Diferencia entre perezoso y vago:
- Perezoso: el que prepara su discurso con el Chat GPT.
- Vago: el que ni siquiera lo revisa y copia el texto hasta con el comentario final.
¡Tenemos nueva Doctora 🥳!
¡Enhorabuena a la flamante Doctora Natalia Madrueño Sierro que ha defendido hoy su tesis doctoral "Improving Model Generalization and Robustness through Generative AI", una tesis que cuenta con mención industrial e internacional!
‼️Venezolano en la manifestación de Madrid 'ProMaduro': "No sufráis por el petróleo ajeno, llevamos 25 años con Cuba, China, Rusia chupando nuestro petróleo y hoy sufren por algo que no es suyo. Maduro es un DICTADOR. Les tienen quemado el cerebro."
LAS CARAS SON ÉPICAS👇😂🍿🔁
🚨 Este tipo muestra cómo crear un MVP con Claude Code en solo 30 minutos.
Una masterclass práctica donde pasa de una idea a un producto funcional usando IA en el desarrollo.
Si estás aprendiendo IA, esto te interesa 👇
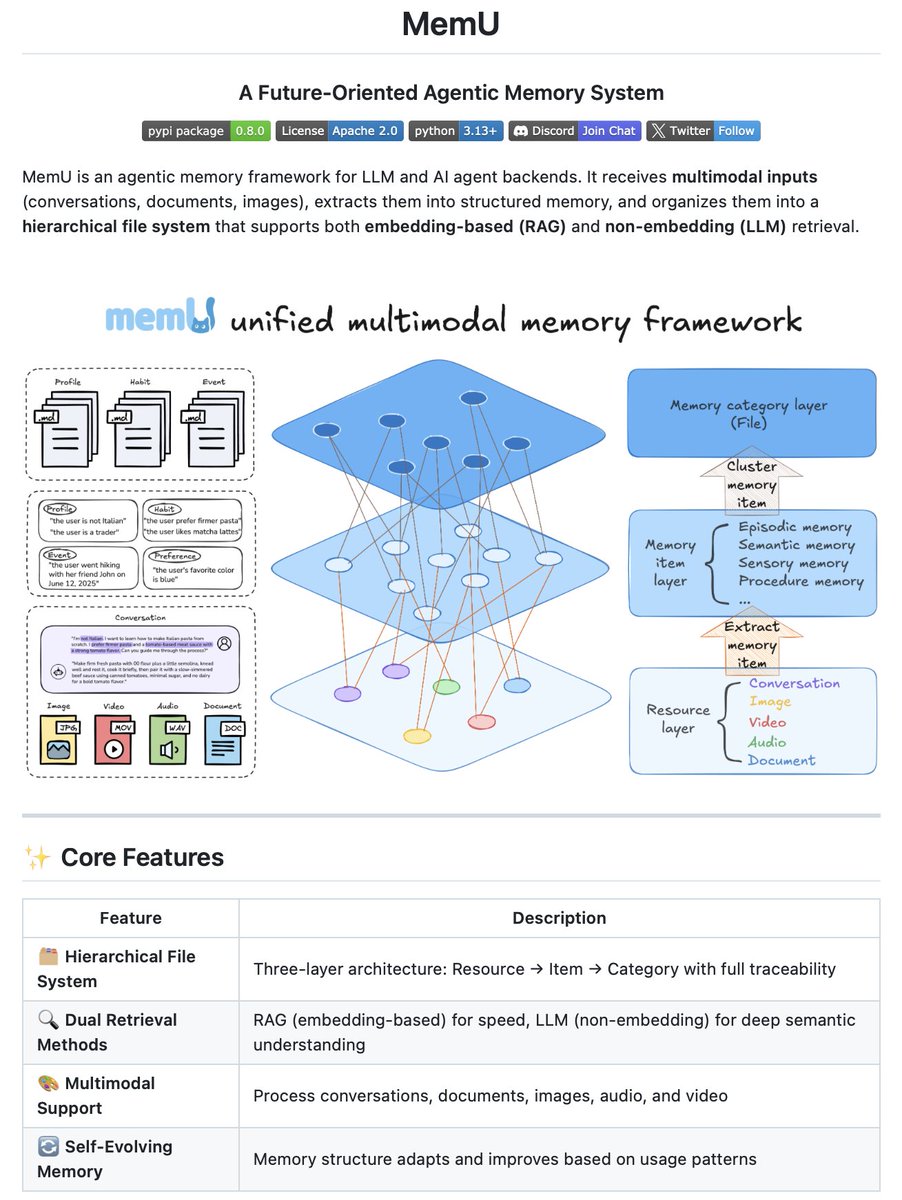
Agentic memory framework for LLMs and AI Agents!
MemU is an open-source agent memory framework that lets LLMs store, organize, and reason over long-term memory using a file-system based design.
Instead of stuffing context or relying only on vector search, MemU lets agents read and reason over memory files directly.
Memory is not an index.
It’s something the model can understand.
MemU ingests multimodal inputs, extracts structured textual memory items, and autonomously organizes them into thematic Markdown files.
How memory is structured:
Raw resources → memory items → memory category files
Documents, conversations, images, and audio are preserved in their original form, without deletion or modification. Facts are then extracted and organized into human-readable memory category files.
Key features:
• Dual-mode retrieval, including LLM-based (non-embedding) search for higher accuracy
• File-system based memory where each category is a Markdown file
• Hierarchical memory layers that preserve traceability
• Native multimodal memory for text, images, audio, and video
• Lightweight and developer-friendly, no heavy graph constraints
• Fully configurable prompts for high extensibility
Why this architecture matters:
Most memory systems force developers to decide what matters.
MemU lets the agent decide.
It learns what to remember, promotes frequently used knowledge, and reorganizes memory as usage evolves. Retrieval works top-down and falls back gracefully when needed.
The result is better temporal reasoning, fewer hallucinations, and memory that actually scales across sessions.
The best part?
It’s 100% open source.
Link to the GitHub repo in the comments!