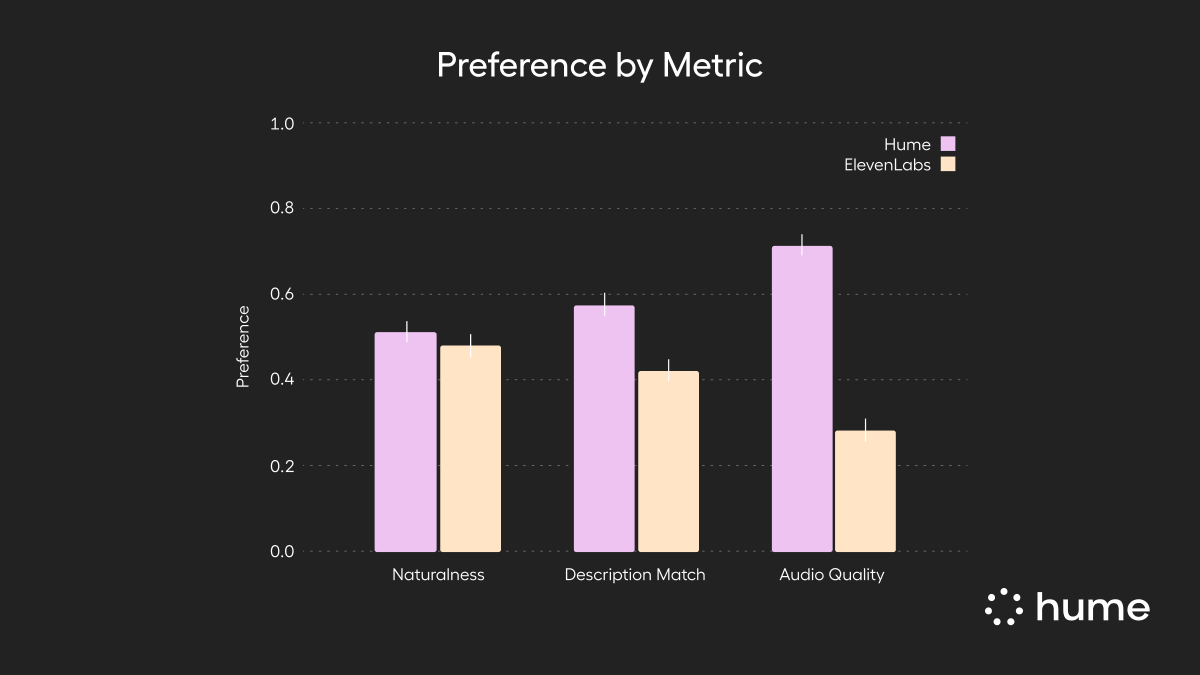
Today, voice models have no problem generating “angry” or “sad” expressions.
But ask for:
→ bored + fast
→ joy + shy
→ disappointment + confident
…and most systems collapse into stereotypes.
Our latest research blog explores why this happens — and how disentangling emotion from voice at the data layer improves expressive control. Read more below!
We’re excited to launch the 2026 ACII Dyadic Contest (DaiKon) Workshop & Challenge—a new benchmark for modeling emotional influence in dyadic dialogue.
Explore a sample of our conversational audio dataset: 945 sessions, 743 hours, across 5 languages.
Submissions due May 25. We look forward to your participation!
Introducing Octave 2: our next-generation multilingual text-to-speech model
What’s new:
- Fluent in 11+ languages
- 40% faster (<200ms latency) & 50% cheaper than Octave 1
- Multi-speaker conversation
- More reliable pronunciation
- New voice conversion & phoneme editing capabilities
For the month of October, we’re offering 50% off our Creator plan - use code OCTAVE2 at checkout!
2024: Voice Cloning
2025: What about personality cloning?
Hume’s voice AI can now not only mimic your voice but also speaking style and language.
It’s now available via our TTS and new speech-to-speech model, EVI 3, which is also launching today.
This had me floored
This isn’t just a talking model. It understands and expresses voice like a human, across any accent, tone, or style.
It doesn’t just speak. It performs.
Nervous stammer? Confident debate? A whispered secret? It's all in there...
Meet EVI 3, another step toward general voice intelligence.
EVI 3 is a speech-language model that can understand and generate any human voice, not just a handful of speakers. With this broader voice intelligence comes greater expressiveness and a deeper understanding of tune, rhythm, timbre, and speaking style.
Today, we’re releasing Octave: the first LLM built for text-to-speech.
🎨Design any voice with a prompt
🎬 Give acting instructions to control emotion and delivery (sarcasm, whispering, etc.)
🛠️Produce long-form content on our Creator Studio
Unlike traditional TTS that just “reads” words aloud, Octave understands how meaning affects delivery to generate emotional, human-like speech.
Today, we’re releasing Octave: the first LLM built for text-to-speech.
🎨Design any voice with a prompt
🎬 Give acting instructions to control emotion and delivery (sarcasm, whispering, etc.)
🛠️Produce long-form content on our Creator Studio
Unlike traditional TTS that just “reads” words aloud, Octave understands how meaning affects delivery to generate emotional, human-like speech.
Introducing OCTAVE, a next-generation speech-language model.
OCTAVE has new emergent capabilities, like on-the-fly voice and personality creation and much more 👇
Hume's EVI 2 generates speech and language in tandem, with rich context and emotion. It is the only speech-LLM model on the market that seamlessly integrates with frontier LLMs like @AnthropicAI's Claude 3.5 Sonnet.
Together, EVI 2 + Claude 3.5 Sonnet:
🎙️Over 2 million minutes of voice AI conversations completed
✨36% of users choose Claude, higher than any other LLM integrated with EVI 2
💸Developers using EVI 2 + Claude see an 80% reduction in cost and 10% decrease in latency through prompt caching
Loneliness and cognitive decline are major health challenges for older adults. https://t.co/KroZsgBrbo integrated Hume’s Empathic Voice Interface (EVI) into their digital companionship app, with powerful results:
🧠88% reported increased mental stimulation
🫂90% experienced reduced loneliness
All from just a few 15-minute sessions over 5 weeks.
Read the case study: https://t.co/sEcebD78Rt
Introducing Empathic Voice Interface 2 (EVI 2), our new voice-to-voice foundation model. EVI 2 merges language and voice into a single model trained specifically for emotional intelligence.
You can try it and start building today.
New Hume publication!
What’s the relationship between facial expressions and reported feelings, and how does it vary across cultures?
We gathered the most definitive evidence to date:
45,231 recordings of participants from North America, Europe, and Japan, reacting to 2,185 videos and reporting on their experiences.
Here’s what we found 👇