This is a significant news. I am not sure why more people have not noticed it. Adding some technical details below.
In von Neumann model, CPU manages a unified memory space and issues all instructions, including data movement. When GPUs were introduced as accelerators, this model persisted in modified form: the CPU retains ownership of the primary memory hierarchy and orchestrates GPU offload via explicit commands such as CUDA kernels. The GPU operates as a subordinate device, with data first staged in host DRAM or explicitly transferred via PCIe or NVLink before GPU kernels can access it. Storage access follows the same path, with the CPU managing I/O queues, page caches, and DMA operations. This creates serial bottlenecks in data-intensive AI workloads where model parameters, KV caches, and datasets frequently exceed on-package HBM capacity.
NVIDIA’s existing GPU Direct Storage already optimizes the data plane by allowing storage devices to DMA directly into GPU memory over PCIe or NVLink, thereby bypassing host DRAM. However, the control plane remains CPU-centric: the CPU must still allocate buffers, submit I/O commands, poll for completions, and handle errors. GIDS, debuting in the Vera Rubin platform, removes the CPU from the control plane entirely. The GPU issues storage commands natively, manages queue pairs, tracks completions, and places data directly into its address space. The result is true GPU autonomy over the full memory hierarchy, enabling thousands of concurrent I/O operations without CPU thread involvement.
HBF stacks 3D NAND dies in an HBM-like package with the same footprint, TSV interconnects, and wide bus to deliver approximately 1.6 TB/s read bandwidth and capacities up to roughly 512 GB per stack, representing 8 to 16 times the density of contemporary HBM stacks at lower cost per bit. Its drawbacks, including higher read latency than DRAM and limited write endurance of around 10^5 cycles, previously made it impractical under CPU-mediated access because the CPU’s overhead in managing slower, less predictable flash would erode the bandwidth gains and complicate scheduling. With GIDS the GPU can treat HBF as a directly addressable, high-capacity memory tier with GPU-native latency hiding via massive thread parallelism and prefetching. It can implement hybrid hierarchies in which HBM handles write-heavy structures such as KV cache updates during inference while HBF stores read-mostly data including model weights and long-context caches. A configuration of six HBF stacks plus two HBM stacks yields approximately 3,120 GB effective capacity versus roughly 192 GB in an all-HBM setup, representing more than a 16-fold increase while preserving the performance envelope required for frontier models. This directly addresses the memory wall constraining scaling of agentic AI.
Data movement currently accounts for roughly half of AI server power; in-package HBF combined with GIDS shortens physical distances and reduces CPU involvement, yielding meaningful system-level savings as racks approach 100 kW and beyond. The approach accelerates the industry trajectory toward accelerator-first designs and complements other Vera Rubin innovations such as HBM4, NVLink 6, and the Vera CPU for orchestration rather than primary control. It also strengthens the commercial case for HBF standardization efforts already underway. Cloud providers deploying Vera Rubin in the second half of 2026 will likely serve as early adopters, driving memory suppliers to accelerate HBF sampling targeted for late 2026 and software enablement for early 2027 inference systems.
In summary, GIDS is not merely an incremental I/O optimization but a fundamental redefinition of the GPU as a first-class memory manager. This makes HBF a credible, cost-effective extension of the memory hierarchy and supplies the precise architectural evolution needed to sustain AI scaling beyond pure HBM economics.
https://t.co/jzGVpDqPm7
the kelp rsETH post-mortem is wild
lazarus (dprk) compromised two rpc nodes that layerzero dvn was relying on. swapped the op-geth binaries. wrote a custom payload that forged messages *only when the dvn queried* - every other IP, including monitoring, saw clean truthful data.
then they DDoS'd the healthy RPCs to force failover onto the poisoned ones. drained $290M. self-destructed the malicious binaries to erase tracks.
they targeted rsETH because kelp ran a 1-of-1 DVN config with layerzero as sole verifier
How I get my claw to be a durable AI agent I never have to instruct twice
Paste this into your OpenClaw's AGENTS.md or send it as a message:
You are not allowed to do one-off work. If I ask you to do something and it's the kind of thing that will need to happen again, you must:
1. Do it manually the first time (3-10 items)
2. Show me the output and ask if I like it
3. If I approve, codify it into a SKILL.md file in workspace/skills/
4. If it should run automatically, add it to cron with `openclaw cron add`
Every skill must be MECE — each type of work has exactly one owner skill. No overlap, no gaps. Before creating a new skill, check if an existing one already covers it. If so, extend it instead.
The test: if I have to ask you for something twice, you failed. The first time I ask is discovery. The second time means you should have already turned it into a skill running on a cron.
When building a skill, follow this cycle:
- Concept: describe the process
- Prototype: run on 3-10 real items, no skill file yet
- Evaluate: review output with me, revise
- Codify: write SKILL.md (or extend existing)
- Cron: schedule if recurring
- Monitor: check first runs, iterate
Every conversation where I say "can you do X" should end with X being a skill on a cron — not a memory of "he asked me to do X that one time."
The system compounds. Build it once, it runs forever.
OpenClaw running Gemma 4 locally at 25 tok/s on a MacBook Air with 16GB RAM. Atomic Chat's TurboQuant algorithm compresses the KV cache so aggressively that models which used to need 32GB+ now run smoothly on base configs. No cloud, no API costs.
This is where local AI is heading!
no fucking way lol
people in china are getting their colleagues fired by secretly training AI agents to replace them 😂
they secretly learn the role, write up a doc describing the tasks, train an AI to do it… then prove they’re fireable
they’re apparently doing it to prevent THEMSELVES from getting replaced by ai
in response someone has created an “anti-distillation.skill” that’s gone viral on github to counter the attacks 😂
6/ Lessons for ZK developers:
Always constrain intermediate values
Don't confuse <-- (assignment) with <== (constraint)<-- only assigns a value for the witness generation
<== both assigns and constrains the value
Use range checks for bit operations
Test with invalid witnesses to verify soundness
🧵 THREAD: Deep-diving into a critical ZK vulnerability: Unsound Left Rotation in Circom
1/ I've been exploring the @zkbugs repository, which documents 89 ZKP vulnerabilities across 7 DSLs.
5/ In ZK circuits, every intermediate value must be fully constrained. Here, we can choose arbitrary values for part1 and part2 as long as they satisfy: (part1 / 2L) + (part2 * 2(32-L)) === in
5/ This vulnerability highlights a critical pattern in ZK circuits: never trust <-- assignments without proper constraints. Any value that affects the circuit's output must be fully constrained.
4/ The bug? The signals part1 and part2 aren't properly constrained. They're computed using <-- (assignment) but nothing ensures they match the intended bit operations. Only their relationship is constrained in the last line.
6/ For example, with input=5 and L=3, the correct rotation should yield out=40 (binary: 00000000000000000000000000101000). But we can set part2=2 and compute part1 to satisfy the constraint, resulting in a different output that still verifies!
Just found a GOLDMINE for ZK security researchers🔥
A Github repository containing close to 100 security vulnerabilities related to zero-knowledge proofs. Whenever you do ZK audits, make sure to go through those🫡
https://t.co/UNYL7oPM4q
Whenever I've met/worked with an auditor that later becomes godlike, there is always this one thing...
They are just eager to do more & more audits, not fearing new types of math, algorithms, financial business logic etc. It's always about learning, never about a shortcut✌️
Want to know how I use Cursor and V0 to deliver MVPs FAST for my clients?
Here’s my EXACT workflow to plan, design, and launch products efficiently. Tip #8 includes the game-changing prompt I use every single time. THREAD BELOW.
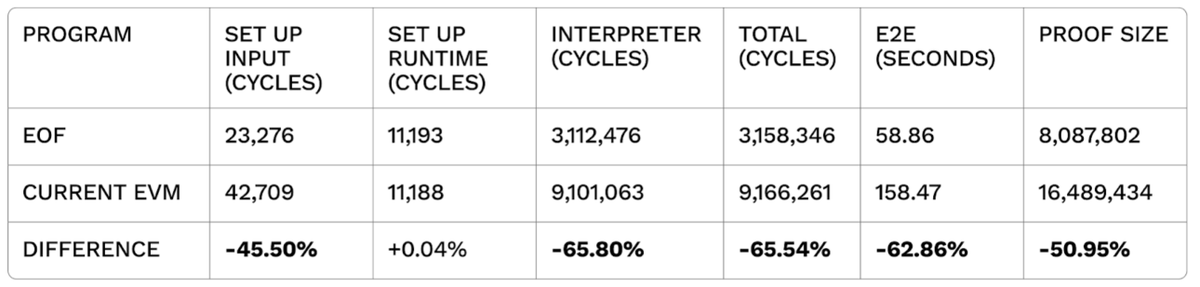
What are the performance benefits of EOF (EVM Object Format)?
At the @SuccinctLabs residency, my benchmarks reveal ZK proving EOF is ~3x more efficient and runs 2.69x faster than the current EVM version ⛽
(link below)
🔐 Discord introduces DAVE, its custom end-to-end encryption (E2EE) protocol for voice and video calls.
Learn more: https://t.co/xH7IF7PBIl
However, text messages remain unencrypted, meaning they are still vulnerable to content moderation and other risks.
#cybersecurity
Whiteboard Session w/@PrimordialAA and @mikebelshe.
Topic: How Omnichain WBTC Works
-- potential to deploy on 80+ chains
-- composability across DeFi
-- secure, fast, and cheap transfers between chains
🎧 👇