In the NYT today, Cade Metz implies that I left Google so that I could criticize Google. Actually, I left so that I could talk about the dangers of AI without considering how this impacts Google. Google has acted very responsibly.
Drago loved his family and was a deeply caring father. His daughter, Victoria has a disability and requires extensive care. We are raising money to help Drago’s family to continue to provide Victoria with the care she needs. Any help will be appreciated!🙏🏼
https://t.co/AWhrWSHxdw
Bard is now available in the US and UK, w/more countries to come. It’s great to see early @GoogleAI work reflected in it—advances in sequence learning, large neural nets, Transformers, responsible AI techniques, dialog systems & more.
You can try it at https://t.co/m9D7JYTHvU
LLMs are still making sh*t up.
That's fine if you use them as writing assistants.
Not good as question answerers, search engines, etc.
RLHF merely mitigates the most frequent mistakes without actually fixing the problem.
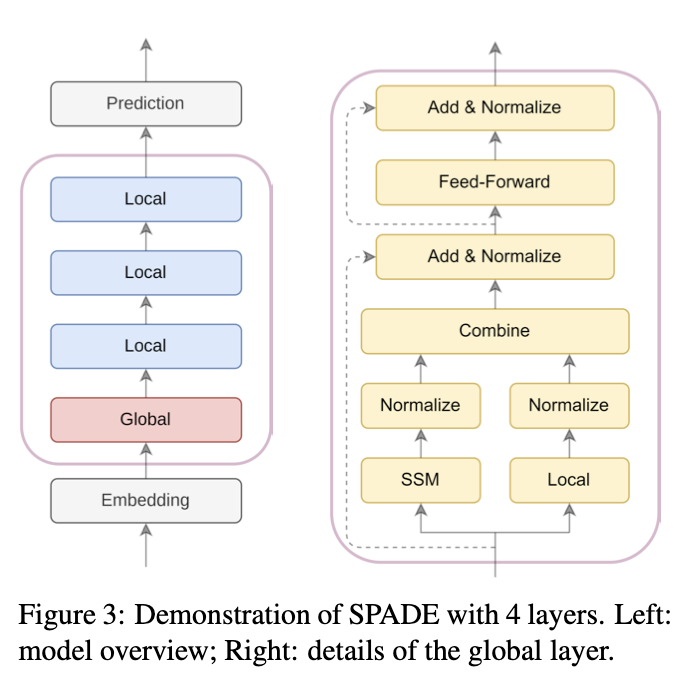
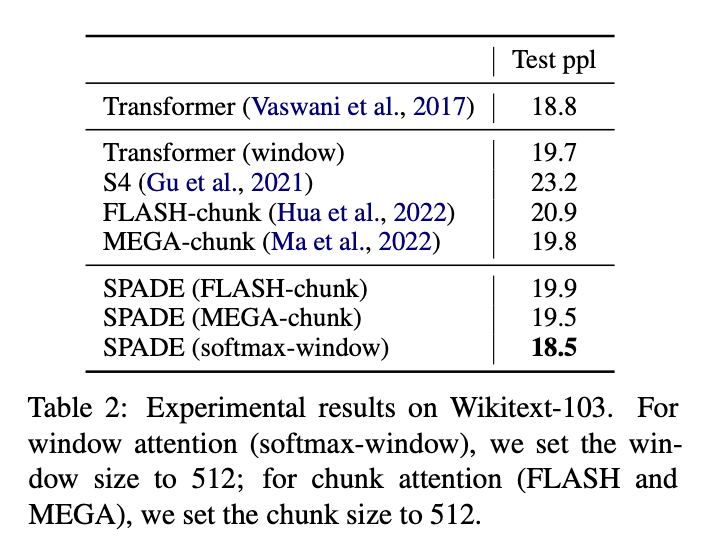
Need scalable and efficient large language models for long sequences? Check our SPADE models in https://t.co/D190LCZw7U. By leveraging a state space layer, SPADE complements the lack of long-range dependency issue in transformer models using local attentions. (1/3)
Q: @FAccTConference (main AI Ethics conf) was $10,000 short. They also turned down Google sponsorship due to G's continued refusal to address structural discrimination & trauma to me & @timnitGebru specifically. Is there any issue w/ me starting a GoFundMe to make up the diff?
Today we're releasing all Switch Transformer models in T5X/JAX, including the 1.6T param Switch-C and the 395B param Switch-XXL models. Pleased to have these open-sourced!
https://t.co/02YVX4dpUB
All thanks to the efforts of James Lee-Thorp, @ada_rob, and @hwchung27
🚨[New Paper] Check out our recent work on parameter-efficient fine-tuning.
We introduce a new method to boost the performance of Adapter to outperform full model fine-tuning.
Great collaboration with @subho_mpi, @AllenLao, Jing Gao, @AhmedHAwadallah and @JianfengGao0217.
🤓In 2017, Google researchers introduced the Transformer in "Attention is all you need", which took AI by storm.
5 startups were born: @AdeptAILabs (🏦 @airstreet), Inceptive, @NEARProtocol, @CohereAI, CharacterAI.
Only 1/8 authors remain @GoogleAI, another is at @OpenAI.
😉
Today Meta AI is sharing OPT-175B, the first 175-billion-parameter language model to be made available to the broader AI research community. OPT-175B can generate creative text on a vast range of topics. Learn more & request access: https://t.co/3rTMPms1vq
Today, an exciting paper from @MSFTResearch:
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
https://t.co/NQVigh6kUL
While it's too early to say, this may be remembered as the single biggest efficiency advancement in hyperparameter tuning.
When a neural network is too large to pretrain more than once, tuning its hyperparameters is practically impossible. Today, we announce μTransfer—a new technique that can tune the 6.7 billion parameter GPT-3 model using only 7% of the pretraining compute: https://t.co/RnS5HZboq0
























![gordic_aleksa's tweet photo. [🥳new video🧠] "Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer" (μTransfer) paper explained!
YT: https://t.co/DGI5tybyDL
@TheGregYang @edwardjhu @ibab_ml @sidorszymon @AllenLao @merettm @WeizhuChen @JianfengGao0217 @MSFTResearch @OpenAI https://t.co/SVWnz1VnKy](https://pbs.twimg.com/media/FOC9SjRX0AYPzoo.jpg)





























