For mechanistic interpretability researchers 🚨
So after grieving our 4.5 rejection at @icmlconf , we went back and took a closer look at the rebuttal results, and ended up finding something pretty surprising.
When we look at quantization per task, the error over prompts is about 70% linearly reconstructable(like we can fix 70% of the error with steering), which is wild, because in standard 4-bit quantization it’s basically zero.
Even earlier in the project, we noticed something odd: in some cases, the quantized model was actually doing better than the original model on specific tasks.
That got us thinking. One hypothesis is that per-task quantization might actually be cleaning up noise in the residual stream for that task. And more interestingly, the direction of the error doesn’t seem random, it looks like it changes gradually along the task direction, kind of like a “correct → incorrect” direction in the prefill stage.
Still early, but it feels like there’s something real going on here. What do you think?
My work was rejected with a ~Spotlight score @icmlconf 😅
I strongly believe in applied interpretability. It’s much more than just steering, we need more research in applied interpretability for reasoning, distillation, quantization, alignment, evaluation, pre/post-training, and continual learning.
🚨 If you’re a researcher in these domains, I’d be happy to discuss, you also might find our paper interesting.
We propose per-task quantization. Using interpretability methods, we identify important features in the residual stream and allocate bits per layer accordingly, giving more to layers that matter most for the target task. So far, we achieve SOTA results on per-task quantization.
Excited that our paper on Actionable Interpretability got accepted to ICML!
And just in time -- we also heard that our Actionable Interpretability workshop will be happening again, in COLM!
See you in Korea 🇰🇷 and SF🌉
[Arxiv paper link in the comment]
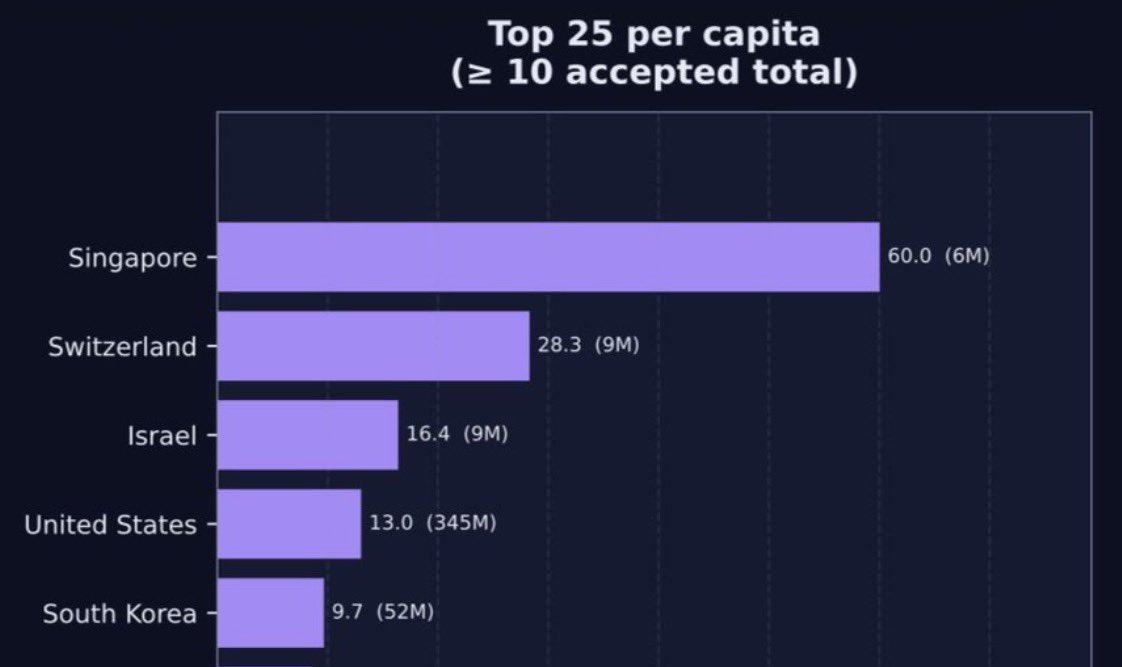
I liked it, so I extended the analysis to NeurIPS, ICLR, and ICML 2025
including acceptance rates for ICLR, accepted papers per capita, and additional analyses.
The calculation uses 1/K credit per paper author, where K is the number of authors on the paper.
I liked it, so I extended the analysis to NeurIPS, ICLR, and ICML 2025
including acceptance rates for ICLR, accepted papers per capita, and additional analyses.
The calculation uses 1/K credit per paper author, where K is the number of authors on the paper.
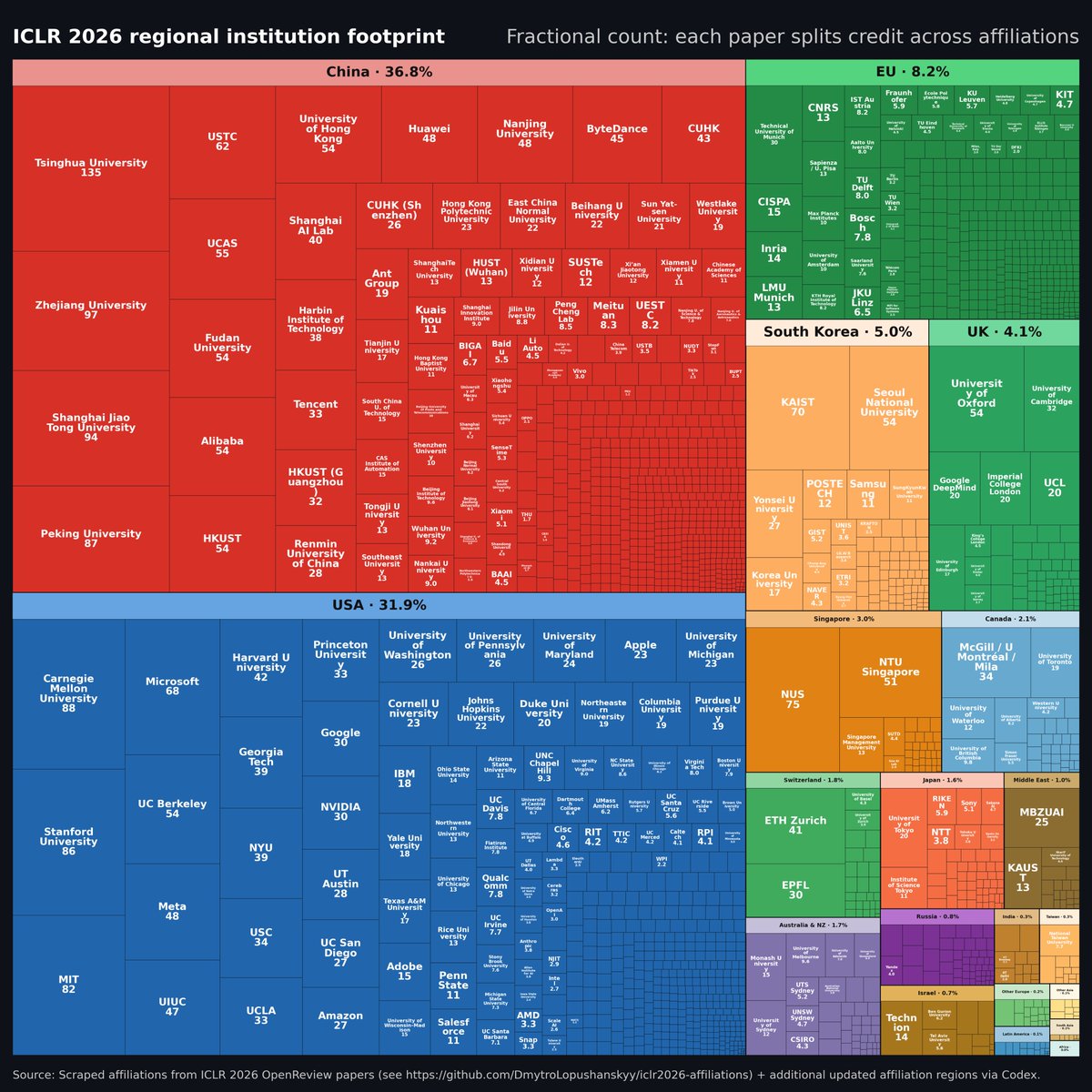
@Hesamation Better version without arbitrary institution cutoff, some data cleaning and splitting contribution of each paper among institutions. China + USA dominant ofc, but looks a bit different, doesn't it?
Some random thoughts about hosting people on our podcast and good managers.
Sometimes I reach out to founders/Researchers about coming on to the podcast, and they say "we're building something right now, let's talk in a few months." I get it if you don't have time (even though it's only 90 minutes :), but I think the idea that you should only come talk after you've released a model/product is wrong.
Waiting until you ship to say "I have a good product, let's talk about it!" is just one reason to come on. There are plenty of others - you want people to hear about your company, you want to recruit new researchers, you're so excited you can't stop yourself (it is exciting!).
As the host, and I think this goes for our audience too, what we really want to know is the why. The thinking, the process, the difficulties, how you see the future. The best episodes weren't the ones where people came on and said "I built this product / trained this model, here's how it works." The best ones were where people talked about the process itself and gave us insight into what doing AI research actually looks like these days.
And honestly, I think the same is true when you work with your employees. The bottom line matters, but the process matters even more. When you decide on a new direction or a pivot, when you're doing a reorg or changing what people work on - don't just tell them at the end. Share it along the way. You'll get much better feedback too.
Anyway, come talk on our podcast!
I’m so excited! Silences Biases was just selected as an honorable mention for the:
🏆Israel National Al Safety Research Prize 🏆
Current fairness benchmarks can create a false sense of fairness by treating refusal answers (e.g., “I can’t answer that”) in bias-focused multiple-choice questions as the fairest response, even when biased preferences still exist internally.
We also perform introspection analysis showing that models still contain biased and stereotypical internal representations, even when these biases are concealed by refusal mechanisms during explicit preference questions.
We call these hidden preferences silenced biases, biases encoded in the model’s latent space but masked by safety alignment. To uncover them, we propose the Silenced Bias Benchmark (SBB), which uses activation steering to reduce refusals during evaluation and expose hidden biases.