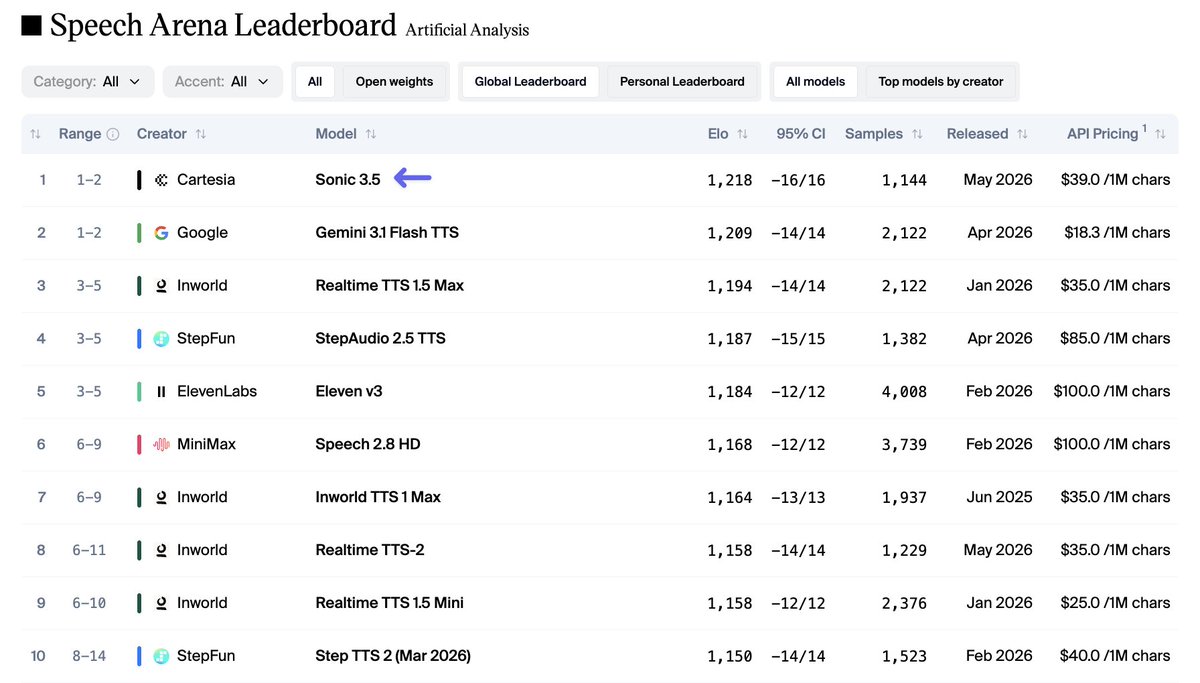
Cartesia’s Sonic-3.5 takes the #1 spot on the Artificial Analysis Speech Arena Leaderboard, surpassing Inworld Realtime TTS 1.5 Max and Google’s Gemini 3.1 Flash TTS
Sonic-3.5 is the latest TTS model from @cartesia . It supports 42 languages, including 9 Indian languages, with 500+ voices available out of the box. The model has been highly preferred among voters in the TTS Arena, with its demonstrated naturalness and accurate transcript following.
Key takeaways:
➤ Quality: Sonic-3.5 has an Elo score of 1,218 (+16/-16) based on 1,144 arena appearances, placing it ahead of Inworld Realtime TTS 1.5 Max at 1,194 and Gemini 3.1 Flash TTS at 1,209
➤ Pricing: Sonic-3.5 is priced at $39/1M characters, a premium compared to Gemini 3.1 Flash TTS at $18.3/1M characters, and Inworld Realtime TTS 1.5 Max at $35/1M characters
➤ Speed: 105.5 characters per second, compared to 205 characters per second for Inworld Realtime TTS 1.5 Max and 26.3 characters per second for Gemini 3.1 Flash TTS
See more details and listen to samples below 🧵
@JentseHuang Thanks @JentseHuang ! Sounds very interesting, we mostly used Thinkig States to represent reasoning in our work but treating them as an internal memory indeed sounds very natural. I’ll have a look on your experiments
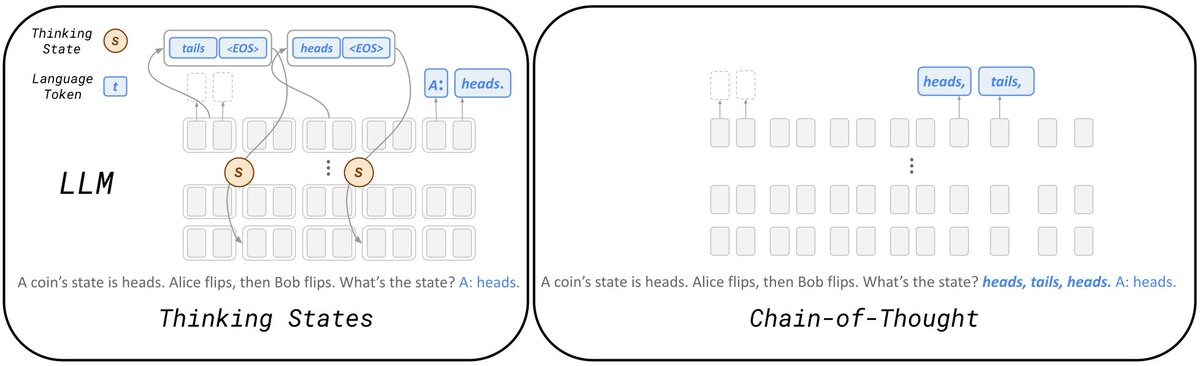
Can LLMs reason internally while processing their inputs, similar to how humans can think ahead as we process information? Our latest work introduces Thinking States, a novel architectural adaptation that transforms reasoning into a internal recurrent process.
By training models to maintain a dynamic thinking state, we achieve significant inference speedups over Chain-of-Thought while substantially outperforming existing latent reasoning methods.
Paper: https://t.co/nXJ9szfbrT
Thinking States outperforms existing latent reasoning methods on multiple benchmarks and matches Chain-of-Thought performance on multi-hop QA, while leading to faster inference times. Furthermore, Thinking states exhibit superior length generalization in state-tracking tasks, successfully extrapolating to sequences significantly longer than those seen during training.
This work was done during an internship at Google Research with an incredible team of collaborators: @clu_avi@megamor2@amirgloberson@jonherzig@LiorShani286867@ISzpektor
Read the full paper and explore our findings here: https://t.co/nXJ9szfbrT
A major challenge in latent reasoning is finding effective supervision for the reasoning process. Since thinking states are represented in natural language, we can leverage existing Chain-of-Thought data for supervision. Furthermore, as this supervision is available in advance, we use it to teacher-force the thinking states themselves. This circumvents the need for costly recurrent optimization via backpropagation through time (BPTT), enabling fully parallel training and maintaining nearly constant training costs regardless of reasoning depth.
Honestly cannot believe that our work got the BEST PAPER award @iclr_conf !!!
This was an amazing experience with my collaborators @JonathanBerant@ankgup2 , looking forward to share with everyone at the conference.
Reach out if you want to chat!
Excited to share my work with @JonathanBerant@ankgup2!
We show pretraining on task data alone suffices to bridge the gap between state space models and transformers on Long Range Arena, leading to a significantly better estimate of model capabilities.
https://t.co/rbQeVUo5m0
🧵
[4/4] Investigating the effects of data scale, we find self-pretraining is most effective in low-data regimes, underscoring its importance for evaluation across all dataset sizes. We further show that self pretraining is effective across model sizes and when compute is limited.
Excited to share my work with @JonathanBerant@ankgup2!
We show pretraining on task data alone suffices to bridge the gap between state space models and transformers on Long Range Arena, leading to a significantly better estimate of model capabilities.
https://t.co/rbQeVUo5m0
🧵
[3/4] The marked effect of self-pretraining on long-sequence tasks leads us to rethink the necessity of complex designs, with Diagonal Linear RNNs (DLR) as a specific example. Our findings indicate that, when pretrained, simple architectures can be as effective as complex designs



![AmosaurusRex's tweet photo. [4/4] Investigating the effects of data scale, we find self-pretraining is most effective in low-data regimes, underscoring its importance for evaluation across all dataset sizes. We further show that self pretraining is effective across model sizes and when compute is limited. https://t.co/kiDNqTfmh6](https://pbs.twimg.com/media/GAlVh0OXoAAZ1Oq.png)
![AmosaurusRex's tweet photo. [3/4] The marked effect of self-pretraining on long-sequence tasks leads us to rethink the necessity of complex designs, with Diagonal Linear RNNs (DLR) as a specific example. Our findings indicate that, when pretrained, simple architectures can be as effective as complex designs https://t.co/LSs1gwgZXw](https://pbs.twimg.com/media/GAlVZCyWkAEYnyx.png)






























