Seeing a lot of people struggling to enable Telegram Rich Messages in Hermes @NousResearch
Here’s the fastest way to turn it on:
Tell your agent:
1️⃣ Update yourself
2️⃣ Enable rich messages in my config: rich_messages: true
3️⃣ Restart the gateway
4️⃣ Send a test message
Then test it with this prompt:
Let’s test now
Summarize this as a Telegram rich table with columns: Task, Owner, Status.
Give me a checklist for the deployment, using completed and incomplete task boxes.
Format this as:
- heading
- short summary
- table
- checklist
- collapsible details section for risks
## Supported useful formats
Use normal Markdown-style syntax:
## Sprint Status
| Item | Owner | Status |
|---|---|---|
| Driver App release | Alex | ✅ Done |
| Portal QA | Sam | In progress |
| Route optimizer | Luke | Blocked |
- [x] Review PR
- [ ] Run staging smoke test
- [ ] Send release note
<details>
<summary>Risks</summary>
- QA may slip if staging data is stale.
- Route optimizer dependency needs confirmation.
</details>
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.
Prepare for takeoff. ✈️ Flight simulator is now available globally on web to all users. https://t.co/hQP0No142P
We've recently added many our most powerful professional desktop features to web. Elevation profiles, new import types, but there's always been one other feature you've been asking us to add to the web version of Google Earth, just for fun...
Where will you fly? Share your best maneuvers, views, and flyovers with us!
I asked Claude Fable 5 to reverse engineer a 1993 DOS game with no source code.
It read the raw machine code, rewrote the engine in C, and gave me a fully editable port for every platform.
30 min from EXE to iPhone.
Sharing it all so you can revive your own childhood games!
about loop engineering.
everyone's saying the same thing this week. you don't prompt agents anymore, you design loops that prompt them.
here's the job that loop hands right back to you.
a loop running unattended is also a loop failing unattended.
loop engineering takes you off prompting. it takes you off curating context. it takes you off babysitting a single run. it does not take you off debugging. it just moves the debugging somewhere worse, into runs you were never watching, with far too much of it to read through by hand.
even the loop engineering posts admit this themselves, usually somewhere near the end. you can only walk away from a loop if you trust the thing checking it. a checker you don't trust drops you right back into reading every output by hand, which is the exact work the loop was supposed to take off you.
so stack the layers up, prompt, context, harness, loop, and one job survives all of them. closing the loop on failure. the leverage point moved. debugging stayed exactly where it was.
i was writing about this exact gap yesterday, before the loop talk picked up today. the idea was simple. make debugging its own loop. a failure leads to a root cause, a proposed fix, a rerun against the exact inputs that broke, and a test that locks it out for good. the checker gets built from your real failures instead of guessed at up front.
Opik, the tool i was writing about, does exactly this. a built-in agent reads the trace, finds the root cause, proposes a diff, you approve it, and that failure becomes a permanent regression test. every break you debug makes the loop a little harder to break next time, which is the kind of checker the loop engineering crowd keeps saying you need before you walk away.
if you're designing loops you actually plan to walk away from, it's worth a look.
Opik is 100% open-source under Apache-2.0 license.
GitHub repo: https://t.co/MEC26owCdo
(don't forget to star 🌟)
loop engineering moved the leverage point. it didn't remove the engineer who still has to close the loop when something breaks.
the full article, Your Agent Harness Should Repair Itself, is quoted below.
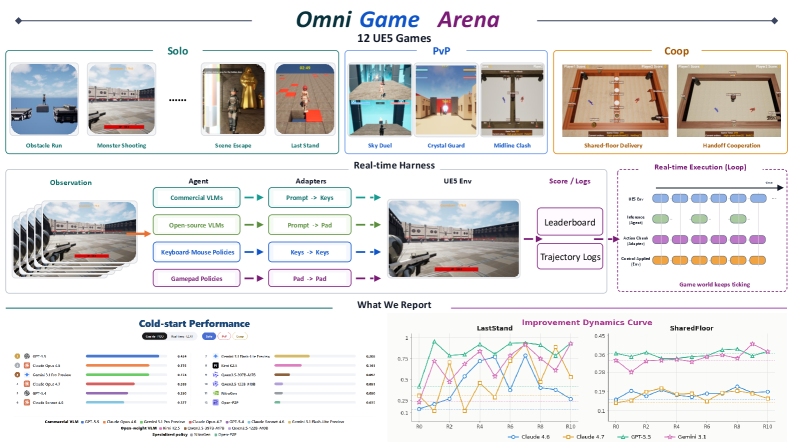
OmniGameArena is a real-time UE5 benchmark for VLM game agents
Twelve new games span Solo, PvP, and Coop with one shared interface.
The Improvement Dynamics Curve tracks how agents learn and improve across reflection rounds.
Happy to present that terminal tool calls will be in prettified markdown codeblocks now if you have display tool calls enabled in Hermes Agent.
Works on all platforms that support it.
This is my favorite dataset we've built.
Operational KPI data, unlike anything else on the market.
It tells you:
• load factor (airlines)
• book-to-bill (semiconductors)
• $100K customers (SaaS)
This data isn't in XBRL nor in a 10-K/Q.
Instead, it's buried in earnings releases, transcripts, IR websites, and news articles.
We pull it out and standardize it so your agent can run clean comps across a sector.
I use it so Claude Code doesn't burn tokens reading long earnings releases and articles.
It's updated in ~15s, served in milliseconds.
what is agent looping
for the last two years we prompted agents one task at a time. that is starting to change
instead of asking an agent to build the landing page and then driving every step yourself, you set up a loop that handles discovery, planning, the work, checking, and iterating until the goal is met
looping is a setup you build. almost any agent harness can run it, it just depends on how you wire it up
at its simplest, looping is one agent working on itself:
> researches
> drafts
> checks the draft against a goal
> fixes what is weak
> runs that cycle again until the work clears the requirements
you are not prompting each step anymore. the agent repeats the cycle for you
the bigger version is a fleet looping. you give an orchestrator agent a goal, it breaks the goal into pieces, hands each piece to a specialist agent, and those specialists hand smaller jobs to their own subagents
the whole tree keeps looping through discovery, planning, execution, and verification until the goal is met
one agent looping is like a person redoing their own draft. a fleet looping is a whole team running a project end-to-end
you create a goal, and the system runs the loop until it finishes within the reqs you set
open and closed looping:
OPEN LOOPING is exploratory. it still has conditions and a goal, but you give the agent or the fleet a wide space to move in. it can try different paths, discover things, build something you did not fully spec out
this is the exciting end, it is what Peter and others are doing, and tbh it is where I want to spend more time
the catch is cost, an open loop with real room to explore burns an insane amount of tokens. for the 90 percent of people without an unlimited budget it is not runnable yet, and pointed at projects with a loose standard it turns into a slop machine
CLOSED LOOPING is bounded. a human designs the end-to-end path first:
> clear goal
> defined steps
> an eval at each step
> a point where it stops or hands back to you (and feeds back performance data)
the agents still loop, but inside framework you built. it gets better every run because each pass feeds the next, and it runs on a normal budget because the path is tight.
for most marketing work, closed is the one that pays off today.
> the orchestrator owns the goal
> the specialists own the steps
> the subagents do the narrow work
> an eval gate make sure its not slop
HE HAS RETURNED TO OPEN SOURCE DEVELOPMENT LET'S FREAKING GOOOOO
https://t.co/y1jlQbJvsw
Great person to follow if you're looking for project inspo. He's always building fun stuff.
Stumbled upon a Codex skill that creates cool illustrations to explain topics or tell stories.
You feed it text (blog, article, narrative, even code) and it makes explainer graphics with this cute blob character.
I gave it the repo for the X recommendation algo and got this 👇
Build your own durable LLM Wiki for free.
No Docker volumes. No API keys. You don't even need to know what Obsidian is.
Sign in with ChatGPT or X, and jump into Agent Zero.
📎 Paperclip 2025.529.0 is out now
💬 Document annotations & comments
🧠 Skills CLI & catalog
👁🗨 Hide projects & agents from your sidebar
🔑 First-admin claim flow
🤖 Live Claude model discovery
https://t.co/xqrOzj9ROl