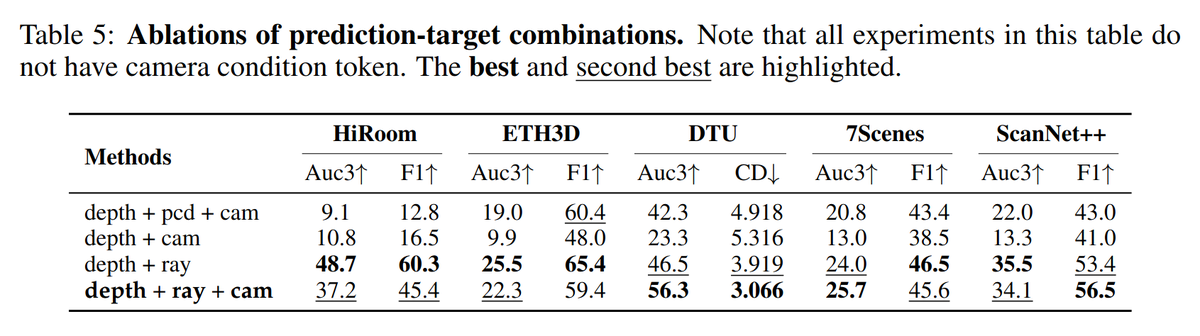
Could this be the ViT moment for 3D scene understanding? 🚀
We revisit the good old Transformer architecture and apply it to 3D scene understanding with minimal modifications. #Volt ⚡️
Project page: https://t.co/1HYyTrtdak
Arxiv link: https://t.co/imcuvM6j0X
(1/5)
Excited to share our new survey on 3D Reconstruction, accepted to IEEE T-PAMI! We cover everything from depth estimation and NeRF to 3DGS and 3D foundation models. If you're interested in 3D reconstruction, you won't want to miss this.https://t.co/g5UEitbb1N
#3D#ComputerVision
📢 New preprint! We introduce R3DPA - a LiDAR scene generator that:
• Transfers RGB-pretrained generative priors to 3D
• Aligns with self-supervised LiDAR features
• Enables object inpainting & scene mixing at inference
• Sets SOTA on KITTI-360
📣 UNITE: Unified Semantic Transformer for 3D Scene Understanding 📣
Given only a couple of images of a scene, UNITE jointly recovers:
✅ 3D Scene Geometry
✅ Semantic Segmentation ✅ Instance Segmentation
✅ Object Articulations
🚀 Project page: https://t.co/P7oln9sWjm
[NeurIPS 2025] SPIRAL: Semantic-Aware Progressive LiDAR Scene Generation and Understanding
https://t.co/heVdwCAs0s
Existing LiDAR generative models are limited to producing unlabeled LiDAR scenes, lacking any semantic annotations. Performing post-hoc labeling on these generated scenes requires additional pretrained segmentation models, which introduces extra computational overhead. Moreover, such after-the-fact annotation yields suboptimal segmentation quality.
To address this issue, we make the following contributions:
・We propose a novel state-of-the-art semantic-aware range-view LiDAR diffusion model, Spiral, which jointly produces depth and reflectance images along with semantic labels.
・We introduce unified evaluation metrics that comprehensively evaluate the geometric, physical, and semantic quality of generated labeled LiDAR scenes.
・We demonstrate the effectiveness of the generated LiDAR scenes for training segmentation models, highlighting Spiral's potential for generative data augmentation.
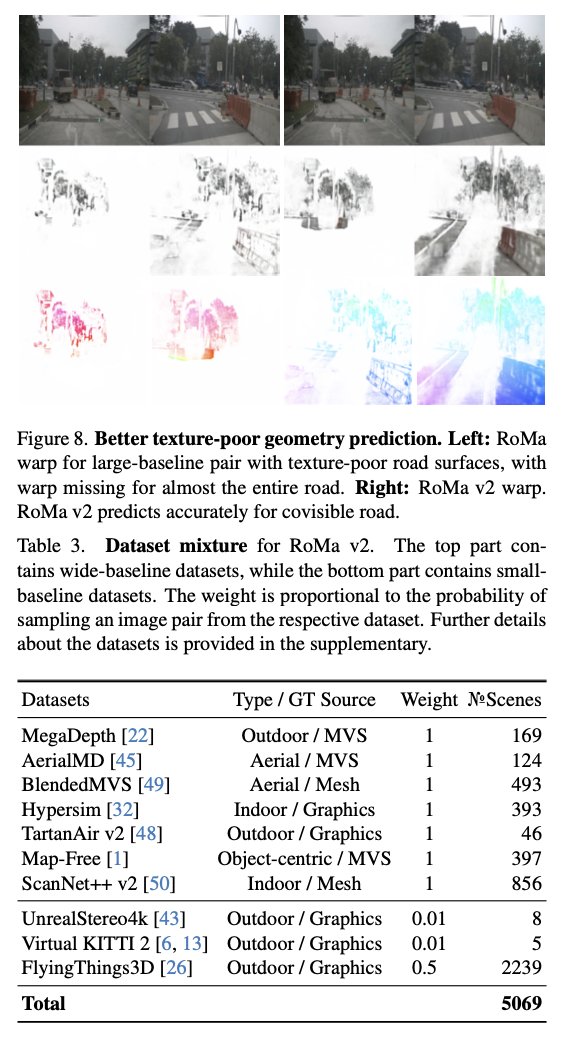
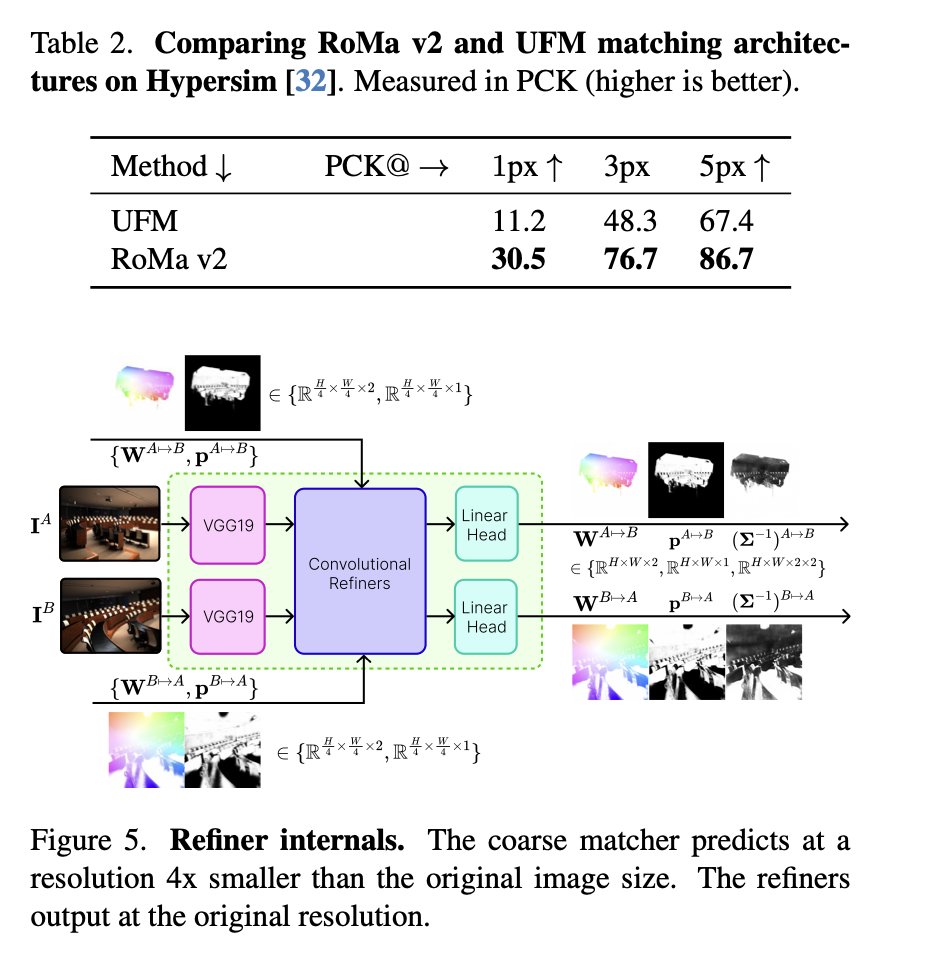
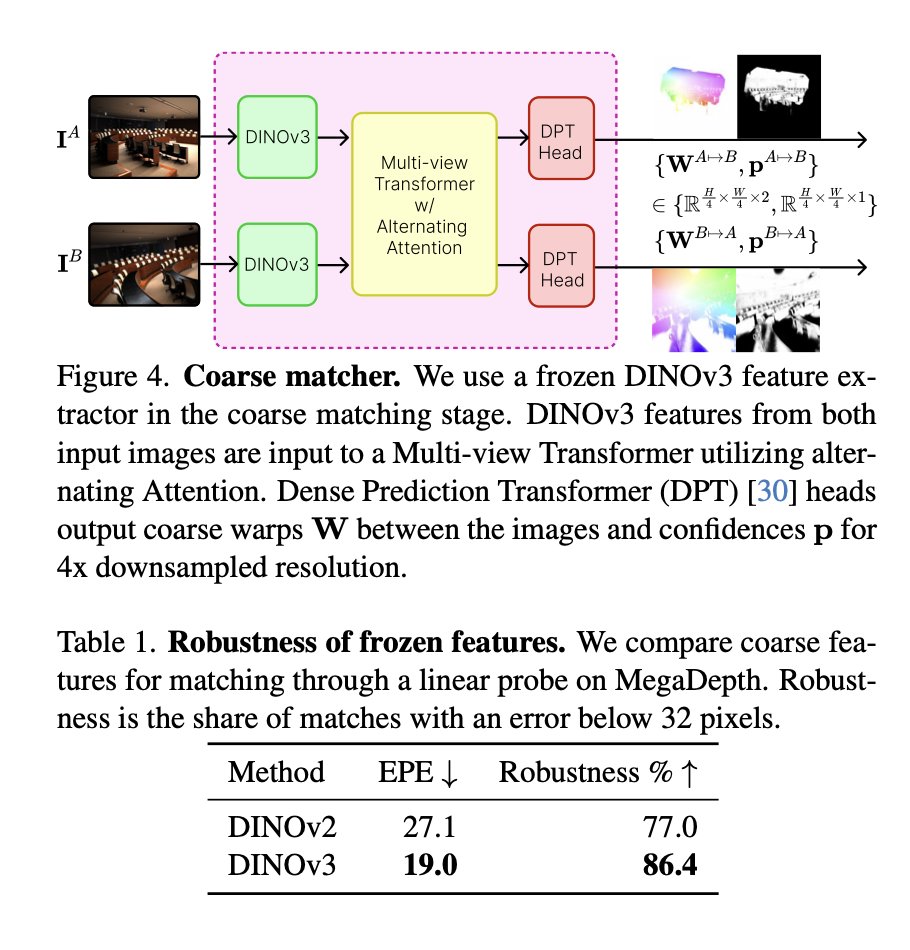
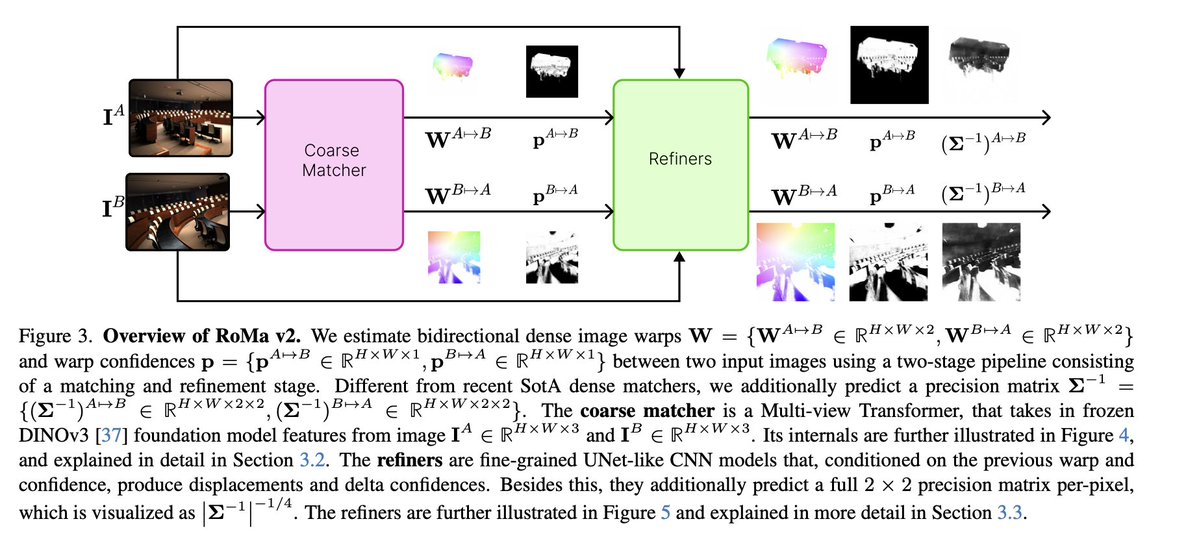
RoMa v2: Harder Better Faster Denser Feature Matching
@Parskatt et 11 al.
tl;dr: in title.
Predict covariance per-pixel, more datasets, use DINOv3, adjust architecture.
https://t.co/jLia5dKmFv
New thread - adding DepthAnything 3 - both best and Apache 2 models.
1) Graffiti
The best one is almost flat, smaller Apache2 model is very non-flat.
2)IMC-Church. Apache 2 pretty bad, big - not terrible, but not great either
1/
fantastic simple visualization of the self attention formula. this was one of the hardest things for me to deeply understand about LLMs.
the formula seems easy. you can even memorize it fast. but to really get an intuition of what the Q,K,V represent and interact, that’s hard.
MapAnything's evil sibling also supports flexible inputs but triples down on redundant outputs, estimating point maps, depths, and 3D Gaussians.
https://t.co/xGiuurUdXP
Is the terror reign of redundant scene representations ending? Where VGGT, CUT3R, and other recent models relied on godless redundant outputs (depth+points+pose) without guaranteeing internal prediction consistency, MapAnything and DepthAnything 3 are now heroically pushing back.
Gentlemen I need your full attention.
Python is introducing lazy imports.
I repeat.
Python is introducing lazy imports.
inb4 the flood of `treewide: adopt lazy imports` +123,244 PRs
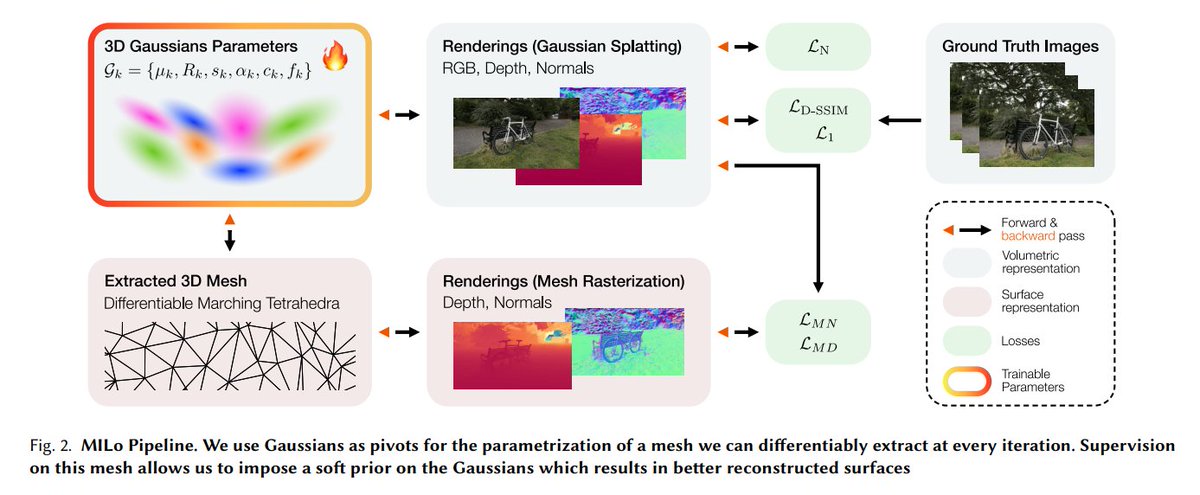
1/n🚀Gaussians > Differentiable function > Mesh?
Check out our new work: MILo: Mesh-In-the-Loop Gaussian Splatting!
🎉Accepted to SIGGRAPH Asia 2025 (TOG)
MILo is a novel differentiable framework that extracts meshes directly from Gaussian parameters during training.
🧵👇
GlobalBuildingAtlas' 2.75B Building Footprints are now on S3. 1.1 TB of uncompressed GeoJSON down to 210 GB of Parquet.
Download any city's buildings in seconds: https://t.co/TMxxEnDSPI
Say hello to DINOv3 🦖🦖🦖
A major release that raises the bar of self-supervised vision foundation models.
With stunning high-resolution dense features, it’s a game-changer for vision tasks!
We scaled model size and training data, but here's what makes it special 👇
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
MILo: Mesh-In-the-Loop Gaussian Splatting for Detailed and Efficient Surface Reconstruction
@antoine_guedon, Diego Gomez, Nissim Maruani, Bingchen Gong, @GDrettakis, Maks Ovsjanikov
tl;dr: generate a mesh at every training iteration from a set of points entangled with the Gaussians, Gaussian Pivots
https://t.co/9b9usojzZp


































![rsasaki0109's tweet photo. [NeurIPS 2025] SPIRAL: Semantic-Aware Progressive LiDAR Scene Generation and Understanding
https://t.co/heVdwCAs0s
Existing LiDAR generative models are limited to producing unlabeled LiDAR scenes, lacking any semantic annotations. Performing post-hoc labeling on these generated scenes requires additional pretrained segmentation models, which introduces extra computational overhead. Moreover, such after-the-fact annotation yields suboptimal segmentation quality.
To address this issue, we make the following contributions:
・We propose a novel state-of-the-art semantic-aware range-view LiDAR diffusion model, Spiral, which jointly produces depth and reflectance images along with semantic labels.
・We introduce unified evaluation metrics that comprehensively evaluate the geometric, physical, and semantic quality of generated labeled LiDAR scenes.
・We demonstrate the effectiveness of the generated LiDAR scenes for training segmentation models, highlighting Spiral's potential for generative data augmentation.](https://pbs.twimg.com/media/G77gItZbcAAcUQK.jpg)