Multilingual AI doesn’t fail on language alone. It fails on cultural context.
Even state-of-the-art systems still struggle with dialects, idioms, tone, and regional nuance when trained on narrow datasets.
In his latest @Forbes Technology Council article, Appen CEO Ryan Kolln @kolln_ryan000 breaks down why culturally adaptive AI requires:
• Representative, context-rich data
• Native-speaker human evaluation
• Localization beyond literal translation
One example highlighted: expanding an LLM deployment from 10 dialects across 5 languages to 70+ dialects across 30 languages through structured native-speaker feedback loops.
For multilingual AI, accuracy is not only linguistic. It’s cultural.
Link: https://t.co/kPpV9bTttD
#AI #LLM #MultilingualAI #MachineLearning #GenerativeAI #AISafety #Localization
At @slatornews SlatorCon London 2026, Sergio Bruccoleri, VP, Delivery at @AppenResearch, spoke about how the role of human expertise in AI is evolving as models become more capable.
A few key themes from the discussion:
• Evaluation is moving beyond static benchmarks toward more dynamic, environment-based assessment
• Domains like coding, STEM, legal, and finance increasingly require subject matter experts to evaluate reasoning quality and edge cases
• As agentic systems mature, high-quality human feedback becomes critical for alignment, reliability, and production readiness
Good conversations with researchers and leaders across the language AI ecosystem on where training and evaluation are headed next.
#AI #LLM #MachineLearning #AISafety #LanguageAI
We've partnered with Appen to evaluate the benchmarks we published last week.
Results are in and we've actually improved across the board.
Link below to the full report.
@AppenResearch independently evaluated @subquadratic's SSA kernel - a learned sparse attention mechanism designed to reduce the quadratic scaling limitations of full attention.
Results at 1M-token context lengths:
- 56.2× wall clock speedup vs. FA2
- 62.8× FLOP reduction (validated via torch.profiler, <4% variance from theoretical)
- 95.6% average score across RULER tasks at 128K
- 86.2% average score on the hardest MRCR 8-needle bucket (512K–1M contexts)
- 81.8% SWE-Bench Verified resolved rate
Full report: https://t.co/9OpvaqDPbt
"Benchmaxxing" is quietly breaking ASR evaluation.
Models tuned to climb public leaderboards don't generalise to real speech; they're optimised for the test, not the task.
Our new whitepaper covers how to build benchmarks that are actually production-representative (and benchmaxxing-resistant).
https://t.co/X3Aavqpep3
#ASR #SpeechAI #MachineLearning
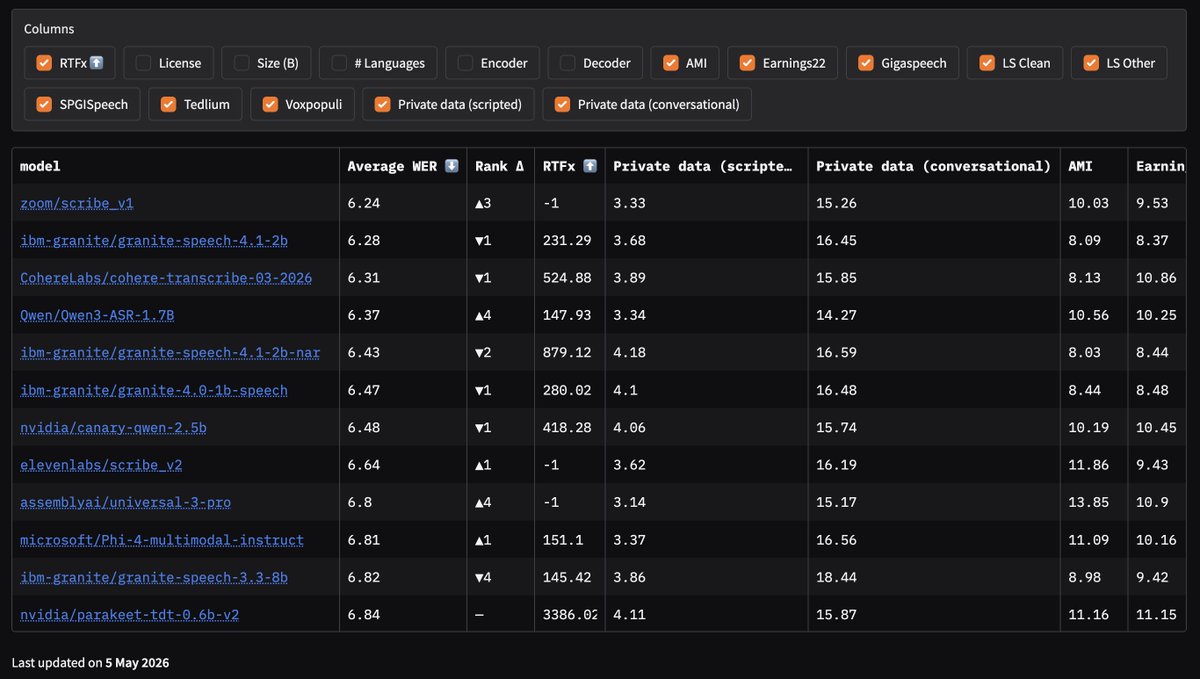
ASR leaderboards are being gamed. We partnered with @huggingface to add private benchmark data to the Open ASR Leaderboard - held back from developers so rankings reflect real-world performance. 🔒
https://t.co/aZuLlyjwNm