Deterministic AST engine for AI coding agents. We map codebase architecture into a local Rust graph so your LLM stops guessing. Sub-ms latency. Zero token burn.
@CodeByPoonam AI writes most of your code now.
The hard part isn't writing it anymore — it's knowing if it's any good. Is it safe? Is it slop? Does it even do what it claims?
ArgosBrain reads your codebase and proves, line by line, what the AI actually built.
Uber's CTO confirmed publicly: Entire 2026 AI budget burned in 4 months That's a $85–114M annual run-rate on Claude Code alone. Anthropic's own /context data: 73% of a Claude Code bill is the agent re-reading code it already read. ArgosBrain replaces that with a sub-millisecond graph lookup. 0 tokens per query. Reduces ~70% of the repo-re-read chunk. Math: $43–83M/year ArgosBrain would have eliminated from Uber's bill. Same agents. Same code output. Smaller invoice. https://t.co/yL2X3i8YfF — Aurelian Jibleanu
Do you know how hard is for a model to breach 90% on SWE verified benchmark? This is not about: use a model because has a higher % on benchmark...is about a model that is already incredible good on coding, becoming even better with our engine...this is what I am trying to prove...If you don't trust benchmarks to filter your first choice to test...it means you just have a lot of time trying all sort of other coding tools...
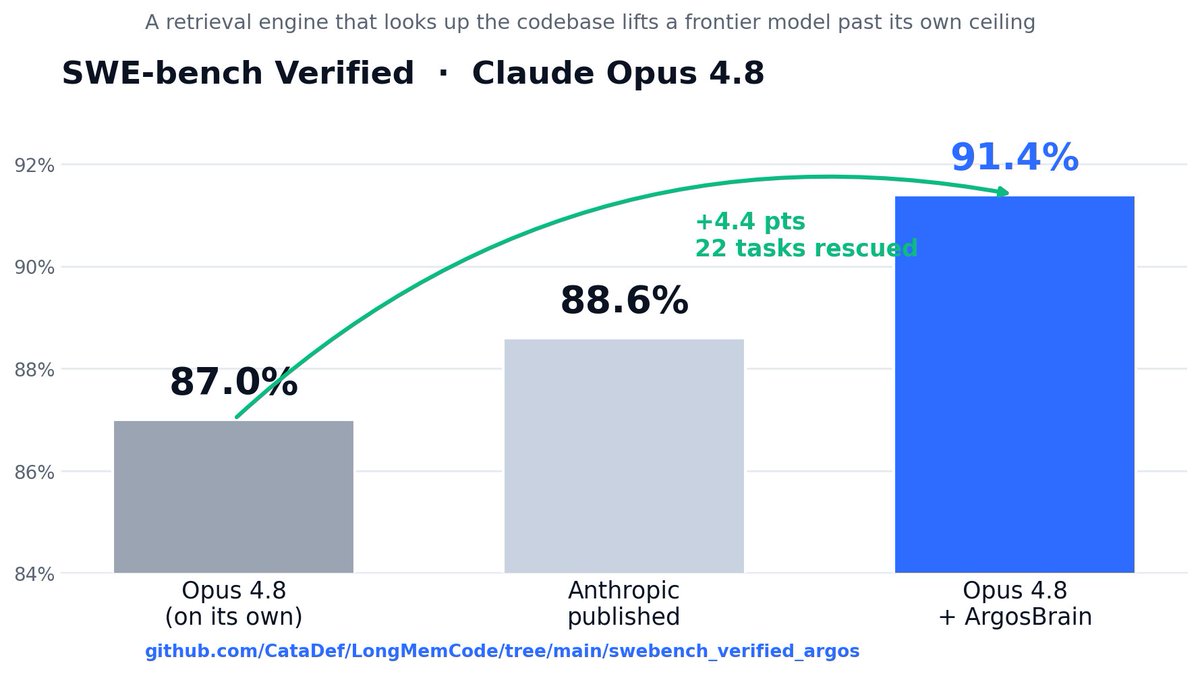
Make it better: Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer
What's the eval substrate underneath?
Routing decisions need deterministic ground truth. For coding agents, that's structural — call graphs, data flows, reachability — answerable by graph traversal at $0, not by any LLM tier.
Paradox: a deterministic substrate cuts LLM usage AND makes the remaining calls smarter. Opus 4.8 jumped 87% → 91.4% on SWE-bench Verified using ArgosBrain as the retrieval layer. Fewer calls. Better
outputs. Same model.(https://t.co/ipqFPVdxer)
The eval layer doubles as the cheapest production tier. Same substrate,
both roles.
Curious if Box is routing to non-model substrates yet.
@ArgosBrain
EU founder here. We hit:
— GDPR-native by architecture (engine literally cannot send source
off-network)
— AI Act compliance is the wedge, not the distraction
— Past 5pm right now
— Croissants box checked
ArgosBrain — deterministic Search-as-Code substrate. Opus 4.8 went from
87% → 91.4% on SWE-bench Verified using it as the retrieval layer.
https://t.co/yL2X3i8YfF
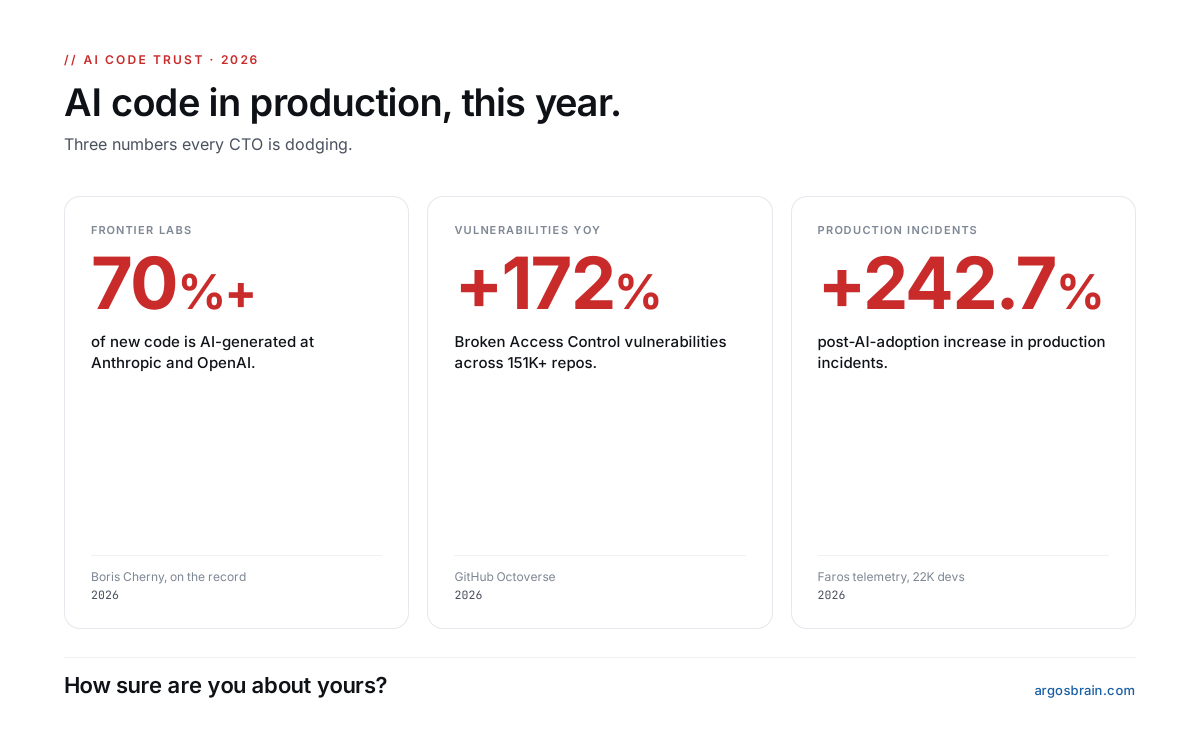
The most uncomfortable question for every CTO in 2026:
"How sure are you about the code your AI agents just shipped?"
70% of frontier-lab code is AI-generated (Anthropic, OpenAI, on record).
Broken Access Control vulns: +172% YoY.
Production incidents: +242.7% post-AI-adoption.
A thread on what nobody is verifying.
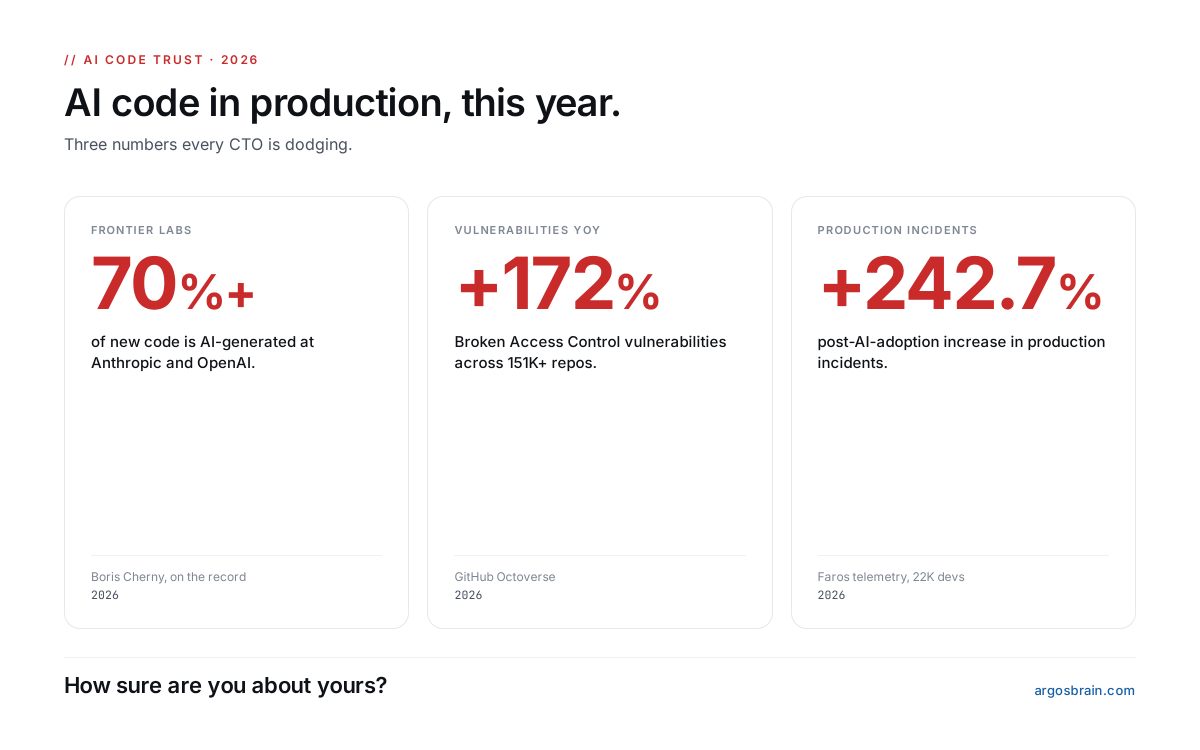
The most uncomfortable question for every CTO in 2026:
"How sure are you about the code your AI agents just shipped?"
70% of frontier-lab code is AI-generated (Anthropic, OpenAI, on record).
Broken Access Control vulns: +172% YoY.
Production incidents: +242.7% post-AI-adoption.
A thread on what nobody is verifying.
Three questions every CTO should be able to answer in 2 minutes,
file:line:
1. Where do PII fields flow through my codebase?
2. Which SSRF/SQLi/auth-bypass sinks are reachable from untrusted input?
3. Did my AI agent's new handler traverse the rate limiter?
Most teams can't answer in 2 days.
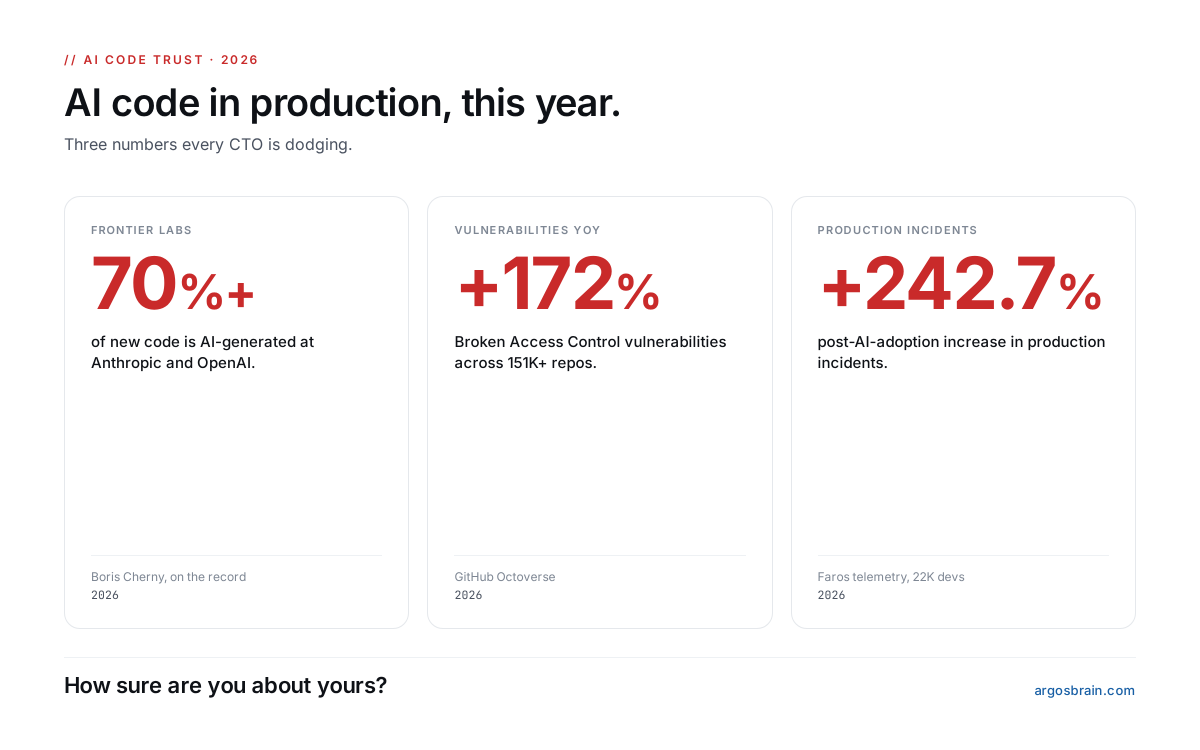
The most uncomfortable question for every CTO in 2026:
"How sure are you about the code your AI agents just shipped?"
70% of frontier-lab code is AI-generated (Anthropic, OpenAI, on record). Broken Access Control vulns: +172% YoY.
Production incidents: +242.7% post-AI-adoption.
A thread on what nobody is verifying.
Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer
Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer
Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer
Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer
@lottsnomad IS YOUR AI CODE SAFE?"
ArgosBrain walks your entire codebase end-to-end — finding every error, every security threat, every place customer data flows — and gives you a signed, verifiable report.
@nico_laqua@lottsnomad Why don’t you give a try to ArgosBrain. Is designed to cover Ai code security, slop…
ArgosBrain reads your codebase and proves, line by line, what the AI actually built.
(Same engine took Claude Opus 4.8 to 91.4% on SWE-bench Verified.)
https://t.co/Qf6Eh0SUkd
AI writes most of your code now.
The hard part isn't writing it anymore — it's knowing if it's any good. Is it safe? Is it slop? Does it even do what it claims?
ArgosBrain reads your codebase and proves, line by line, what the AI actually built.
(Same engine took Claude Opus 4.8 to 91.4% on SWE-bench Verified.)
https://t.co/ipqFPVdxer
AI writes most of your code now.
The hard part isn't writing it anymore — it's knowing if it's any good. Is it safe? Is it slop? Does it even do what it claims?
ArgosBrain reads your codebase and proves, line by line, what the AI actually built.
(Same engine took Claude Opus 4.8 to 91.4% on SWE-bench Verified.)
https://t.co/ipqFPVdxer
"Search as Code" — same pattern needed for codebases.
AI coding agents currently loop: grep → read file → grep → read file →
grep. Token burn + hallucination.
Deterministic graph primitives, composed in the agent harness:
— who_calls(symbol)
— reachability(entry, sink)
— data_flow(field)
— file:line cited
Same insight, code domain. https://t.co/yL2X3i8YfF
Is is better?:
Claude Opus 4.8 scores ~87% on SWE-bench Verified — 500 real-world bugs from open-source projects, each graded by hidden tests. Going higher is brutal.
We connected it to ArgosBrain — an engine that instantly looks up any codebase and gives the model exact answers — and pushed it to 91.4%.
22 hard tasks it failed alone. Now solved. 👇
https://t.co/ipqFPVdxer